
7 查看是否修改成功
8 ceph daemon /var/run/ceph/ceph-mon.hx-tstack-mon02.asok config show | grep mon_data_size_warn
9 //ceph mon节点均需要执行以上步骤
ceph慢请求可能的原因
1.网络问题
存储网络延时、丢包等现象造成IO慢请求
2.磁盘坏盘
osd磁盘存在超级块IO Error
3.定时快照
存在很多的云硬盘做了定时快照,会导致客户端请求增加。导致正常的IO速率降低。
定位pg-object-osd-卷
13 requests are blocked >32 sec
出现该问题的可能是因为在数据迁移过程中,用户正在对该数据块进行访问(ops),但访问还没有完成,数据就迁移到了别的OSD中,那么会导致有请求被block,对于用户侧的现象是读写慢,告警有慢请求等
处理方法:
查询block的请求落在那个OSD,对该osd执行重启操作,系统会断开请求,执行该osd的recovery的操作,recovery过程中,会断开block request,那么这个request 将会重新请求mon节点,并重新获得新的pg map,得到最新的数据访问位置,
从而解决block的问题。
1 ceph health detail|grep block
2 systemctl restart ceph-osd@ID.service
机房断电导致osd没有激活
手动激活所有osd
1 ceph-disk activate-all #ceph集群会自动执行in操作并激活osd。
2 ceph-volume lvm activate --all #激活所有osd
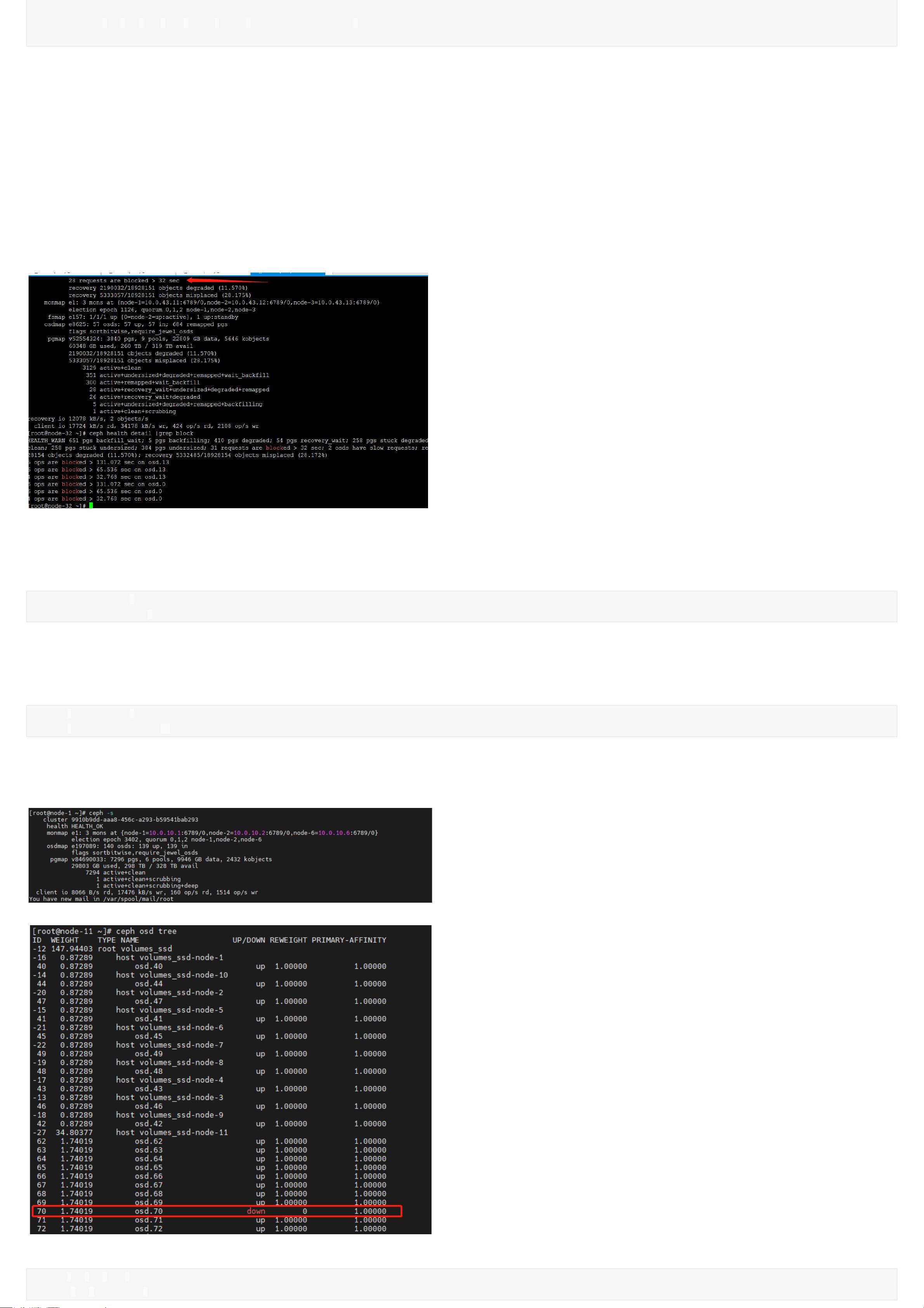
磁盘有坏盘
ceph osd tree 看到osd.70状态为down ,rewight 权重为0
从moni节点查看日志并没有显示告警时间段osd.70的相关信息
1 cd /var/log/ceph/
2 grep -nR -C40 "down" *
剩余14页未读,继续阅读















