Java并发包深入解析:ConcurrentHashMap源码探秘
170 浏览量
更新于2024-09-01
1
收藏 284KB PDF 举报
"深入学习java并发包ConcurrentHashMap,分析其源码,了解其Segment分段锁机制,以及并发级别的概念和初始化参数设定"
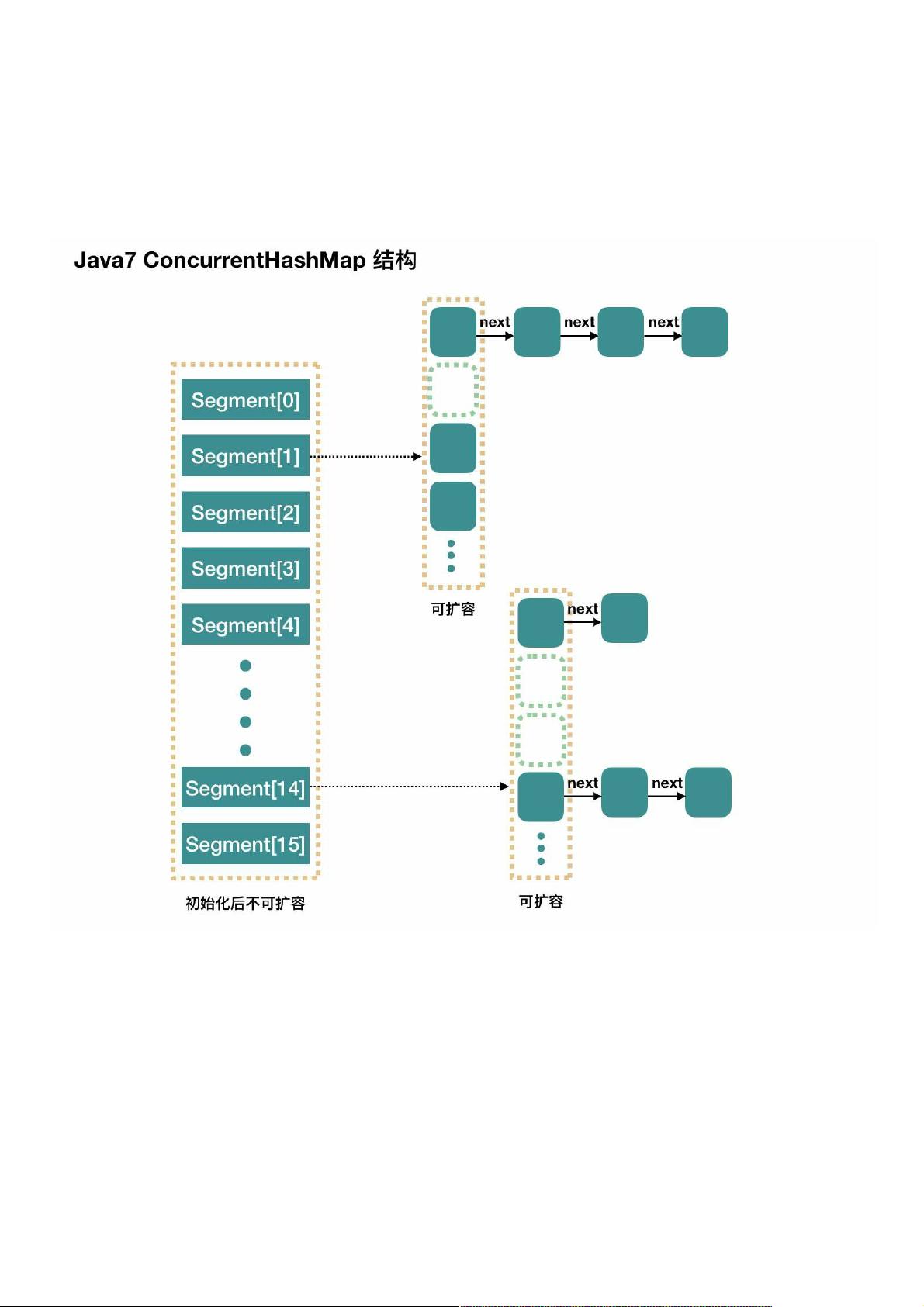
在Java并发编程中,`ConcurrentHashMap`是一个非常重要的数据结构,它是线程安全的HashMap实现。与普通的HashMap不同,`ConcurrentHashMap`在JDK 1.7版本中的设计采用了分段锁(Segment)的概念,以提高并发性能。
首先,`ConcurrentHashMap`不是在整个容器上进行全局锁,而是将整个数据结构分割成多个独立的`Segment`,每个`Segment`类似于一个小型的HashMap。`Segment`类继承自`ReentrantLock`,因此每个`Segment`都有自己的锁机制。这意味着当多个线程尝试同时修改`ConcurrentHashMap`时,每个线程只需要锁定它要操作的特定`Segment`,而不是整个数据结构。这种设计使得多个线程可以在不同`Segment`上并发地执行写操作,从而提高了并发性能。
`ConcurrentHashMap`的几个关键参数包括:
1. `concurrencyLevel`:并行级别,也就是`Segment`的数量。默认为16,意味着最多16个线程可以并发地对不同的`Segment`进行写操作。这个值在创建`ConcurrentHashMap`时可以指定,一旦设定后不可更改。
2. `initialCapacity`:初始容量,这是整个`ConcurrentHashMap`的初始大小,创建时会根据这个值和`Segment`数量平均分配给各个`Segment`。
3. `loadFactor`:负载因子,同样适用于每个`Segment`。当`Segment`内的元素数量达到这个负载因子与`Segment`容量的乘积时,`Segment`内部会进行扩容,但是请注意,`Segment`数组本身不会扩容。
每个`Segment`内部的工作原理与HashMap类似,采用链表和数组相结合的方式存储元素,处理冲突时会将相同哈希值的元素链接在一起形成链表。由于`Segment`内部的加锁机制,`ConcurrentHashMap`能够在多线程环境下保证数据一致性,同时提供较高的并发性能。
在`ConcurrentHashMap`的初始化过程中,会根据提供的`initialCapacity`和`concurrencyLevel`计算每个`Segment`的初始容量。如果`initialCapacity`不足以均匀分配给所有`Segment`,则会向上取整到下一个能被`concurrencyLevel`整除的值,以确保每个`Segment`至少有一个元素。
在JDK 1.8之后,`ConcurrentHashMap`的实现进一步优化,去掉了`Segment`的概念,转而使用 CAS(Compare and Swap)和分段锁的混合策略,进一步提升了并发性能和内存效率。但是,对于理解`ConcurrentHashMap`的设计思路和并发处理的基本原理,学习1.7版本的实现仍然十分有价值。
深入学习深入学习java并发包并发包ConcurrentHashMap源码源码
主要介绍了深入学习java并发包ConcurrentHashMap源码,整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述
为分段锁。,需要的朋友可以参考下
正文正文
以前写过介绍HashMap的文章,文中提到过HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容
数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
JDK1.7的实现的实现
整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个 segment。
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全
的,也就实现了全局的线程安全。
concurrencyLevel:并行级别、并发数、Segment 数。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分
别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
初始化初始化
initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
loadFactor:负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
// 计算并行级别 ssize,因为要保持并行级别是 2 的 n 次方
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 我们这里先不要那么烧脑,用默认值,concurrencyLevel 为 16,sshift 为 4
// 那么计算出 segmentShift 为 28,segmentMask 为 15,后面会用到这两个值
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// initialCapacity 是设置整个 map 初始的大小,
// 这里根据 initialCapacity 计算 Segment 数组中每个位置可以分到的大小
// 如 initialCapacity 为 64,那么每个 Segment 或称之为"槽"可以分到 4 个
下载后可阅读完整内容,剩余4页未读,立即下载
2021-06-13 上传
2018-07-05 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-03-23 上传
2021-02-12 上传
2010-03-17 上传
2021-03-23 上传

weixin_38502290
- 粉丝: 5
- 资源: 963
 我的内容管理
展开
我的内容管理
展开







最新资源
- ICCAVR使用说明
- swis学习手记而为热微微额头 而特玩儿玩儿为认为而为而
- DB2数据库函数大全
- 图书馆管理系统说明书
- C语言教程 推荐学生下载
- NiosII软件开发手册(中文版)
- VC++数据库编程(电子书pdf)
- 数码管动态显示数码管动态显示数码管动态显示
- struct学习struct配置
- 什么是A S P Microsoft Active Server Pages (ASP)
- Visual C++ - OpenGL Super Bible
- 日历记事本java编程
- Linux基础命令(基于VOIP).
- Quintum网关基本配置
- 日历记事本java编程
- 使用JSF, Spring, Hibernate构建一个实际的web
