YOLO训练自定义数据集教程:迁移学习与预训练权重使用
需积分: 0 80 浏览量
更新于2024-08-04
收藏 267KB DOCX 举报
"该资源主要涉及使用PyTorch框架训练自定义数据集的过程,特别是针对YOLO模型的训练。文章提到了预训练权重的使用、数据集格式的要求以及迁移学习的应用。"
在训练自定义数据集时,首先要理解的是如何处理预训练权重。YOLO模型的训练通常涉及到预训练权重,这些权重是在大型数据集如COCO上训练得到的,包含了80个类别。如果你的数据集类别与COCO不同,但部分类别重合,如PASCAL VOC的20个类别,你可以使用COCO的预训练权重进行迁移学习。不过,要注意的是,预训练权重的最后三层与类别数量有关,因为它们对应的是每个网格单元预测的类别概率。因此,如果你的类别数不同,只需调整最后的这些层,其余网络结构可以保持不变。
在实际操作中,需要对`yolo.py`文件进行适当修改,确保预测时指向正确的类别列表,如将`coco_classes.txt`替换为`voc_classes.txt`。如果只想预测VOC数据集的类别,可以在代码中添加类别判定条件。
在使用预训练权重时,确保你的数据集标签符合VOC格式,即XML文件。图片应为jpg格式,因为PNG或其他格式可能需要转换。你可以使用工具如`labelimg`来创建和编辑这些标签,同时可以编写Python脚本来批量将PNG转换为jpg。
在开始训练前,你需要清理之前可能存在的旧权重和日志,例如删除`logs`文件夹下的内容,以及`VOCdevkit/VOC2007/ImageSets/Main`文件夹下的训练和验证列表文件。另外,清除`map_out`文件夹以避免保留上一次的测试结果。
在数据集准备阶段,你需要将图片和对应的XML标签文件分别放入`VOCdevkit\VOC2007`下的`JPEGImages`和`Annotations`文件夹。此外,在`model_data`文件夹下创建一个包含你数据集中类别名称的txt文件,例如`my_classes.txt`,类别的顺序应与网络中设置的顺序一致。
最后,你可能需要修改一些辅助脚本,例如`voc_anotations.py`,以便处理数据集的读取和预处理,使其适应YOLO模型的输入要求。这个文件通常用于将VOC格式的XML标签转换成模型训练所需的格式。
训练自定义数据集的关键步骤包括:调整预训练权重以适应类别差异,确保数据集格式正确,清理旧训练记录,创建并组织新的数据集目录结构,以及根据需要修改脚本以处理新数据集的特性。在PyTorch中,利用预训练权重和迁移学习可以帮助加速模型收敛,并提高在新数据集上的性能。
yolo.py 这个文件是与训练完之后进行预测用的,与训练过程无关。于是当下载了代码和
预训练权重之后,由于预训练权重是在 coco 数据集上训练出来的,于是 yolo.py 里面的
所要去预测的类别的 txt 文件只能指向 coco_classes.txt。虽然 voc 数据集(20 个类)里
面的类在 coco 数据集(80 个类)里面都有,但是如果修改为 voc_classes.txt 就会报错。
载入预训练权重可以预测 voc 里面没有但是 coco 里有的类,比如 umbrella。(如果只想
预测 voc 里面的类,请在代码里面修改,加上类别判定条件即可。)
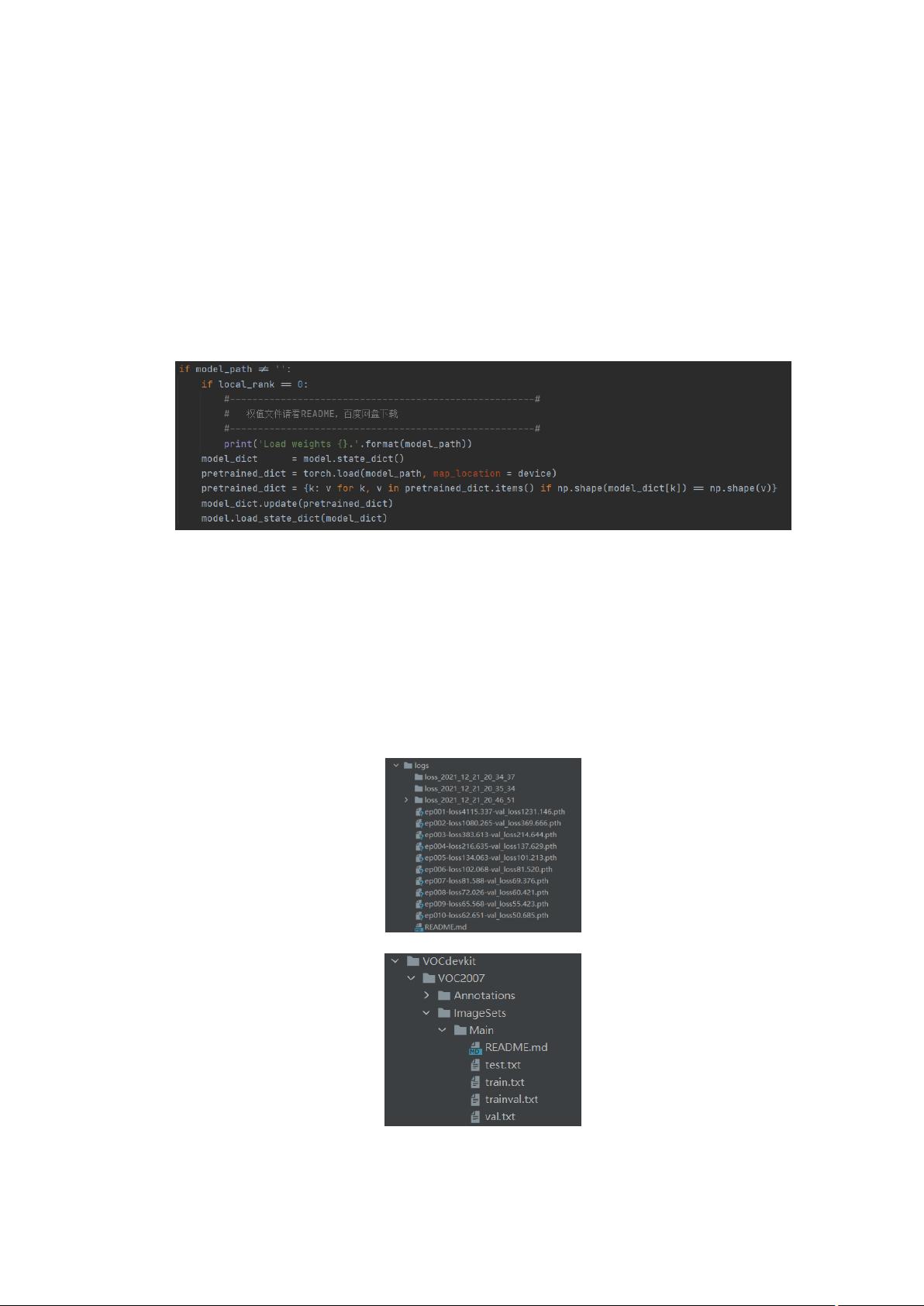
关于使用预训练权重,比如使用 coco 训练出来的 YOLO 权重,coco 有 80 各类,而自己
的数据集不是 80 各类,其实只有最后输出的三个特征图在通道数上有区别,其他任何
地方都没有区别,所以加载的时候可以通过下面的代码加载匹配的权重:
所以,如果采用迁移学习去训练的话,不管是自己的数据集还是 voc2007+2012 数据集,
首先下载代码与预训练权重(注:如果修改了网络结构的话就没办法用预训练权重
了),参照以下步骤:
(前提要求:标签必须是 VOC 格式的,即 XML 文件。图片必须是 jpg 格式的。Coco 数
据集是 json 格式的标签,可以用程序转成 voc 格式。其他格式的图片也能转为 jpg 格式)
1. 首先删除一些东西:
(1)logs 文件夹下所有权重和日志文件
(2)VOCdevkit/VOC2007/ImageSets/Main 文件夹下的四个 txt 文件
(3)2007_train.txt 和 2007_val.txt 文件
下载后可阅读完整内容,剩余5页未读,立即下载
2023-05-09 上传
2022-04-14 上传
2022-04-05 上传
2023-05-13 上传
2023-04-27 上传
2023-11-01 上传
2023-03-08 上传
2023-09-05 上传
2023-09-08 上传

StoneChan
- 粉丝: 31
- 资源: 321
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
