Python数据挖掘:LogisticRegression分析鸢尾花实战
需积分: 0 73 浏览量
更新于2024-08-05
1
收藏 1.98MB PDF 举报
"这篇教程是关于使用Python的LogisticRegression进行逻辑回归分析,以处理鸢尾花数据集。作者Eastmount介绍了非线性数据处理的重要性,并提到了之前讲解的线性回归作为背景。"
在机器学习领域,逻辑回归(Logistic Regression)是一种广泛使用的分类方法,尤其适用于二分类问题。它虽然名字中含有“回归”,但实际上是一种判别模型,用于预测事件发生的概率。在本教程中,Eastmount将LogisticRegression应用到了鸢尾花数据集上,这个数据集包含三种不同种类的鸢尾花,每种花都有四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度,非常适合用于演示分类算法。
首先,理解鸢尾花数据集:这个数据集由生物学家收集,用于研究鸢尾花的种类多样性。其中包含了150个样本,每个样本有4个数值型特征和1个类别标签。数据集的结构使得它成为教学和实验的理想选择,因为它具有清晰的类别划分和足够的样本数量。
然后,散点图的绘制在数据预处理和模型理解中起着关键作用。通过散点图,我们可以可视化两个特征之间的关系,帮助识别潜在的模式或者发现异常值。在分析鸢尾花数据时,可能会创建多组散点图,如花萼长度对花瓣长度,或者花萼宽度对花瓣宽度的图,以便观察不同种类鸢尾花在这些特征上的分布情况。
在Python中,我们可以使用sklearn库的LogisticRegression模型进行逻辑回归分析。首先需要对数据进行预处理,包括数据清洗、缺失值处理、标准化或归一化等步骤。然后,将数据划分为训练集和测试集,训练模型,并用测试集评估模型的性能。sklearn库的fit()函数用于拟合模型,predict()函数用于做出预测,而score()函数则可以计算模型的准确率。
在逻辑回归中,模型的预测结果是一个介于0和1之间的概率值,代表了某个类别出现的可能性。通过设定阈值(例如0.5),我们可以将这些概率转换为二进制类别标签。此外,逻辑回归还可以提供系数,这些系数反映了各个特征对分类结果的影响程度。
本教程中,作者可能还讨论了模型的评估指标,如准确率、精确率、召回率和F1分数,以及如何使用交叉验证来评估模型的稳定性和泛化能力。另外,可能还会涉及逻辑回归的正则化技术,如L1和L2正则化,它们可以帮助防止过拟合,提高模型的泛化性能。
这篇教程深入浅出地介绍了如何使用Python和sklearn库进行逻辑回归分析,结合鸢尾花数据集展示了分类任务的实际操作流程。对于初学者,这是一个很好的起点,能够理解逻辑回归的基本概念和实际应用。同时,对于有一定经验的开发者,也可以从中复习和巩固理论知识。
一. 逻辑回归
在前面讲述的回归模型中,处理的因变量都是数值型区间变量,建立的模型描述是因变量
的期望与自变量之间的线性关系。比如常见的线性回归模型:
而在采用回归模型分析实际问题中,所研究的变量往往不全是区间变量而是顺序变量或属
性变量,比如二项分布问题。通过分析年龄、性别、体质指数、平均血压、疾病指数等指
标,判断一个人是否换糖尿病,Y=0表示未患病,Y=1表示患病,这里的响应变量是一个
两点(0-1)分布变量,它就不能用h函数连续的值来预测因变量Y(只能取0或1)。
总之,线性回归模型通常是处理因变量是连续变量的问题,如果因变量是定性变量,线性
回归模型就不再适用了,需采用逻辑回归模型解决。
逻辑回归(Logistic Regression
)
是用于处理因变量为分类变量的回归问题,常见的是二
分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
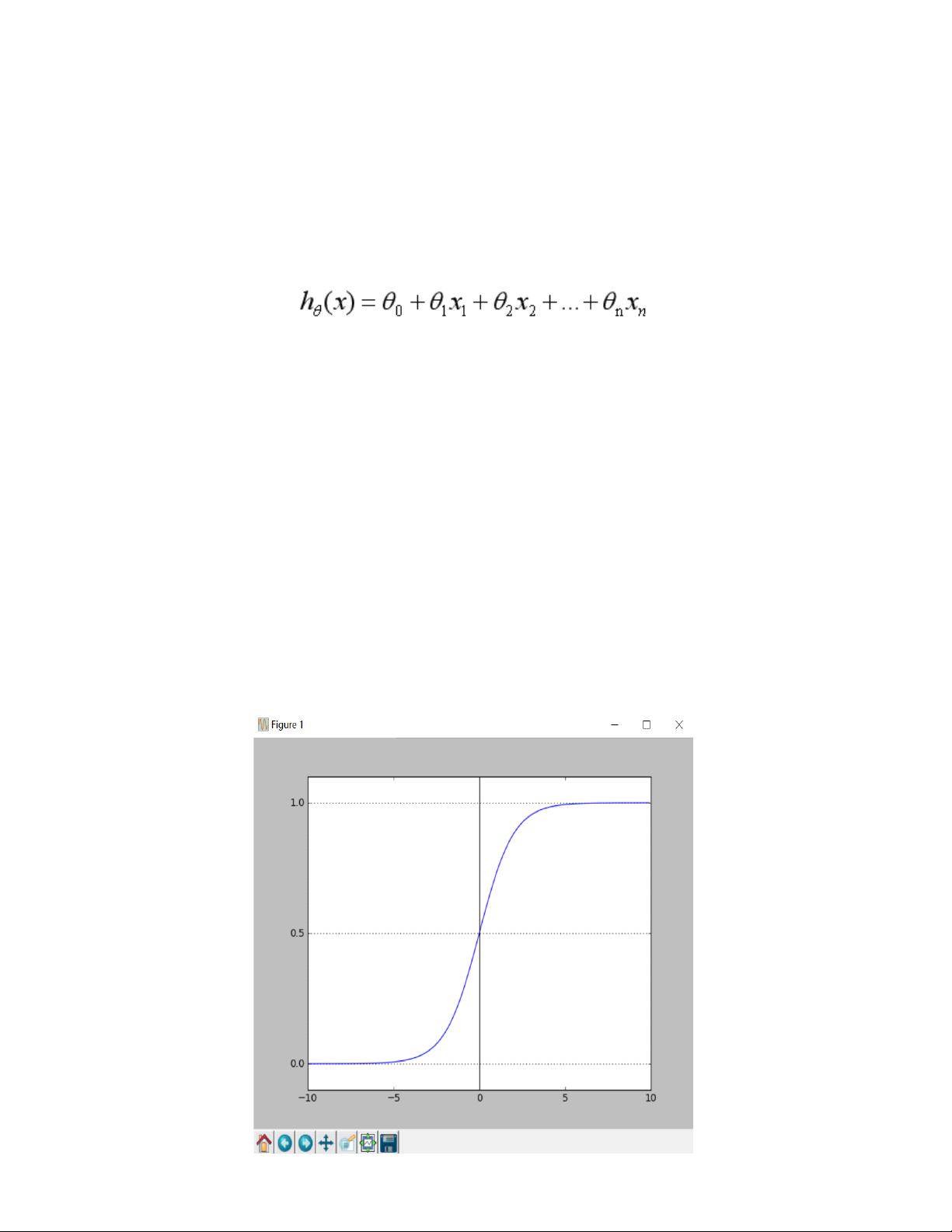
二分类问题的概率与自变量之间的关系图形往往是一个
S
型曲线,如图
所示,采用的
Sigmoid
函数实现。
第3页 共13页
剩余12页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-06 上传
2024-09-27 上传
2023-06-01 上传
2024-03-29 上传
2024-11-14 上传
2023-06-01 上传

华亿
- 粉丝: 51
- 资源: 308
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
