
However, the representation of yyyy
i
in the dictionary YYYY is not
unique in general. This comes from the fact that the number
of data points in a subspace is often greater than its
dimension, i.e., N
‘
>d
‘
. As a result, each YYYY
‘
, and conse-
quently YYYY , has a nontrivial nullspace, giving rise to
infinitely many representations of each data point.
The key observation in our proposed algorithm is that
among all solutions of (2),
there exists a sparse solution, cccc
i
, whose nonzero entries correspond
to data points from the same subspace as yyyy
i
. We refer to such a
solution as a subspace-sparse representation.
More specifi cally, a data point yyyy
i
that lies in the
d
‘
-dimensional subspace S
‘
can be written as a linear
combination of d
‘
other points in general directions from S
‘
.
As a result, ideally, a sparse representation of a data point
finds points from the same subspace where the number of
the nonzero elements corresponds to the dimension of the
underlying subspace.
For a system of equations such as (2) with infinitely
many solutions, one can restrict the set of solutions by
minimizing an objective function such as the ‘
q
-norm of the
solution
1
as
minkcccc
i
k
q
s:t:yyyy
i
¼ YYYYcccc
i
;c
ii
¼ 0: ð3Þ
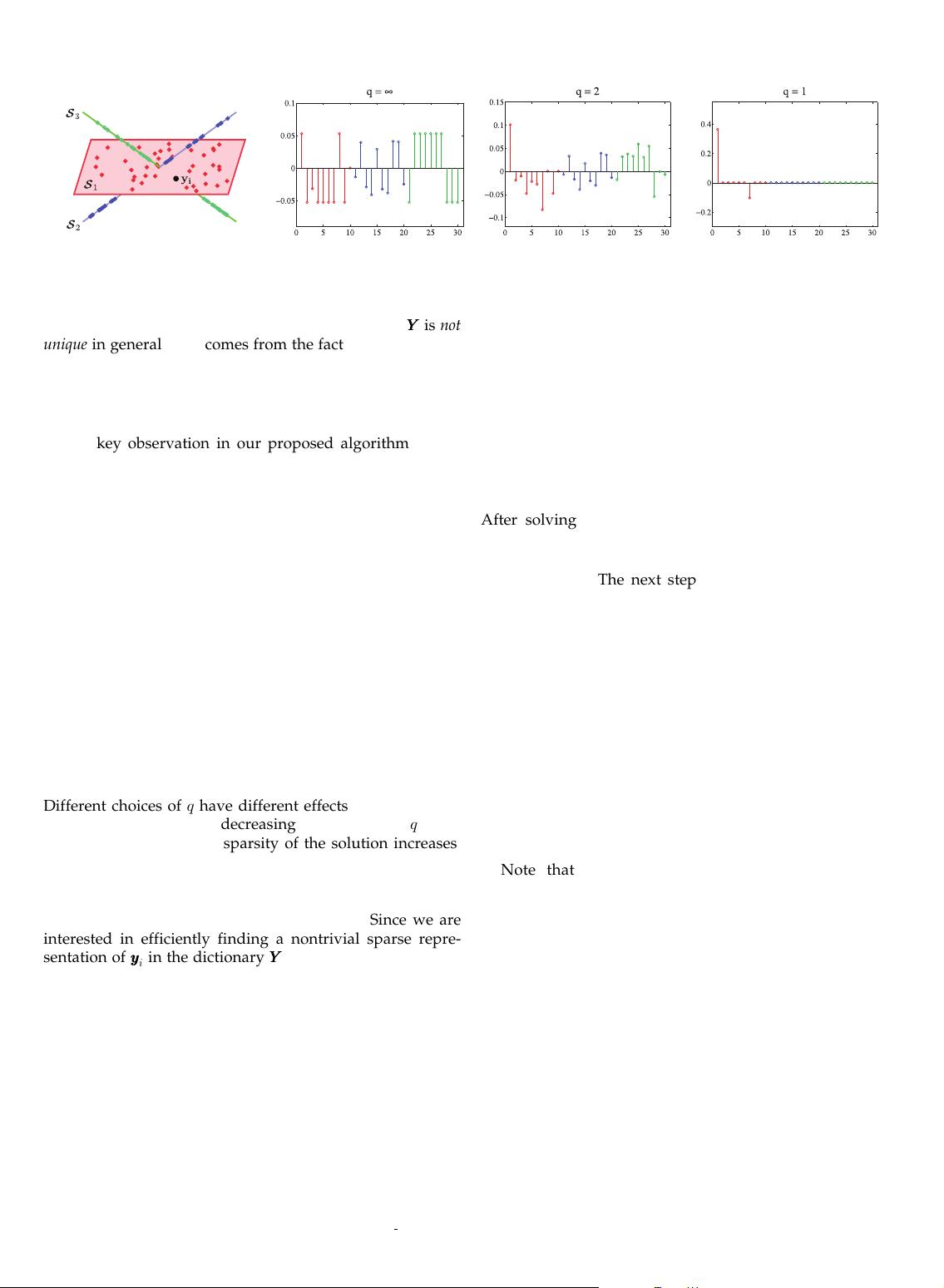
Different choices of q have different effects in the obtained
solution. Typically, by decreasing the value of q from
infinity toward zero, the sparsity of the solution increases,
as shown in Fig. 3. The extreme case of q ¼ 0 corresponds to
the general NP-hard problem [51] of finding the sparsest
representation of the given point, as the ‘
0
-norm counts the
number of nonzero elements of the solution. Since we are
interested in efficiently finding a nontrivial sparse repre-
sentation of yyyy
i
in the dictionary YYYY , we consider minimizing
the tightest convex relaxation of the ‘
0
-norm, i.e.,
minkcccc
i
k
1
s:t:yyyy
i
¼ YYYYcccc
i
;c
ii
¼ 0; ð4Þ
which can be solved efficiently using convex programming
tools [48], [49], [50] and is known to prefer sparse solutions
[29], [30], [31].
We can also rewrite the sparse optimization program (4)
for all data points i ¼ 1; ...;N in matrix form as
minkCCCCk
1
s:t:YYYY ¼ YYYYCCCC; diagðCCCCÞ¼00; ð5Þ
where CCCC ¼
4
½cccc
1
cccc
2
... cccc
N
2IR
NN
is the matrix whose
ith column corresponds to the sparse representation of
yyyy
i
, cccc
i
, and diagðCCCCÞ2IR
N
is the vector of the diagonal
elements of CCCC.
Ideally, the solution of (5) corresponds to subspace-
sparse representations of the data points, which we use next
to infer the clustering of the data. In Section 4, we study
conditions under which the convex optimization program
in (5) is guaranteed to recover a subspace-sparse represen-
tation of each data point.
2.2 Clustering Using Sparse Coefficients
After solving the proposed optimization program in (5),
we obtain a sparse representation for each data point whose
nonzero elements ideally correspond to points from the
same subspace. The next step of the algorithm is to infer
the segmentation of the data into different subspaces using
the sparse coefficients.
To address this problem, we build a weighted graph
G¼ðV; E;WWWWÞ, where V denotes the set of N nodes of the
graph corresponding to N data points and EVV
denotes the set of edges between nodes. WWWW 2 IR
NN
is a
symmetric nonnegative similarity matrix representing the
weights of the edges, i.e., node i is connected to node j by
an edge whose weight is equal to w
ij
. An ideal similarity
matrix WWWW , hence an ideal similarity graph G, is one in which
nodes that correspond to points from the same subspace are
connected to each other and there are no edges between
nodes that correspond to points in different subspaces.
Note that the sparse optimization program ideally
recovers to a subspace-sparse representation of each point,
i.e., a representation whose nonzero elements correspond to
points from the same subspace of the given data point. This
provides an immediate choice of the similarity matrix as
WWWW ¼jCCCCjþjCCCCj
>
. In other words, each node i connects itself
to a node j by an edge whose weight is equal to jc
ij
jþjc
ji
j.
The reason for the symmetrization is that, in general, a data
point yyyy
i
2S
‘
can write itself as a linear combination of some
points including yyyy
j
2S
‘
. However, yyyy
j
may not necessarily
choose yyyy
i
in its sparse representation. By this particular
choice of the weight, we make sure that nodes i and j get
connected to each other if either yyyy
i
or yyyy
j
is in the sparse
representation of the other.
2
2768 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 35, NO. 11, NOVEMBER 2013
Fig. 3. Three subspaces in IR
3
with 10 data points in each subspace, ordered such that the fist and the last 10 points belong to S
1
and S
3
,
respectively. The solution of the ‘
q
-minimization program in (3) for yyyy
i
lying in S
1
for q ¼ 1; 2; 1 is shown. Note that as the value of q decreases, the
sparsity of the solution increases. For q ¼ 1, the solution corresponds to choosing two other points lying in S
1
.
1. The ‘
q
-norm of cccc
i
2 IR
N
is defined as kcccc
i
k
q
¼
4
ð
P
N
j¼1
jc
ij
j
q
Þ
1
q
.
2. To obtain a symmetric similarity matrix, one can directly impose the
constraint of CCCC ¼ CCCC
>
in the optimization program. However, this results in
increasing the complexity of the optimization program and, in practice,
does not perform better than the postsymmetrization of CCCC, as described
above. See also [52] for other processing approaches of the similarity matrix.
剩余16页未读,继续阅读

netysh609760329
- 粉丝: 5
- 资源: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


