KMP算法与字典树详解:提升字符串处理效率
需积分: 10 44 浏览量
更新于2024-09-11
收藏 62KB DOC 举报
本文档主要涵盖了算法总结中的三个核心主题:KMP算法、树状数组(也称前缀和或区间更新数组)以及字典树。让我们逐一深入探讨这些重要的数据结构和算法。
1. **KMP算法**
KMP算法(Knuth-Morris-Pratt)是一种高效的字符串匹配算法,用于在一个主串中查找是否存在给定的模式串。它的核心思想是利用预处理得到的“部分匹配表”(next数组)来避免回溯搜索。next数组记录的是模式串中每个位置失配后应该跳到的下一个可能匹配的位置。构建next数组的方法是自底向上遍历模式串,遇到不匹配时,从当前位置的前一个已匹配字符开始向前回溯,直到找到一个相同的字符或到达模式串起始位置。在主串匹配过程中,如果当前字符与模式串不匹配,根据next数组可以立即跳到适当位置继续搜索,从而减少无效的比较。对于给出的例子,主串`abcdabcad`并未包含模式串`abcaba`,体现了KMP算法的高效性。
2. **树状数组(区间更新数组)**
树状数组,也常用于处理区间查询问题,其本质上是对一维数组进行动态范围查询和更新的高效数据结构。通过构造一个线性结构,可以在O(logn)时间内完成区间和的计算。在实际应用中,例如求解一维数组的前缀和,或者在每个位置插入或删除元素后快速更新区间和。其基本操作包括区间查询、单点修改等。对于特定场景,树状数组能够简化复杂度,提高算法效率。
3. **字典树(Trie/前缀树)**
字典树,又称Trie树,是一种用于存储字符串集合的数据结构,通过分支表示每个字符,使得查找、插入和删除操作都具有较高的效率。在给出的例子中,字典树被用来存储11个含有相似前缀的字符串,通过这种方式可以方便地找到这些字符串的最长公共前缀。构建字典树的过程是从第一个字符串开始,遍历每个字符,如果字符在当前节点已存在,则沿树向下移动;否则,在该字符处创建新节点。这种方法有助于高效地进行字符串操作,尤其是在需要频繁查找、插入或删除具有相同前缀的字符串时。
总结起来,KMP算法提供了字符串匹配的高效策略,树状数组适用于动态区间计算,而字典树则是字符串处理中不可或缺的数据结构。理解并掌握这些算法和数据结构,将有助于提升编程解决问题的效率和准确性。在实际编程中,灵活运用这些工具,能有效优化代码性能,解决各种复杂的问题。
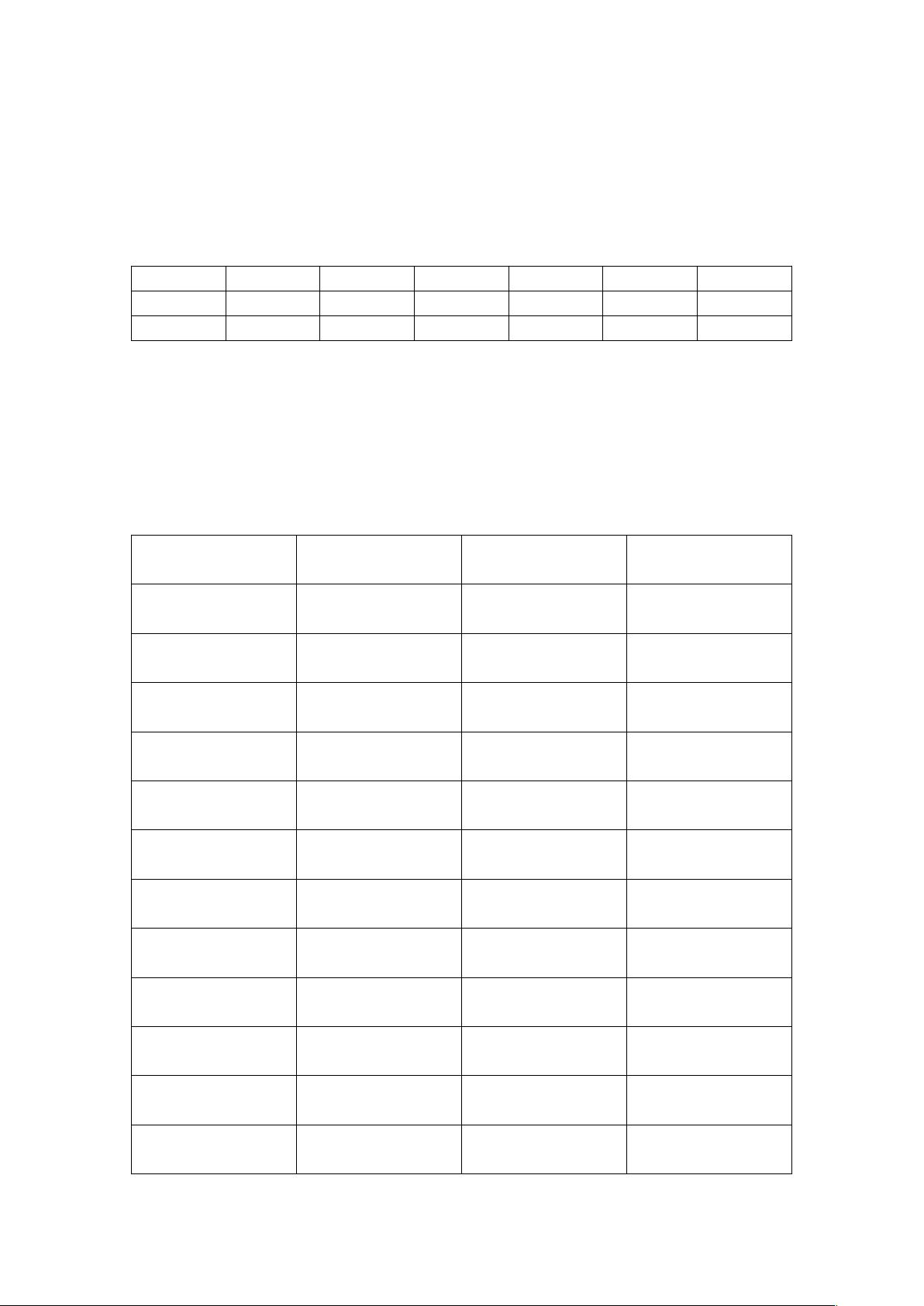
一、 KMP 算法
当判断模式串在主串中,出现过几次。标记出模式串重复
0 1 2 3 4 5 6
a b C a b a
-1 0 0 0 1 2 1
如图,模式串为‘abcaba’,第一行表示在模式串中的位置,第二行
表示在对应位置上的字符,第三行表示若在该位置失配了,它返回
的位置。
假如主串为‘abcdabcad’,
主串 模式串 模式串的位置 是否匹配
a a 1
匹配
b b 2
匹配
c c 3
匹配
d a 4
不匹配
d a 1
不匹配
d
空
0
不匹配
a a 1
匹配
b b 2
匹配
c c 3
匹配
a a 4
匹配
d b 5
不匹配
d b 2
不匹配
下载后可阅读完整内容,剩余5页未读,立即下载
2014-01-06 上传
2008-12-11 上传
点击了解资源详情
2008-11-12 上传
2020-03-06 上传
2024-03-22 上传
2023-03-11 上传

u010936022
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 淘淘商城源码-Java代码类资源
- mybatis - Springboot+Mybatis+MySql搭建实例.zip
- 商务团队背景的商务幻灯片下载PPT模板
- Python库 | VizKG-0.0.3-py3-none-any.whl
- 直方图修改:代码执行直方图修改-matlab开发
- Android-project-FishPond:ZJU中的Android课程,这是名为FishPond的最终项目,这是一个适合时间大师的应用
- mm-screen:马克·米纳维尼(Mark Minervini)在“像股票向导一样交易”一书中描述的股票筛选器,用于识别超级绩效股票
- POO-2021
- SergioHPassos.github.io
- Quarantine-Friends:编码Dojo小组项目
- code-red:可视化代码 RED
- EpigenomicsTask_MscOmics
- VK-DMR:VK DMR文件
- kiwi:简约的内存键值存储
- Trex-Game-2:有游戏结束条件
- Python库 | vizex-2.0.4-py3-none-any.whl
