HDFS深度解析:架构设计与核心特性
73 浏览量
更新于2024-08-27
收藏 159KB PDF 举报
"Hadoop分布式文件系统(HDFS)的设计和架构主要目标是应对大规模硬件故障,实现高吞吐量的数据处理,支持大数据集的存储,并适应流式读取和批量处理的场景。它采用write-once-read-many的访问模式,简化一致性问题。HDFS通过将计算移到数据附近来提高效率,并具有跨平台兼容性。系统由中心化的Namenode和多个Datanode组成,Namenode管理文件命名空间和访问,Datanode负责存储块的管理。文件被分割为多个block,分布存储在Datanode上,Namenode负责block的定位。HDFS基于Java,确保跨平台运行,通常Namenode在一个节点,其余节点运行Datanode。"
Hadoop分布式文件系统(HDFS)是一种为处理大规模数据而设计的分布式存储系统。它的核心设计目标是应对硬件错误的频繁发生,确保系统能够快速检测并自动恢复,以保持服务的连续性和可靠性。由于HDFS可能由数百甚至数千个服务器组成,因此每个组件的故障都被视为常态,而不是异常事件。
HDFS优化了数据处理方式,更适合流式读取和批量处理应用,而不是追求低延迟的随机访问。它旨在处理GB到TB级别的大型文件,单个HDFS实例可以支持数以千万计的文件。这种设计使得HDFS成为大数据分析任务,如MapReduce或Web爬虫的理想选择,这些任务通常遵循write-once-read-many的模型,即文件一旦写入,就不再修改,简化了数据一致性管理。
HDFS的架构包括主/从结构,由一个Namenode作为中心节点,负责维护文件系统的元数据(如文件名、文件位置等)和客户端的文件访问控制。Datanodes是工作在集群中的从属节点,负责实际的数据存储和处理,每个Datanode通常对应集群中的一台机器。文件在Datanode之间被划分为多个数据块(blocks),Namenode根据这些块的存储位置向客户端提供文件访问信息。
HDFS的设计哲学强调了“计算应该接近数据”这一原则,因为移动大量数据的成本远高于将计算任务移到数据附近。这种设计提高了大规模数据处理的效率,特别是在处理海量数据时。此外,HDFS用Java编写,保证了其在各种操作系统上的可移植性。
在实际部署中,通常将Namenode部署在单独的服务器上,集群中的其他服务器运行Datanode实例。虽然理论上可以在一台机器上运行多个Datanode,但在实践中这并不常见,因为这会增加单点故障的风险,并可能影响性能。这种分布式架构允许HDFS扩展到非常大的规模,处理PB级别的数据,同时保持高可用性和容错性。
Hadoop分布式文件系统:架构和设计要点分布式文件系统:架构和设计要点
一、前提和设计目标一、前提和设计目标
1、硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检
测和快速、自动的恢复是HDFS的核心架构目标。
2、跑在HDFS上的应用与一般的应用不同,它们主要是以流式读为主,做批量处理;比之关注数据访问的低延迟问题,更关
键的在于数据访问的高吞吐量。
3、HDFS以支持大数据集合为目标,一个存储在上面的典型文件大小一般都在千兆至T字节,一个单一HDFS实例应该能支撑
数以千万计的文件。
4、 HDFS应用对文件要求的是write-one-read-many访问模型。一个文件经过创建、写,关闭之后就不需要改变。这一假设简
化了数据一致性问题,使高吞吐量的数据访问成为可能。典型的如MapReduce框架,或者一个web crawler应用都很适合这个
模型。
5、移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效,这在数据达到海量级别的
时候更是如此。将计算移动到数据附近,比之将数据移动到应用所在显然更好,HDFS提供给应用这样的接口。
6、在异构的软硬件平台间的可移植性。
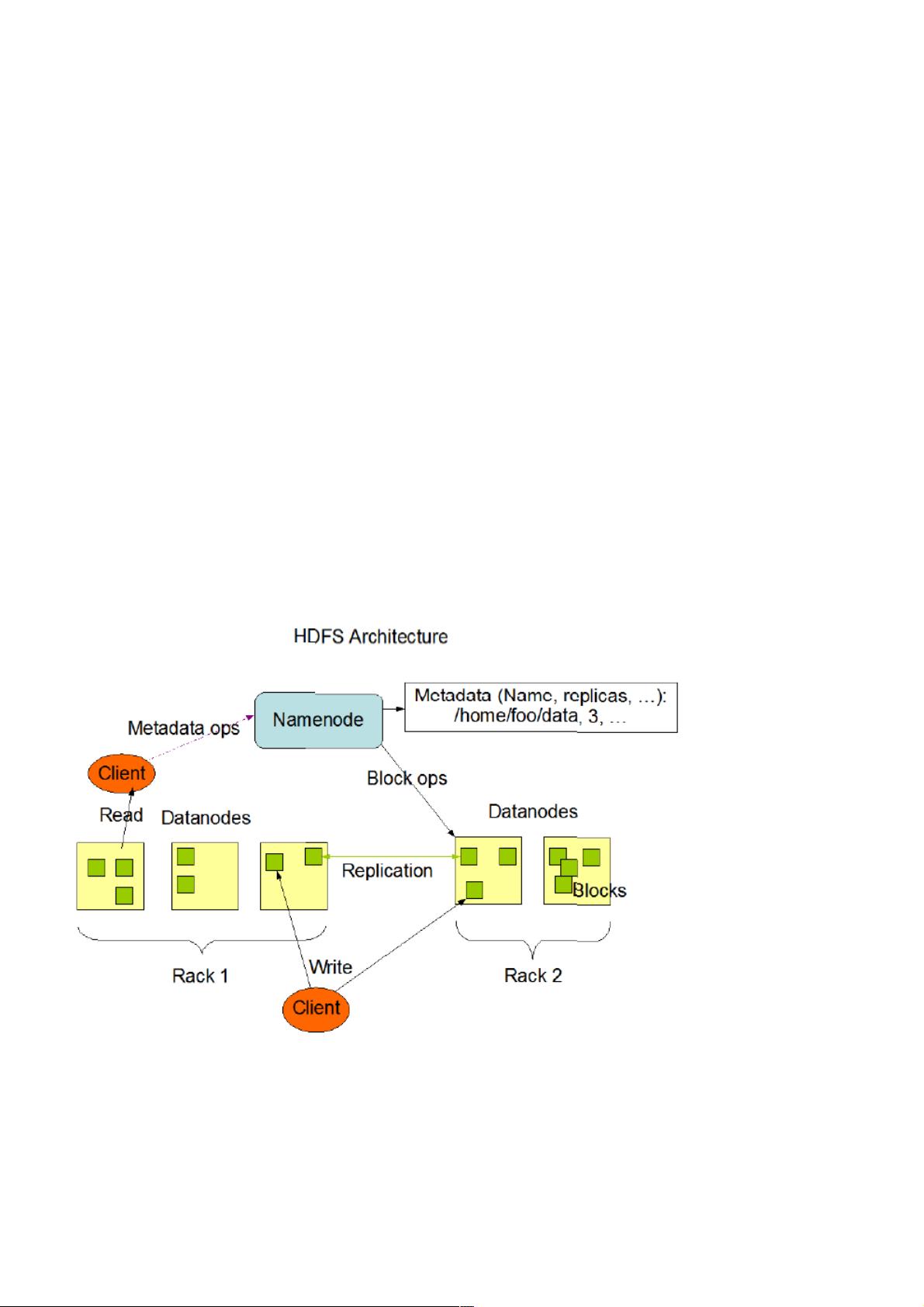
二、二、Namenode和和Datanode
HDFS采用master/slave架构。一个HDFS集群是有一个Namenode和一定数目的Datanode组成。Namenode是一个中心服务
器,负责管理文件系统的namespace和客户端对文件的访问。Datanode在集群中一般是一个节点一个,负责管理节点上它们
附带的存储。在内部,一个文件其实分成一个或多个block,这些block存储在Datanode集合里。Namenode执行文件系统的
namespace操作,例如打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射。Datanode在Namenode
的指挥下进行block的创建、删除和复制。Namenode和Datanode都是设计成可以跑在普通的廉价的运行linux的机器上。
HDFS采用java语言开发,因此可以部署在很大范围的机器上。一个典型的部署场景是一台机器跑一个单独的Namenode节
点,集群中的其他机器各跑一个Datanode实例。这个架构并不排除一台机器上跑多个Datanode,不过这比较少见。
单一节点的Namenode大大简化了系统的架构。Namenode负责保管和管理所有的HDFS元数据,因而用户数据就不需要通过
Namenode(也就是说文件数据的读写是直接在Datanode上)。
三、文件系统的三、文件系统的namespace
HDFS支持传统的层次型文件组织,与大多数其他文件系统类似,用户可以创建目录,并在其间创建、删除、移动和重命名文
件。HDFS不支持user quotas和访问权限,也不支持链接(link),不过当前的架构并不排除实现这些特性。Namenode维护文
件系统的namespace,任何对文件系统namespace和文件属性的修改都将被Namenode记录下来。应用可以设置HDFS保存的
文件的副本数目,文件副本的数目称为文件的 replication因子,这个信息也是由Namenode保存。
四、数据复制四、数据复制
下载后可阅读完整内容,剩余3页未读,立即下载
140 浏览量
166 浏览量
140 浏览量
2021-10-02 上传
2021-10-11 上传
2022-07-14 上传
166 浏览量
2025-03-09 上传
点击了解资源详情

weixin_38664989
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android PRDownloader库:支持文件下载暂停与恢复功能
- Xilinx FPGA开发实战教程(第2版)精解指南
- Aprilstore常用工具库的Java实现概述
- STM32定时开关模块DXP及完整项目资源下载指南
- 掌握IHS与PCA加权图像融合技术的Matlab实现
- JSP+MySQL+Tomcat打造简易BBS论坛及配置教程
- Volley网络通信库在Android上的实践应用
- 轻松清除或修改Windows系统登陆密码工具介绍
- Samba 4 2级免费教程:Ubuntu与Windows整合
- LeakCanary库使用演示:Android内存泄漏检测
- .Net设计要点解析与日常积累分享
- STM32 LED循环左移项目源代码与使用指南
- 中文版Windows Server服务卸载工具使用攻略
- Android应用网络状态监听与质量评估技术
- 多功能单片机电子定时器设计与实现
- Ubuntu Docker镜像整合XRDP和MATE桌面环境
