Spring Data JPA高级实战:项目核心场景与深度解析
版权申诉
109 浏览量
更新于2024-07-01
收藏 587KB DOC 举报
Spring Data JPA系列3深入探讨了在实际项目开发中如何应用JPA的高级复杂场景。前两篇文档分别介绍了JPA的基础概念和在Spring Boot项目中的快速集成与基础使用。本篇内容将重点关注以下几个核心点:
1. Repository的深入理解:Repository是Spring Data JPA的核心组件,它提供了一种轻量级的API,允许开发者在业务层面上直接操作数据。默认情况下,JpaRepository继承自Repository接口,并提供了CRUD(Create, Read, Update, Delete)操作的方法,如findAll(), findById(), save()和delete()等。这些方法背后由Spring Data JPA的底层实现自动处理数据库交互,简化了代码编写。
2. 自定义Repository:开发者可以根据项目需求自定义Repository接口,扩展或重写默认的方法,以便实现更复杂的查询逻辑。例如,通过继承SpringDataJpaRepository并添加自定义查询方法,如countBy(), findAllBy()等,可以实现更灵活的数据筛选。
3. 高级查询和扩展:Repository层还支持JPQL(Java Persistence Query Language)和HQL(Hibernate Query Language),这两种查询语言提供了强大的SQL表达能力。此外,还可以使用@Query注解直接编写动态SQL,或者使用Spring Data JPA的扩展功能如Specification来创建可组合的查询条件。
4. Spring Data JPA的底层实现:尽管Repository接口看起来复杂,但其背后是Spring框架和JPA规范的协同工作。SpringDataCommon库提供了基础的Repository接口,而JPA则负责与数据库的交互,实现了持久化对象到数据库和从数据库检索对象的功能。
5. 动态查询和优化:在处理大量数据或者复杂查询时,了解如何使用延迟加载(Lazy Loading)、预加载(Eager Fetching)以及优化SQL语句性能是关键。Spring Data JPA提供了很多机制来控制这些行为,以提高应用程序的性能。
通过学习和实践这些高阶场景,开发者可以更好地理解和运用Spring Data JPA,使其在项目开发中发挥更大的效能,减少重复代码,提升代码质量。掌握这些技巧将使你在面对实际业务需求时能够得心应手,提高开发效率。
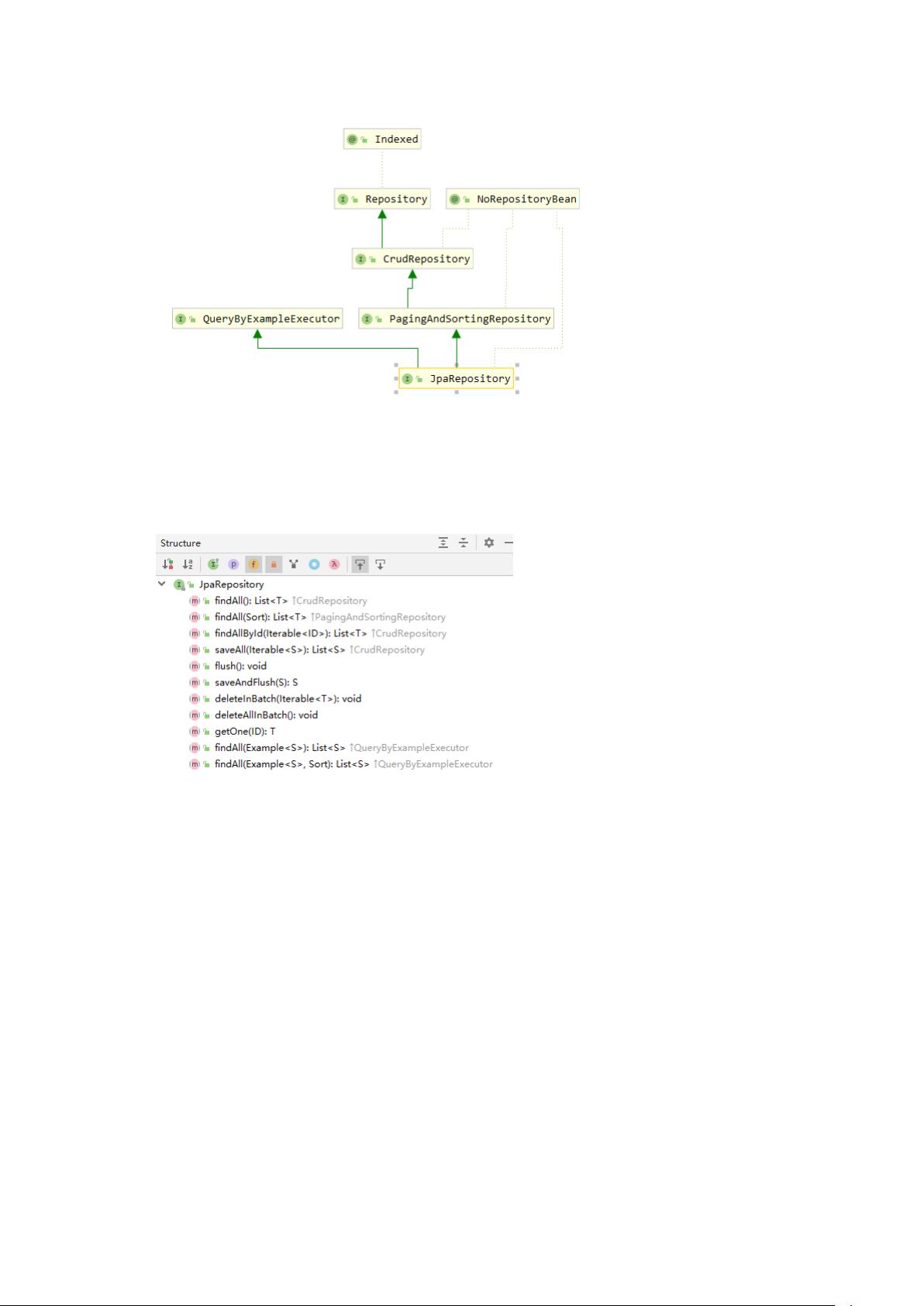
从类图可以看得出来它继承了 PagingAndSortingRepository 类,也就继承了其所有方法,
并且实现类也是 SimpleJpaRepository。从类图上还可以看出 JpaRepository 继承和拥有了
QueryByExampleExecutor 的相关方法。
通过源码和 CrudRepository 相比较,它支持 Query By Example,批量删除,提高删除效率,
手动刷新数据库的更改方法,并将默认实现的查询结果变成了 List。
额外补充一句:
实际的项目编码中,大部分的场景中,我们自定义 Repository 都是继承 JpaRepository 来
实现的。
自定义 Repository
先看个自定义 Repository 的例子,如下:
剩余16页未读,继续阅读
2023-09-20 上传
2023-07-14 上传
2023-06-07 上传
2023-09-11 上传
2023-06-28 上传
2023-07-22 上传

书博教育
- 粉丝: 1
- 资源: 2834
 我的内容管理
展开
我的内容管理
展开







最新资源
- 天池大数据比赛:伪造人脸图像检测技术
- ADS1118数据手册中英文版合集
- Laravel 4/5包增强Eloquent模型本地化功能
- UCOSII 2.91版成功移植至STM8L平台
- 蓝色细线风格的PPT鱼骨图设计
- 基于Python的抖音舆情数据可视化分析系统
- C语言双人版游戏设计:别踩白块儿
- 创新色彩搭配的PPT鱼骨图设计展示
- SPICE公共代码库:综合资源管理
- 大气蓝灰配色PPT鱼骨图设计技巧
- 绿色风格四原因分析PPT鱼骨图设计
- 恺撒密码:古老而经典的替换加密技术解析
- C语言超市管理系统课程设计详细解析
- 深入分析:黑色因素的PPT鱼骨图应用
- 创新彩色圆点PPT鱼骨图制作与分析
- C语言课程设计:吃逗游戏源码分享
