E-NeRV:提升内隐神经视频表征效率的时空背景解纠缠方法
136 浏览量
更新于2024-06-19
收藏 3.52MB PDF 举报
"E-NeRV:基于时空背景的内隐神经视频表征方法"
E-NeRV(E-Neural Video Representation via Spatio-Temporal Disentanglement)是一种新颖的神经视频表征方法,旨在解决传统内隐神经表征(INR)在视频处理中的参数冗余问题。传统的INR在处理连续信号时,如空间和时间信息,往往通过直接从帧索引输入来输出视频帧,这导致模型参数的耦合和尺寸增大。E-NeRV针对这一挑战,提出了将空间和时间背景进行解纠缠的新公式,实现了模型参数的显著减少,同时保持甚至提升了表示能力。
E-NeRV的核心创新在于将视频的时空信息分解为独立的空间和时间背景。这种解纠缠的方法使得模型能够更加高效地处理视频数据,减少了冗余参数,从而在不牺牲性能的情况下减小了模型规模。通过这种方式,E-NeRV可以实现更快的收敛速度和更高的计算效率。实验结果显示,这种方法能以较少的参数显著提升算法性能,比原版NeRV的收敛速度提高了8倍。
论文作者包括李子章、Mengmeng Wang、Huaijin Pi、Jianbiao Mei和Yong Liu,他们均来自浙江大学。该研究进一步拓展了INR在神经视频表示领域的应用,特别是在3D任务和图像表示方面,提供了更轻量级且高效的解决方案。通过引入光网络和解纠缠的时空表示,E-NeRV不仅优化了模型参数的分布,还增加了卷积块中的信道维度,这有助于在保持相似或更少参数的前提下,提升模型的性能。
关键词涵盖内隐表征、神经视频表征、时空解纠缠,强调了该工作的核心概念和技术。E-NeRV的源代码已经公开,可以在GitHub上通过链接https://github.com/kyleleey/E-NeRV获取,便于其他研究者和开发者进行研究和应用。
E-NeRV的提出对视频处理和计算机视觉领域具有重要意义,它推动了内隐神经表示技术的发展,降低了大规模视频处理的计算需求,为未来高效率、高质量的视频分析和生成奠定了基础。随着技术的不断进步,可以预见E-NeRV将在虚拟现实、增强现实、视频编码和传输等领域发挥重要作用。
+v:mala2255获取更多论
文
∈
6个Z。Li等人
时间
帧
索引
输入
空间
MLP
块
网格坐标
固定
帧输出
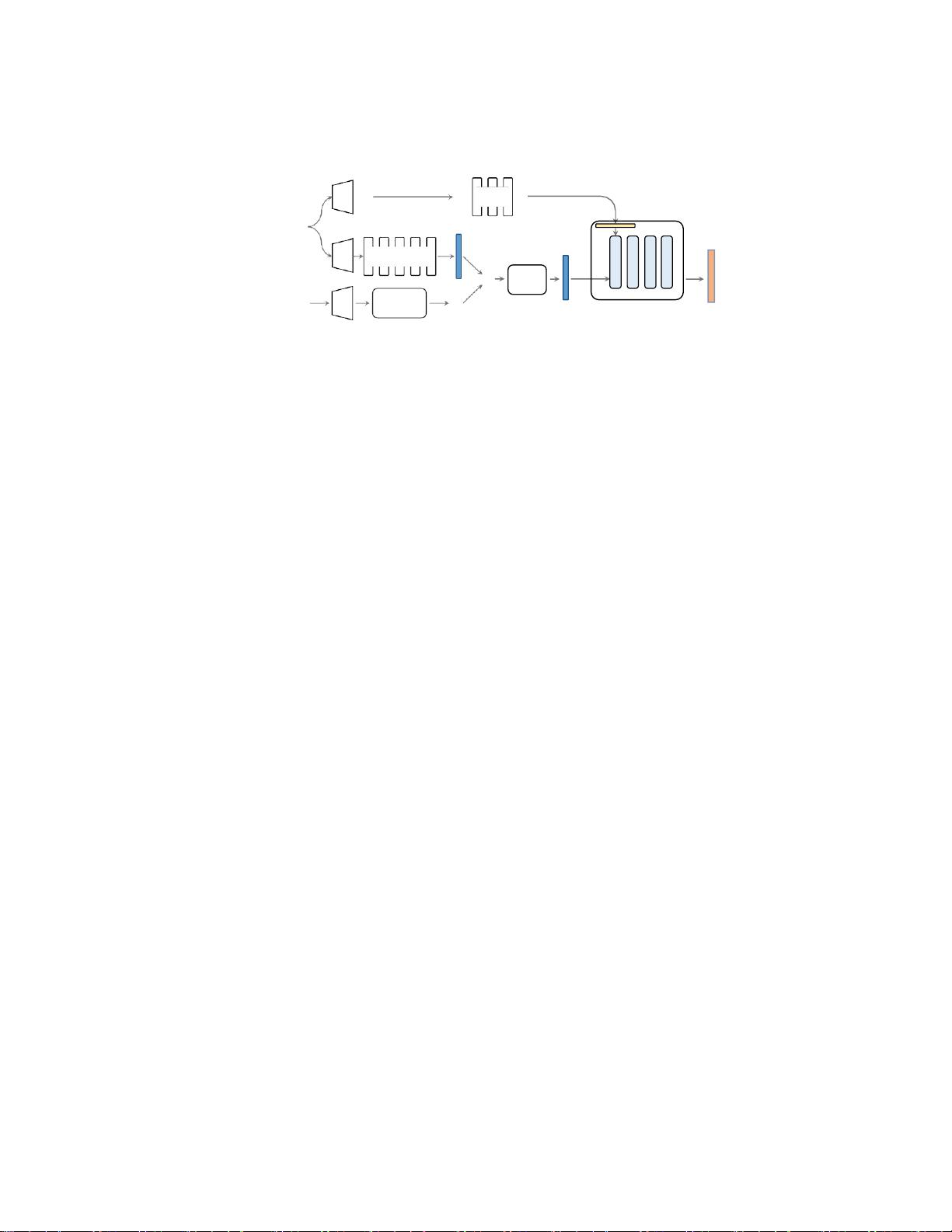
图二、拟议E-NeRV的架构。我们的空间-时间特征图是
从具有较少参数的分
离的空间和输入时间上下文生成的(第二节)。4.1)。时间信息也被引入
到卷积阶段作为归一化过程(第11节)。4.1)以获得更好的性能。此
外,我们重新设计了NeRV块,以进一步删除冗余结构(第节)。4.2)。
将逐图像视频隐式表示作为索引到图像公式化,而我们将其视为具有
解纠缠公式化的生成过程,并且帧索引仅表示时间上下文。在第节
中。4.在第四节中,我们尝试了用时空解纠缠来升级冗余结构,并定
量和定性地说明了我们的方法的显著性能和收敛速度。五、
4
方法
所提出的E-NeRV的整体架构如图2所示。本节将介绍我们处理冗余参
数和结构的方法更具体地说,在部分。4.1我们陈述了如何理清空间
和时间的表述以及由此产生的表述和架构。而在科。4.2我们阐述我
们的NeRV大楼的升级设计。
4.1
解纠缠图像式视频INR
NeRV中的第一个冗余部分出现在MLP的最后一层例如,NeRV-L模型
具有12
.
5M参数,其大小的近70%来自最后一个MLP层,其输出为
f
t
R
112×9×16
。虽然特征图的高度和宽度相对较小,但它需要较大的通道
数来保证最终性能。在实验中(部分。5.4),我们展示了一些微不
足道的修改,这些修改可能会缓解参数的大尺寸,但会导致 和我
们的相比性能大幅下降我们声称这种结构需要存在,因为NeRV直接
并且仅从输入t生成帧特征映射f
t
,这意味着从时间输入一起导出空间
和时间信息。
Conv
Pixel-Shuffle
Conv
实例规范
剩余26页未读,继续阅读
2022-08-08 上传
2021-05-07 上传
2021-05-20 上传
2021-01-31 上传
2021-02-09 上传
2021-04-11 上传
2021-05-02 上传
2021-05-24 上传
2021-07-17 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 天池大数据比赛:伪造人脸图像检测技术
- ADS1118数据手册中英文版合集
- Laravel 4/5包增强Eloquent模型本地化功能
- UCOSII 2.91版成功移植至STM8L平台
- 蓝色细线风格的PPT鱼骨图设计
- 基于Python的抖音舆情数据可视化分析系统
- C语言双人版游戏设计:别踩白块儿
- 创新色彩搭配的PPT鱼骨图设计展示
- SPICE公共代码库:综合资源管理
- 大气蓝灰配色PPT鱼骨图设计技巧
- 绿色风格四原因分析PPT鱼骨图设计
- 恺撒密码:古老而经典的替换加密技术解析
- C语言超市管理系统课程设计详细解析
- 深入分析:黑色因素的PPT鱼骨图应用
- 创新彩色圆点PPT鱼骨图制作与分析
- C语言课程设计:吃逗游戏源码分享
