Spark驱动基因序列分析:加速与并行处理策略
133 浏览量
更新于2024-08-31
收藏 747KB PDF 举报
Spark技术在基因序列分析中的应用已经成为生命科学研究领域的一个重要趋势。随着生命科学的快速发展,基于DNA分析的应用在食品工业细菌培养鉴定、癌症诊断等领域扮演着关键角色,但同时也面临着数据处理速度和并行计算的需求。Spark技术作为一种新兴的并行计算框架,因其内存内计算能力和易用性,使得无需复杂的MPI编程就能实现基因序列分析的并行化处理。
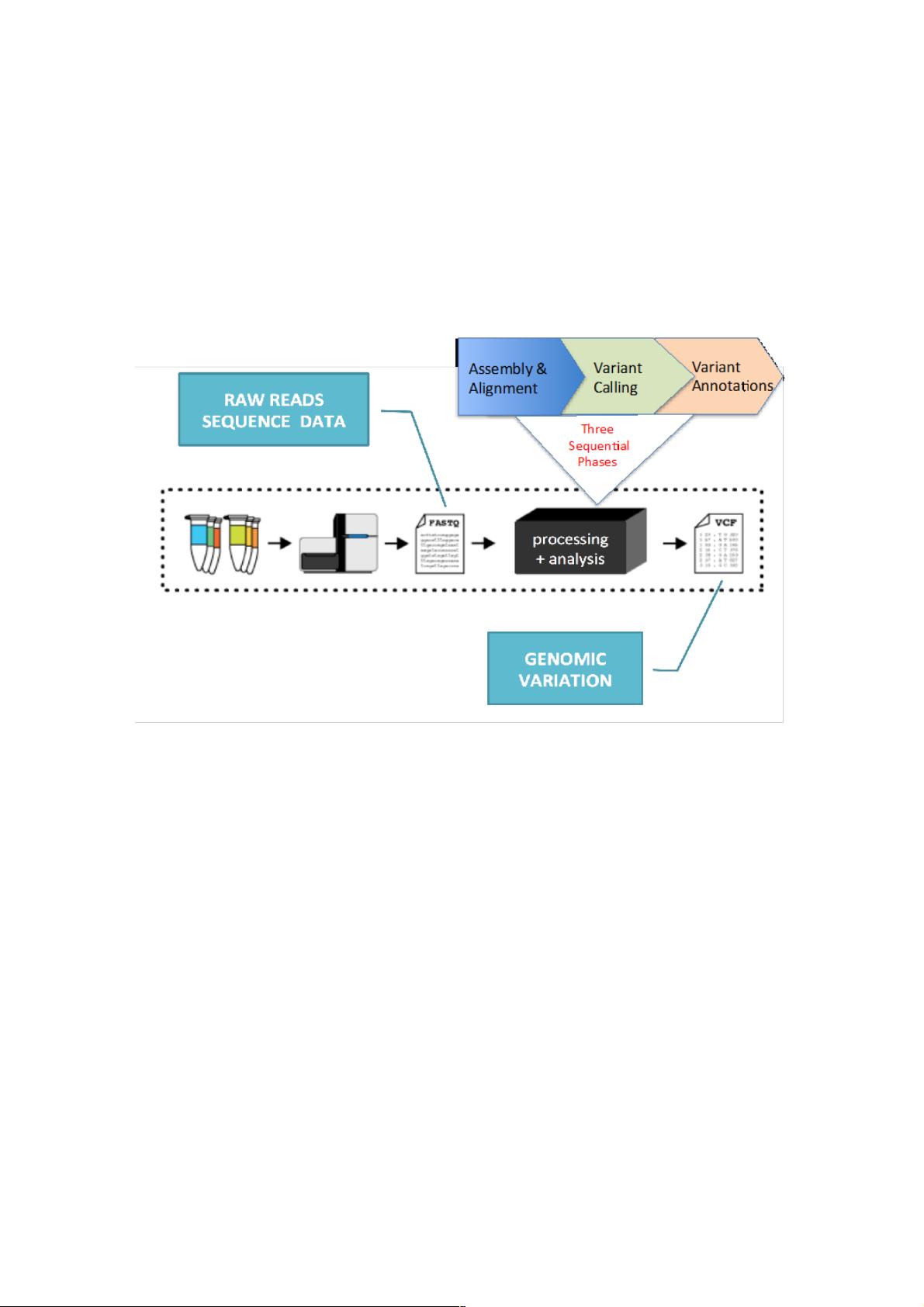
基因序列分析工作流程通常遵循GATK的最佳实践,以FASTQ文件为输入,经历BWA-mem比对、生成SAM/BAM文件,然后通过Picard工具去重和处理,最后由GATK的多种工具(如RealignerTargetCreator、IndelRealigner等)进行深度分析。这个过程涉及到大量的数据预处理和密集计算,尤其是在处理高通量测序数据时,时间成本和经济成本较高。
Spark技术的优势在于其容错性、分布式内存管理和自动分区功能,能够将传统的串行分析任务转化为高效的并行任务。在Spark的不同模式下,如本地模式(Local)、集群模式(Spark on YARN)或分布式模式(Spark Standalone),用户可以根据实际环境选择合适的运行方式。在内存计算的帮助下,Spark能显著提高数据处理速度,减少分析时间,这对于大规模基因数据的实时分析和挖掘至关重要。
GATK4是基于Spark技术的基因分析软件,由Broad研究所开发,它充分利用了Spark的特性,使得基因序列分析更加高效和便捷。在GATK4中,用户可以设置不同的运行参数,比如调整分区大小、缓存策略等,来优化性能和资源利用率。通过比较不同运算平台(如CPU、GPU、FPGA等)和运行参数组合,研究者可以找到最适合其特定应用场景的最优解决方案。
Spark技术在基因序列分析中的应用极大地推动了生命科学的科研进程,通过简化编程复杂度、提升并行计算能力,使得科学家们能够更快地处理和理解庞大的基因数据,从而发现更多的生物学秘密和潜在治疗策略。随着技术的不断发展,Spark有望在基因组学领域发挥更大的作用,助力生物医学研究的突破。
Spark技术在基因序列分析中的应用技术在基因序列分析中的应用
引言
生命科学方兴未艾, 从食品工业中的细菌培养鉴定到癌症快速诊断,基于 DNA 分析的应用不断出现,但同时基因分析应用也
面临着很大挑战;许多新技术、新方法被应用到基因序列分析应用中,包括 Spark、FPGA 以及 GPU 协处理器加速等,这些
技术的应用不仅能够使大部分生命科学领域的应用,包括开源和 ISV 软件,在不需要复杂的 MPI 编程情况下实现并行化处
理,同时 Spark 内存内计算技术也能够提高分析效率,加速工作流程, 缩短分析时间,从而有更多新的发现。本文将介绍如
何利用 Spark 技术运行常用的基因序列分析应用,包括在 Spark 不同模式下的运行方法, 运行过程以及运行结果分析,并比
较在不同运算平台以及不同运行参数情况下的性能和加速比。
1. 基因序列分析工作流
基因序列分析工作流以 GATK 的最佳实践为标准。它以最初的 FASTQ 文件为输入,从 BWA-mem 测序到 GATK 的
HaploTyperCaller,完成对整个样板的测序分析。
图 1、GATK 最佳实践
在测序工作流的第一阶段,BWA-mem 对输入文件 FASTQ 执行比对,生成序列比对和映射文件 SAM,然后通过 SortSam 生
成一个经过排序的 BAM 文件,实际上,BAM 文件是 SAM 文件的二进制形式,此后的处理均基于 BAM 二进制文件。
BAM 文件传送给 Picard 工具 MarkDuplicates, 去除重复的片段,并生成一个合并的、去除重复片段的 BAM 文件。以下的几
步,RealignerTargetCreator、IndelRealigner、BaseRecalibrator、PrintReads 和 HaplotypeCaller 都是 GATK 的一部分,是
对高吞吐序列数据进行分析的软件包。
下载后可阅读完整内容,剩余8页未读,立即下载
2021-07-16 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38743084
- 粉丝: 12
- 资源: 930
 我的内容管理
展开
我的内容管理
展开







最新资源
- 人工智能基础实验.zip
- chkcfg-开源
- Amaterasu Tool-开源
- twitter-application-only-auth:Twitter仅限应用程序身份验证的简单Python实现。
- 第一个项目:shoppingmall
- webpage-test
- JTextComponent.rar_Applet_Java_
- 人工智能原理课程实验1,numpy实现Lenet5,im2col方法实现的.zip
- PyPI 官网下载 | vittles-0.17-py3-none-any.whl
- Real-World-JavaScript-Pro-Level-Techniques-for-Entry-Level-Developers-V-:实际JavaScript的代码存储库
- Sitecore.Support.96670:修补程序解决了以下问题:选中“相关项目”复选框时,并非所有子项目都会发布,
- BioGRID-PPI:生物二进制PPI数据集和BioGRID的处理
- ownership-status:所有权状态页
- DMXOPL:用于末日和源端口的YMF262增强的FM补丁集
- VideoCapture.rar_视频捕捉/采集_Visual_C++_
- trd_mc:一个简单的蒙特卡洛TPX响应仿真引擎。专为ROOT互动模式
