Spark MLlib决策树详解
需积分: 26 180 浏览量
更新于2024-09-09
收藏 273KB PPT 举报
"Spark MLlib决策树用于机器学习中的分类任务,它是一种有监督学习算法。决策树通过构建树状模型来做出预测,其中每个内部节点代表一个特征或属性测试,每个分支代表一个测试输出,而叶节点则代表类别标签。在Spark中,决策树支持熵和基尼指数作为信息增益度量,用于确定最优分割点。"
Spark MLlib的决策树算法主要涉及以下几个关键点:
1. **决策树分类**:决策树是一种常见的分类方法,它通过一系列基于特征的判断来预测类别。在有监督学习中,每个样本都带有标签,而在无监督学习中,数据没有标签,用于聚类。
2. **训练数据**:训练数据集包含特征和对应的标签,用于构建决策树模型。例如,`F1:V1 F2:V2 Fn:Vn`表示特征和它们的值。
3. **参数设置**:训练决策树时,需要指定一些参数,如`numClasses`(分类数量)、`categoricalFeaturesInfo`(离散特征信息,表示哪些特征是离散的及其值域)、`impurity`(信息增益计算方式,如熵或基尼指数)、`maxDepth`(树的最大深度)和`maxBins`(数据分箱的数量,用于数值特征的离散化)。
4. **标签编码**:在Spark中,标签通常从0开始,即使原始数据中的标签可能是1, 2, 3, 4, 5等。
5. **特征处理**:`categoricalFeaturesInfo`参数告诉算法哪些特征是离散的,以及每个离散特征有多少个可能的值。对于未指定的特征,算法会假设它们是连续的。
6. **信息增益度量**:决策树的分裂依据可以选择熵、信息增益率或基尼指数。熵倾向于选择具有更多特征值的特征,信息增益率偏好特征值较少的特征,而基尼指数则在两者之间,分别对应ID3、C4.5和CART算法。Spark仅支持熵和基尼指数。
7. **过拟合与剪枝**:决策树的深度`maxDepth`过大可能导致过拟合,即模型过于复杂,对训练数据过度适应,但在新数据上的表现不佳。适当的剪枝可以避免过拟合,提高泛化能力。
8. **评估与测试**:通过交叉验证或保留一部分数据作为测试集,可以评估决策树的性能,如精度、召回率、F1分数等。
9. **错误率与树深度**:模型的错误率并不总是随着树的深度增加而降低。当树变得过于复杂时,可能会捕获训练数据中的噪声,导致对新数据的预测不准确,这就是过拟合现象。
Spark MLlib的决策树库提供了一种高效且可扩展的方法来执行大规模数据的分类任务,适合分布式环境中的机器学习应用。通过理解并调整这些关键参数,可以优化模型的性能,使其更好地适应特定的数据集和任务需求。
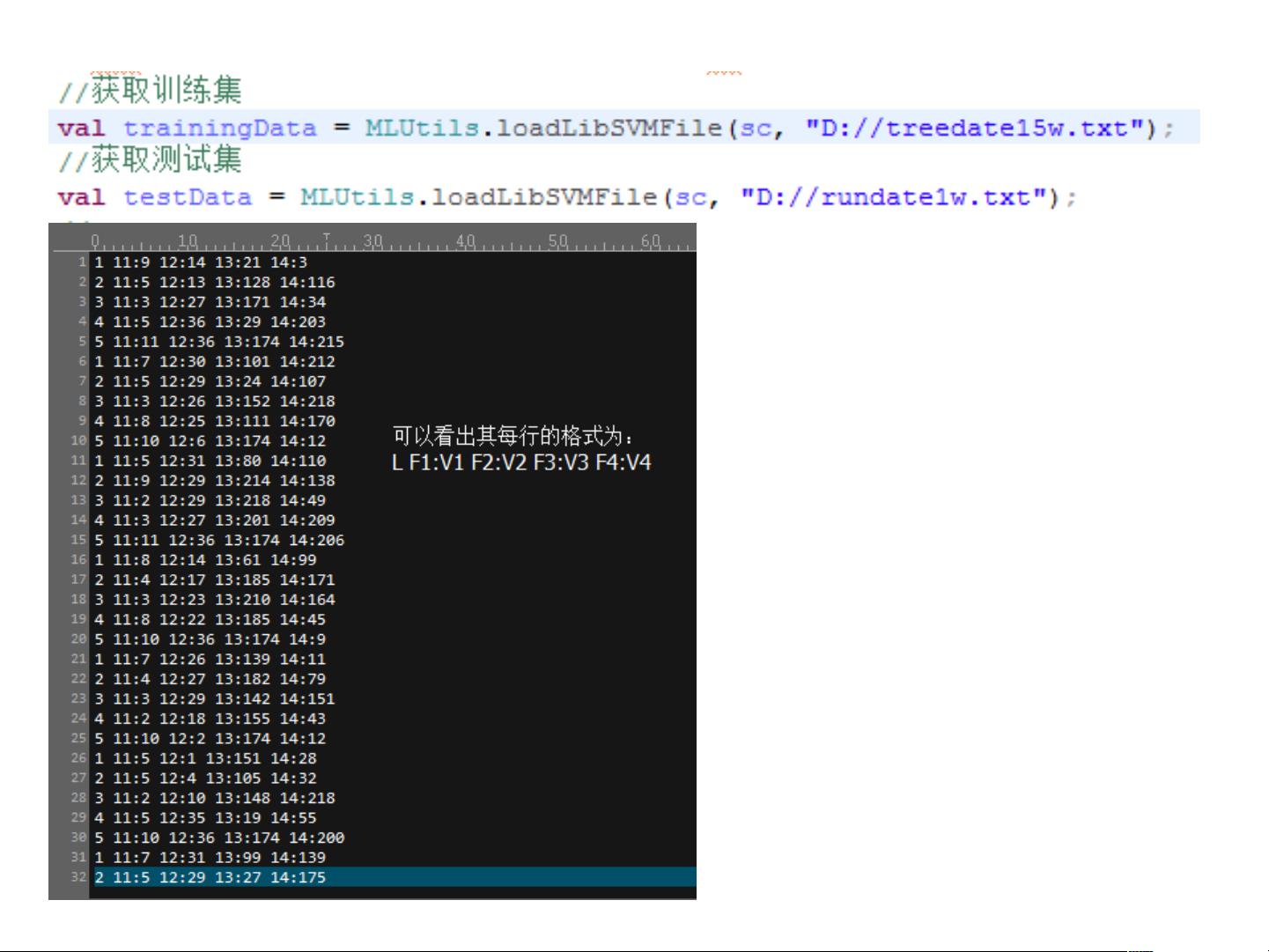
L => label :标签
F => feature :特征
V => value :特征值
如果所有训练数据都有标签,则为
有监督学习。如果数据没有标签,
就是无监督学习,也称聚类。
也就是说:无监督学习的训练集将
会是如下的格式:
F1:V1 F2:V2 ... Fn:Vn
剩余11页未读,继续阅读
567 浏览量
129 浏览量
2023-05-25 上传
2023-04-26 上传
164 浏览量
2024-12-18 上传
192 浏览量
183 浏览量

qq_26752291
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Premiere Pro CS6视频编辑项目教程微课版教案
- SSM+Lucene+Redis搜索引擎缓存实例解析
- 全栈打字稿应用:演示项目实践与探索
- 仿Windows风格的AJAX无限级树形菜单实现教程
- 乐华2025L驱动板通用升级解决方案
- Java通过jcraft实现SFTP文件上传下载教程
- TTT素材-制造1资源包介绍与记录
- 深入C语言编程技巧与实践指南
- Oracle数据自动导出并转换为Excel工具使用教程
- Ubuntu下Deepin-Wine容器的使用与管理
- C语言网络聊天室功能详解:禁言、踢人与群聊
- AndriodSituationClick事件:详解按钮点击响应机制
- 探索Android-NetworkCue库:高效的网络监听解决方案
- 电子通信毕业设计:简易电感线圈制作方法
- 兼容性数据库Compat DB 4.2.52-5.1版本发布
- Android平台部署GNU Linux的新方案:dogeland体验
