使用TensorRT加速TensorFlow推理指南
需积分: 10 118 浏览量
更新于2024-07-15
收藏 552KB PDF 举报
"NVIDIA TensorRT 是一款用于优化和加速深度学习推理(Inference)的高性能库,特别设计用于在NVIDIA GPU上运行。TensorRT与TensorFlow集成后,形成了TF-TRT,能够显著提高模型的推理速度,同时保持精度。这份用户指南详细介绍了如何在TensorFlow中使用TensorRT来提升性能。
第一章概述:
1.1 引言:本文档旨在帮助开发者理解如何在TensorFlow环境中利用TensorRT进行推理加速,从而提高应用的响应速度和效率。
1.2 整合TensorFlow与TensorRT的优势:整合这两者可以降低推理延迟,增加吞吐量,特别是在处理复杂的深度学习模型时,能够充分利用GPU的计算能力。
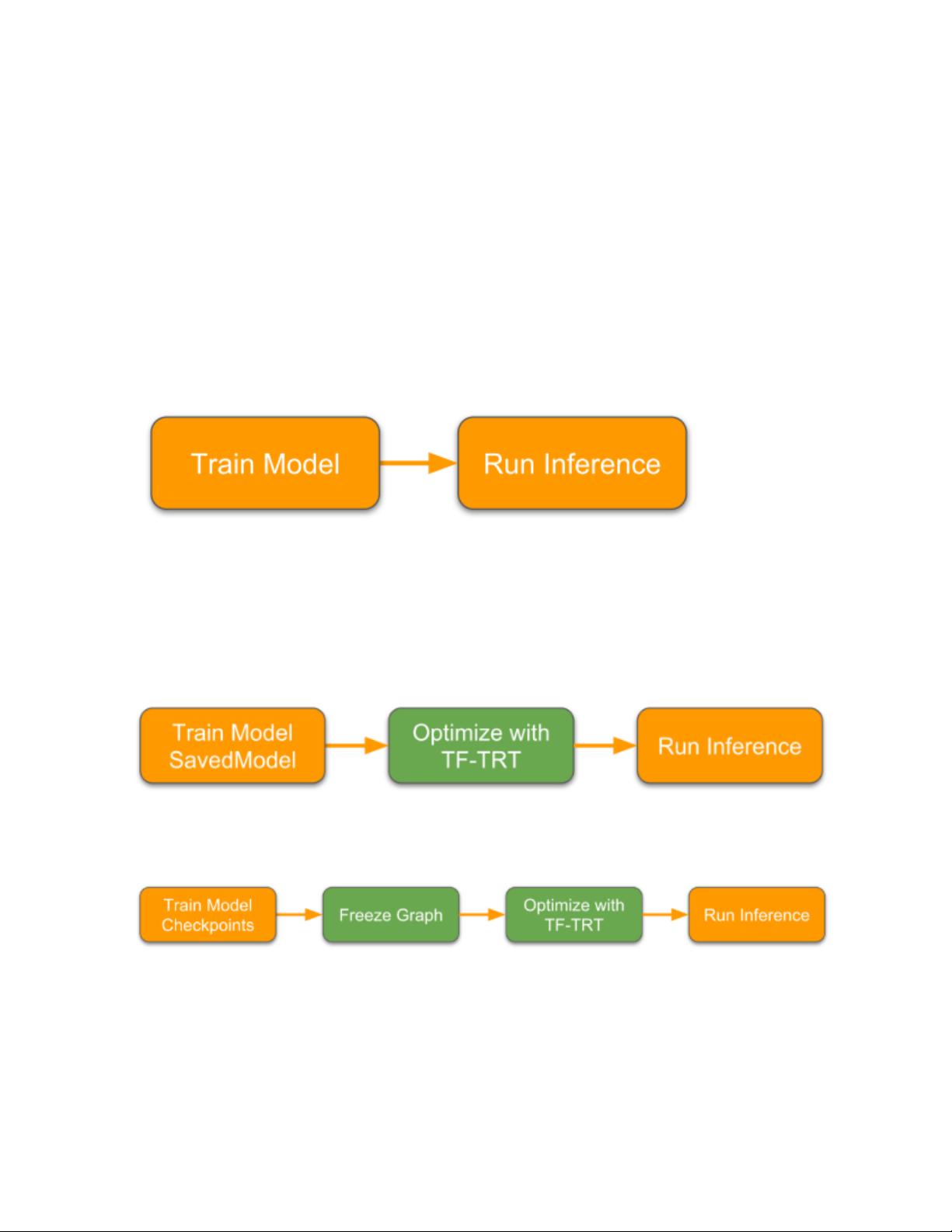
1.3 TF-TRT工作流程:该工作流程包括模型构建、优化、序列化和部署四个主要步骤,旨在将TensorFlow模型转换为TensorRT可执行的高效形式。
第二章使用TF-TRT:
2.1 安装TF-TRT:用户需要先安装TensorFlow和TensorRT,然后按照指导安装TF-TRT的插件,确保环境配置正确。
2.2 示例:
- TF-TRT 1.x工作流程与保存模型:通过加载已经保存的模型并应用TF-TRT进行优化。
- TF-TRT 1.x工作流程与冷冻图:处理冻结的图定义以实现优化。
- TF-TRT 1.x工作流程与元图和检查点文件:使用元图和模型的检查点进行优化和部署。
- TF-TRT 2.0工作流程与保存模型:针对TensorFlow 2.0的优化过程。
2.3 TF-TRT API在TensorFlow 1.x中的使用:介绍1.x版本中的接口和用法。
2.4 TF-TRT API在TensorFlow 2.0中的使用:描述了在新版本中如何调用和操作TF-TRT。
2.5 精度模式:包括FP32、FP16和INT8等不同精度设置,用于平衡性能和精度。
2.6 静态或动态模式:
- 缓存和变量批次大小:讨论了静态模式下固定批次大小和动态模式下可变批次大小的处理方式。
2.7 控制TensorRT子图的最小节点数:允许用户自定义优化的子图中至少包含多少个节点。
2.8 内存管理:讲解如何有效地管理内存资源,减少不必要的内存开销。
2.9 INT8量化:
- 后训练量化使用TensorRT校准:通过校准数据来确定量化参数,以保持模型精度。
- 后训练量化使用自定义量化范围:允许用户手动设定量化范围。
- 训练时量化:在训练过程中引入量化节点,以实现模型的量化感知训练。
- 添加量化节点的位置:指明在模型图中何处添加量化和去量化节点以进行量化训练。
此文档详尽地阐述了如何在实际项目中利用TensorRT优化TensorFlow模型,对于希望提升深度学习推理性能的开发者来说,是一份非常有价值的参考资料。"
Overview
Accelerating Inference In TensorFlow With TensorRT (TF-
TRT)
SWE-SWDOCTFT-001-INTG _v001|3
With the TensorFlow API, you can specify the minimum number of nodes in a subgraph for it to
be converted to a TensorRT node. Any sub-graph with less than the specified number of nodes
will not be converted to TensorRT engines even if it is compatible with TensorRT. This can be
useful for models containing small compatible sub-graphs separated by incompatible nodes,
in turn leading to tiny TensorRT engines.
1.3. TF-TRT Workflow
The following diagram shows the typical workflow in deploying a trained model for inference.
Figure1. Deploying a trained model workflow.
In order to optimize the model using TF-TRT, the workflow changes to one of the following
diagrams depending on whether the model is saved in SavedModel format or regular
checkpoints. Optimizing with TF-TRT is the extra step that is needed to take place before
deploying your model for inference.
Figure2. Showing the SavedModel format.
Figure3. Showing a Frozen graph.

剩余37页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-23 上传
2024-07-30 上传
2022-07-22 上传
2020-07-07 上传
2019-09-26 上传
2023-06-07 上传









