PyTorch进阶实践:Early Stop与Dropout策略
版权申诉
74 浏览量
更新于2024-09-10
收藏 584KB PDF 举报
PyTorch学习笔记(十五)主要探讨了两个关键概念:Early Stop和Dropout,以及它们在深度学习训练过程中的作用。
1. Early Stop:
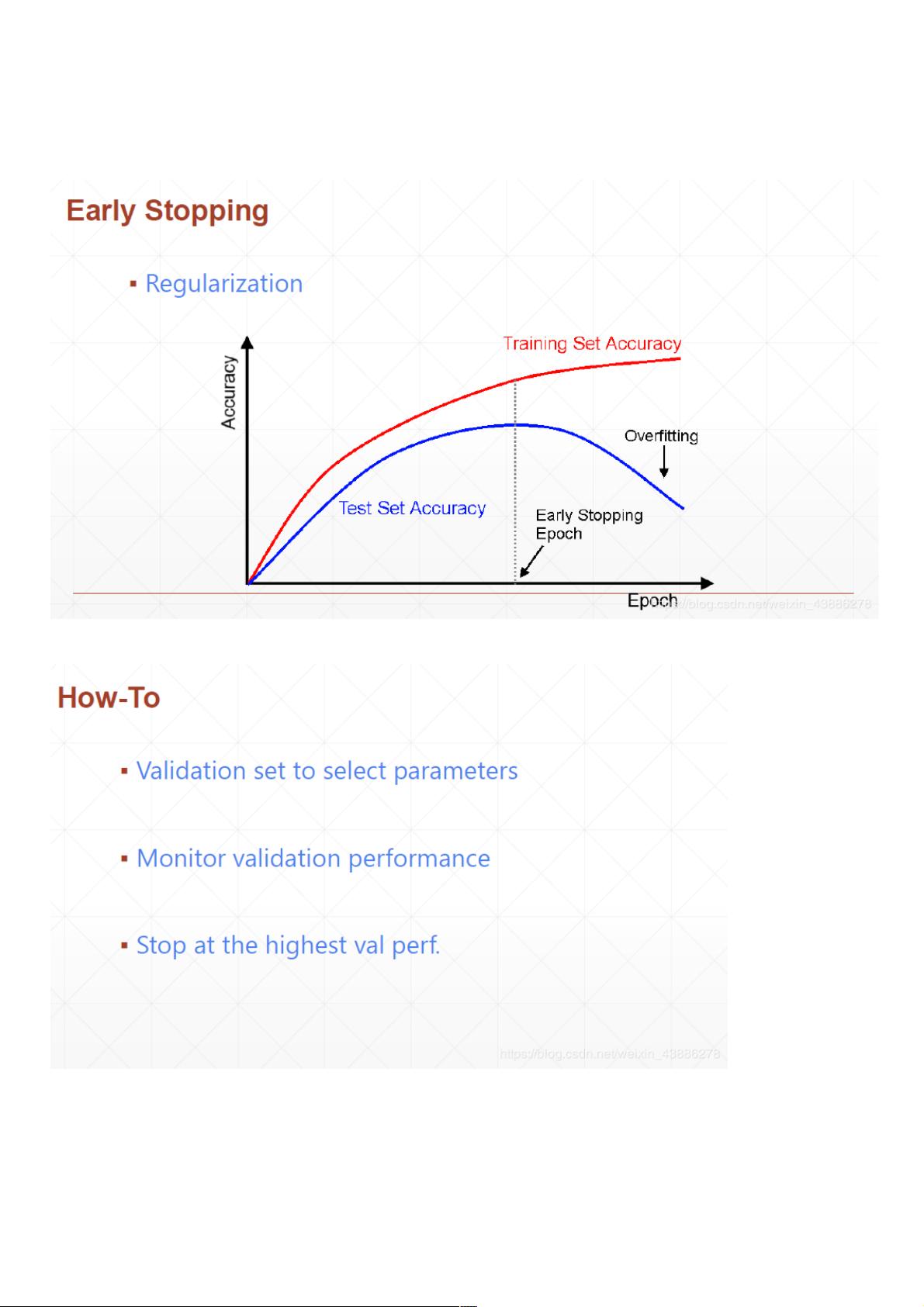
Early Stop是一种常用的正则化策略,旨在防止过拟合。在训练过程中,我们通常会在训练集上观察模型性能,然而过拟合可能导致模型在训练集上表现良好,但在未见过的测试集上性能较差。Early Stop的核心思想是在验证集上的性能达到最佳时停止训练,而不是等待训练集性能达到极致。这有助于确保模型具有更好的泛化能力,避免过拟合带来的问题。
实施Early Stop的过程包括定期评估模型在验证集上的性能,一旦发现验证集上的性能不再提升或开始下降,即停止训练。这需要设置一个验证周期,比如每N个epoch检查一次验证集性能,以便及时做出决策。
2. Dropout:
Dropout是一种强大的正则化技术,由Geoffrey Hinton于2012年提出。它旨在通过在训练过程中随机“丢弃”一部分神经元(或特征检测器)来防止过拟合。在每个训练批次中,Dropout会随机将一部分神经元的输出置为0,这样在每次前向传播时网络都会经历一种“弱连接”的状态,减少了特征之间的协同作用。
Dropout的机制促使神经网络学习到更为独立和鲁棒的特征表示,即使在没有其他神经元支持的情况下也能单独工作。这种策略在一定程度上模拟了数据增强的效果,因为每个神经元都需要学会如何在不同组合的特征下进行预测。Hinton及其团队在AlexNet中成功应用了Dropout,它在ImageNet比赛中的表现证明了其在深度学习模型中的有效性。
随后的研究进一步发展了Dropout理论,提出了更多优化方法和应用场景,如《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》等论文。Dropout成为了深度学习标准工具箱的一部分,对于提高模型泛化能力和稳定训练至关重要。
PyTorch学习笔记(十五)通过讲解Early Stop和Dropout,展示了如何在训练深度神经网络时有效地控制过拟合,从而提升模型的性能和泛化能力。理解和掌握这两个技术对于深入理解并实践深度学习至关重要。
pytorch学习笔记(十五)学习笔记(十五)————Early Stop,,Dropout
pytorch学习笔记(十五)学习笔记(十五)————Early Stop,,Dropout,,SGD目录Early StopDropoutSGD随机梯度下降
目录目录
Early Stop
(1)Early Stop的概念
Early Stop的概念非常简单,在我们一般训练中,经常由于过拟合导致在训练集上的效果好,而在测试集上的效果非常差。因此我们可以让训练
提前停止,在测试集上达到最好的效果时候就停止训练,而不是等到在训练集上饱和在停止,这个操作就叫做Early Stop。
(2)Early Stop的过程
Dropout
(1)Dropout的概念
下载后可阅读完整内容,剩余4页未读,立即下载
2021-05-10 上传
2021-01-20 上传
2021-01-06 上传
2020-11-10 上传
2021-01-06 上传
2020-11-07 上传
2020-11-08 上传
2020-11-08 上传
2020-11-09 上传

weixin_38739919
- 粉丝: 4
- 资源: 903
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
