Spark还是Flink?基于Kafka的实时计算引擎选型指南
49 浏览量
更新于2024-08-31
收藏 1.37MB PDF 举报
"选择基于Kafka的实时计算引擎:Spark与Flink对比分析"
在现代大数据处理领域,实时计算已经成为不可或缺的一部分。随着数据量的爆炸性增长,选择合适的实时计算引擎至关重要。Apache Spark和Apache Flink作为两个领先的实时计算引擎,各有特点和优势,适用于不同的业务场景。
1. Apache Spark概述
Apache Spark是一款通用的大数据处理框架,以其快速、易用和可扩展性著称。Spark提供了统一的API,支持批处理、交互式查询(Spark SQL)、图形处理和流处理(Spark Streaming)。Spark Streaming通过微批处理的方式实现流处理,即把数据流分割成小批次进行处理,适合对延迟要求不是很严格的场景。
2. Apache Flink概述
Apache Flink是一个专为流处理设计的实时计算引擎,同时支持批处理,但其核心优势在于流处理。Flink以其低延迟和状态管理能力见长,提供了一种真正意义上的持续计算模型,能处理无界数据流。Flink的DataStream API提供了强大的事件时间和窗口处理功能,使其在复杂实时分析任务中表现出色。
3. Spark与Flink的对比
- 延迟与吞吐量:Flink通常提供更低的延迟,因为它的设计目标就是高效处理流数据,而Spark Streaming由于微批处理模式,延迟相对较高。
- 状态管理:Flink在状态管理方面更强大,支持大规模状态存储和复杂的有状态计算,而Spark的状态管理相对简单,可能不适用于大型状态保持应用。
- 容错机制:两者都具备良好的容错性,但Flink的检查点机制更加精细,能够实现精确一次的状态一致性。
- 批流一体:Flink在批处理和流处理之间提供了更好的一致性,而Spark虽然也支持批流一体,但在批处理和流处理之间可能存在一些差异。
- 生态系统:Spark拥有丰富的生态系统,包括MLlib(机器学习)、GraphX(图处理)等,而Flink的生态正在快速发展,如Flink SQL和Table API等。
4. 选择指南
- 对于需要低延迟、高度可靠和复杂事件处理的场景,Flink可能是更好的选择,例如金融领域的欺诈检测、物联网设备的数据分析等。
- 如果业务对延迟要求不高,更注重易用性和现有的Spark生态集成,或者需要进行批处理和交互式查询,那么Spark可能是更合适的选择,特别是在已经使用Hadoop等Spark兼容环境的企业中。
- 在实际选择时,还需要考虑团队的技术栈、社区支持、维护成本等因素,确保所选技术能与现有架构无缝集成,并满足长期发展的需求。
基于Kafka的实时计算引擎选择,需根据具体业务需求、延迟要求、数据处理复杂性以及现有技术栈来权衡。无论是Spark还是Flink,都有其独特的优势,关键在于找到最符合业务需求的那个。
基于基于Kafka的实时计算引擎如何选择?的实时计算引擎如何选择?SparkorFlink
1. 前言
目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟。以 Spark 和 Flink 为首的实时计算引擎,成为实
时计算场景的重点考虑对象。那么,今天就来聊一聊基于 Kafka 的实时计算引擎如何选择? Spark or Flink?
2. 为何需要实时计算?
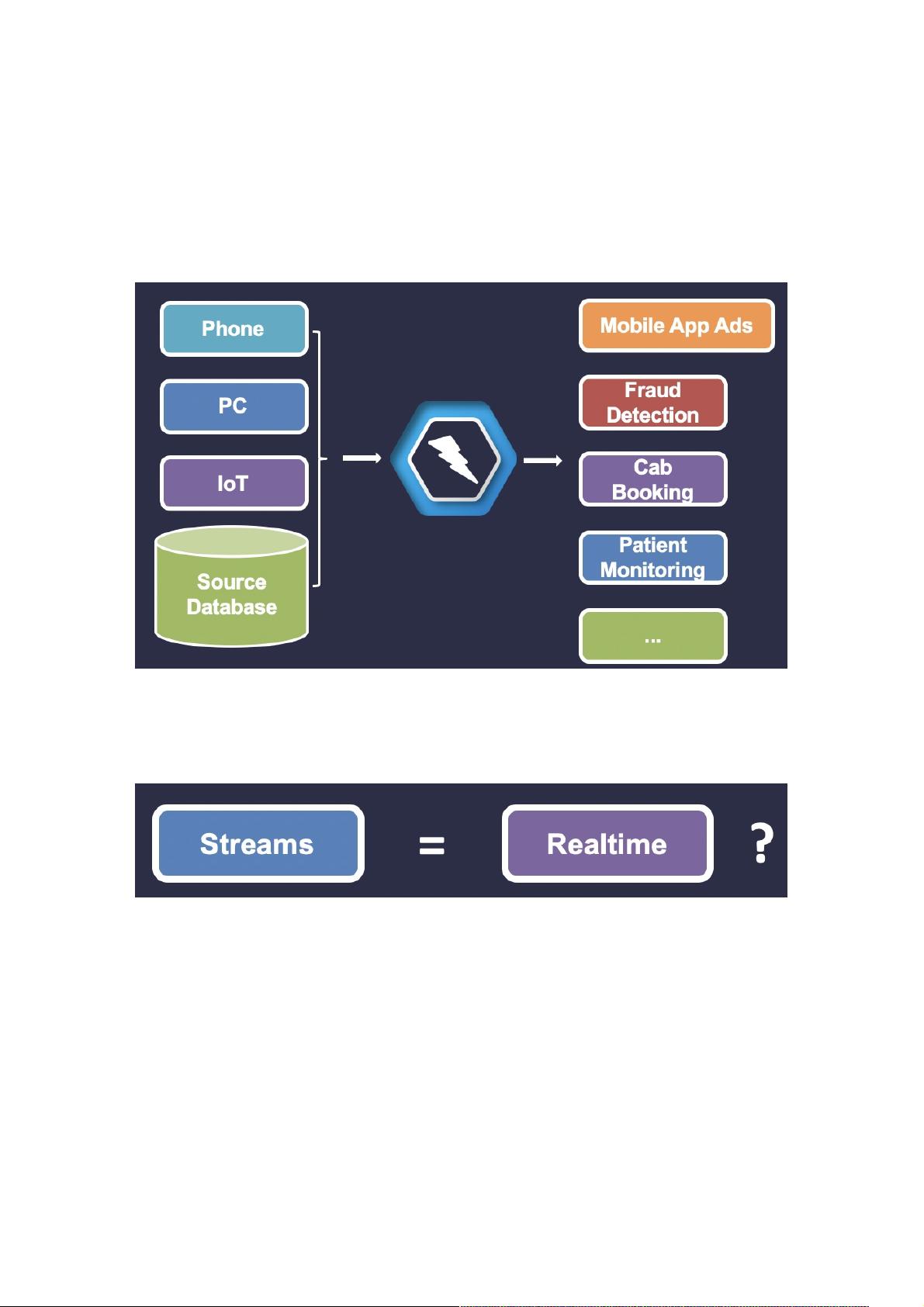
根据 IBM 的统计报告显示,过去两年内,当今世界上 90% 的数据产生源于新设备、传感器以及技术的出现,数据增长率也会
为此加速。而从技术上将,这意味着大数据领域,处理这些数据将变得更加复杂和具有挑战性。例如移动应用广告、欺诈检
测、出租车预订、患者监控等场景处理时,需要对实时数据进行实时处理,以便做出快速可行的决策。
目前业界有开源不少实时计算引擎,以 Apache 基金会的两款开源实时计算引擎最受欢迎,它们分别是 Apache Spark 和
Apache Flink 。接下来,我们来聊一聊它们的使用场景、优势、局限性、相似性、以及差异性。方便大家在做技术选型时,选
择切合项目场景的实时计算引擎。
2.1 如何理解流式与实时?
说起实时计算,可能会说到流式计算,那么流式和实时是否是等价的呢?严格意义上讲,它们没有必然的联系。实时计算代表
的是处理数据耗时情况,而流式计算代表的是处理数据的一种方式。
2.2 什么是流式处理?
首先,它是一种数据处理引擎,其设计时考虑了无边界的数据集。其次,它与批处理不同,批处理的 Job 与数据的起点和终
点有关系,并且 Job 在处理完有限数据后结束,而流式处理用于处理连续数天、数月、数年、或是永久实时的无界数据。
流处理的特点:
容错性:如果节点出现故障,流式处理系统应该能够恢复,并且应该从它离开的位置再次开始处理;
状态管理:在有状态处理要求的情况下,流式处理系统应该能够提供一些机制来保存和更新状态信息;
性能:延时应尽可能的小,吞吐量应尽可能的大;
高级功能:事件时间处理,窗口等功能,这些均是流式处理在处理复杂需求时所需要的功能;
2.3 什么时候适合流式处理?
流式处理可以分析连续的数据流,在这种方式中,数据被视为连续流,处理引擎在很短的时间内 ( 几毫米到几分钟 ) 内取数、
下载后可阅读完整内容,剩余5页未读,立即下载
2018-06-21 上传
2023-02-27 上传
点击了解资源详情
2023-05-09 上传
2023-07-16 上传
2024-04-20 上传
2023-06-18 上传
2023-06-18 上传
2023-06-18 上传

weixin_38544075
- 粉丝: 10
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







