探究ChatGPT能力崛起:大规模预训练的秘密
需积分: 3 198 浏览量
更新于2024-06-25
收藏 806KB PDF 举报
本文深入探讨了OpenAI的ChatGPT各项能力的起源,尤其是GPT-3.5模型系列及其背后的技术发展。初代GPT-3在2020年展示出三项关键特性:语言生成、上下文学习和世界知识。语言生成是指模型能够根据提示词生成连贯的句子,这是用户与模型交互的基础。上下文学习则是指模型能够在理解给定任务示例后,解决新的相关问题,显示了其超越传统语言模型的智能水平。
GPT-3的核心并非传统的语言建模,而是着重于对上下文的理解和应用。这一创新使得模型能够在不明确告知特定算法的情况下,通过学习大量文本数据中的模式,展现出惊人的解决问题能力。世界知识包括事实性和常识性信息,这些也是通过海量文本数据的预训练获得的,模型从中吸收了广泛的知识领域。
大规模预训练是ChatGPT强大能力的关键,它利用了多达3000亿单词的语料库进行训练,使得模型能够理解和处理复杂的语言结构,同时具备跨领域的知识整合能力。通过这种方法,模型不仅积累了丰富的词汇量,还学会了关联不同主题,从而展现出令人印象深刻的多任务处理性能。
然而,文章指出,尽管ChatGPT在国际上引起了广泛关注,但在国内的研究和应用上,与国际主流机构如斯坦福大学、伯克利加州大学和谷歌大脑、微软研究院相比,还存在一定的差距。如果不及时跟进,可能会导致技术上的断层。因此,文章呼吁国内学术界和产业界应积极参与到开放源代码的共享和研究中,共同探索和提升大型语言模型的透明度和性能。
ChatGPT的各项能力源于其背后的深度学习技术和大规模预训练策略,这是一项里程碑式的成果。理解其技术路线图对于推动人工智能领域的发展至关重要,尤其是在当前全球科技竞争的背景下,中国需要积极应对,以免错失技术进步的良机。
一个足够好的开源的近似模型了(根据 OPT 论文和斯坦福大学的 HELM 评
估)。
虽然初代的 GPT-3 可能表面上看起来很弱,但后来的实验证明,初代 GPT-
3 有着非常强的潜力。这些潜力后来被代码训练、指令微调 (instruction
tuning) 和 基 于 人 类 反 馈 的 强 化 学 习 (reinforcement learning with
human feedback, RLHF) 解锁,最终体展示出极为强大的突现能力。
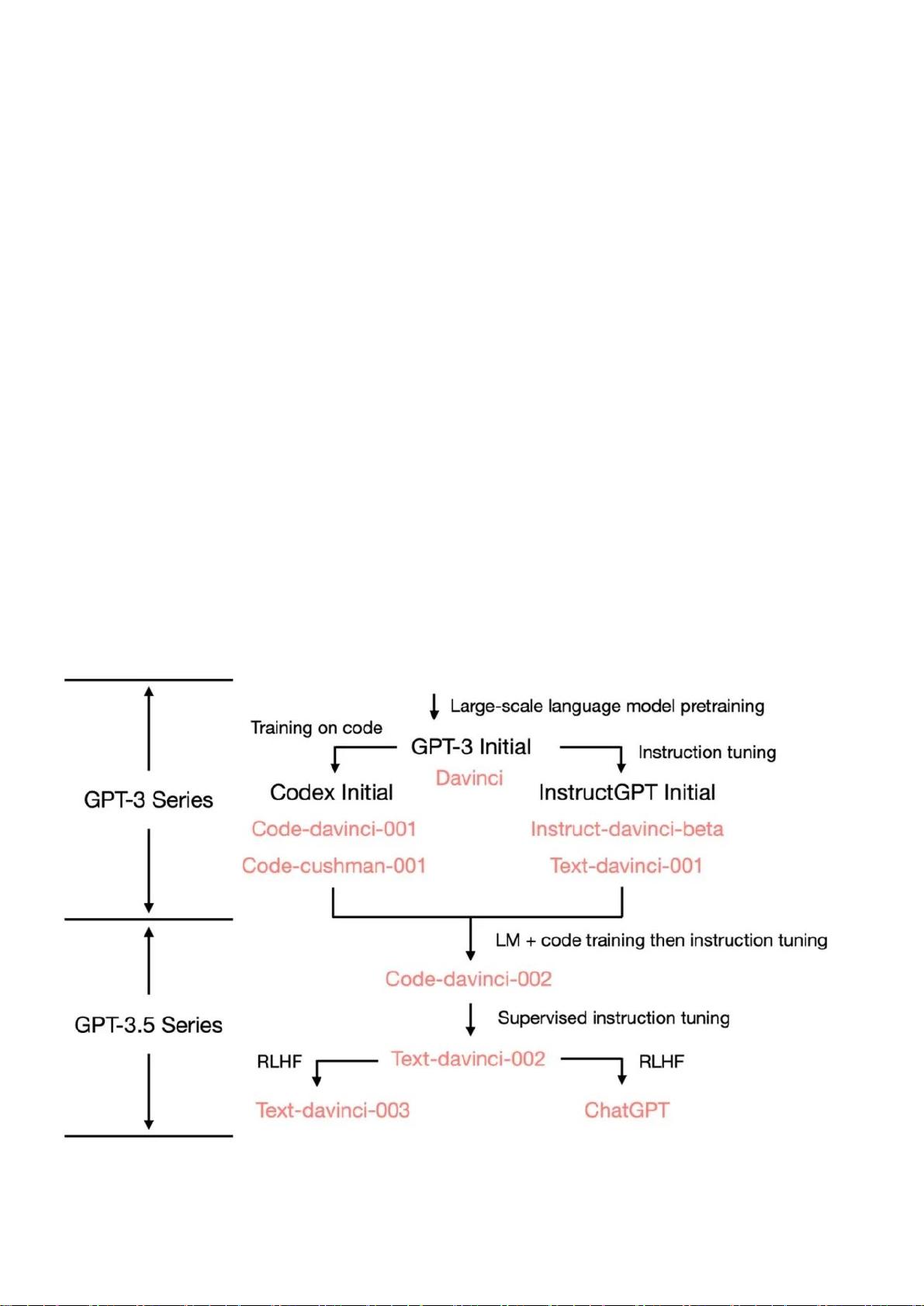
二、从2020版GPT-3到2022版ChatGPT
从最初的 GPT-3 开始,为了展示 OpenAI 是如何发展到ChatGPT的,我们
看一下 GPT-3.5 的进化树:
剩余19页未读,继续阅读
881 浏览量
点击了解资源详情
点击了解资源详情
2023-05-26 上传
114 浏览量
190 浏览量
144 浏览量
432 浏览量
782 浏览量

IT徐师兄
- 粉丝: 2482
- 资源: 2862
 我的内容管理
展开
我的内容管理
展开







最新资源
- vue-tailwind
- ExcelMapsV2.7.12.0.rar
- 身份验证-Cookie-会话-Oauths-Google-Facebook-
- Ringfit2GoogleFit
- 自动化技术在电子信息工程设计中的应用研究 (1).rar
- microblog-master-nodeJS:microblog-master-nodeJS
- day1plus.zip
- libbgi.a、BIOS.H和graphics.h
- 快速键盘
- AlgorithmStudy
- 自动化码头作业区域人员进出安全管控.rar
- rn_flappy_bird
- deckor:交互式解码器
- 微信小程序canvas实现文字缩放
- Simple Click Counter-crx插件
- eWOW64Ext v1.1 - 加载任意 32/64 模块|64 位汇编及进程读写-易语言
