MapReduce基础搭建与Java API详解:HDFS与YARN框架
需积分: 14 95 浏览量
更新于2024-07-02
1
收藏 4.15MB DOCX 举报
MapReduce的基础搭建与Java API编程涵盖了大数据处理中的一项关键技术,即Apache Hadoop生态系统的核心组成部分。Hadoop作为一个分布式基础架构,旨在简化开发者在大规模数据处理中的编程复杂性,使得用户无需深入了解分布式系统的底层细节,即可高效地利用集群资源。
首先,我们从Hadoop的发展背景说起。Hadoop起源于2005年,由Apache Software Foundation发起,最初作为Nutch项目的一部分,受到了Google的MapReduce和Google File System (GFS) 的启发。MapReduce是一种并行计算模型,它允许用户编写简单的Map和Reduce函数,以处理大量数据,实现了数据的高效分发和处理。这种模型有效地解决了大数据处理中的计算负载均衡问题。
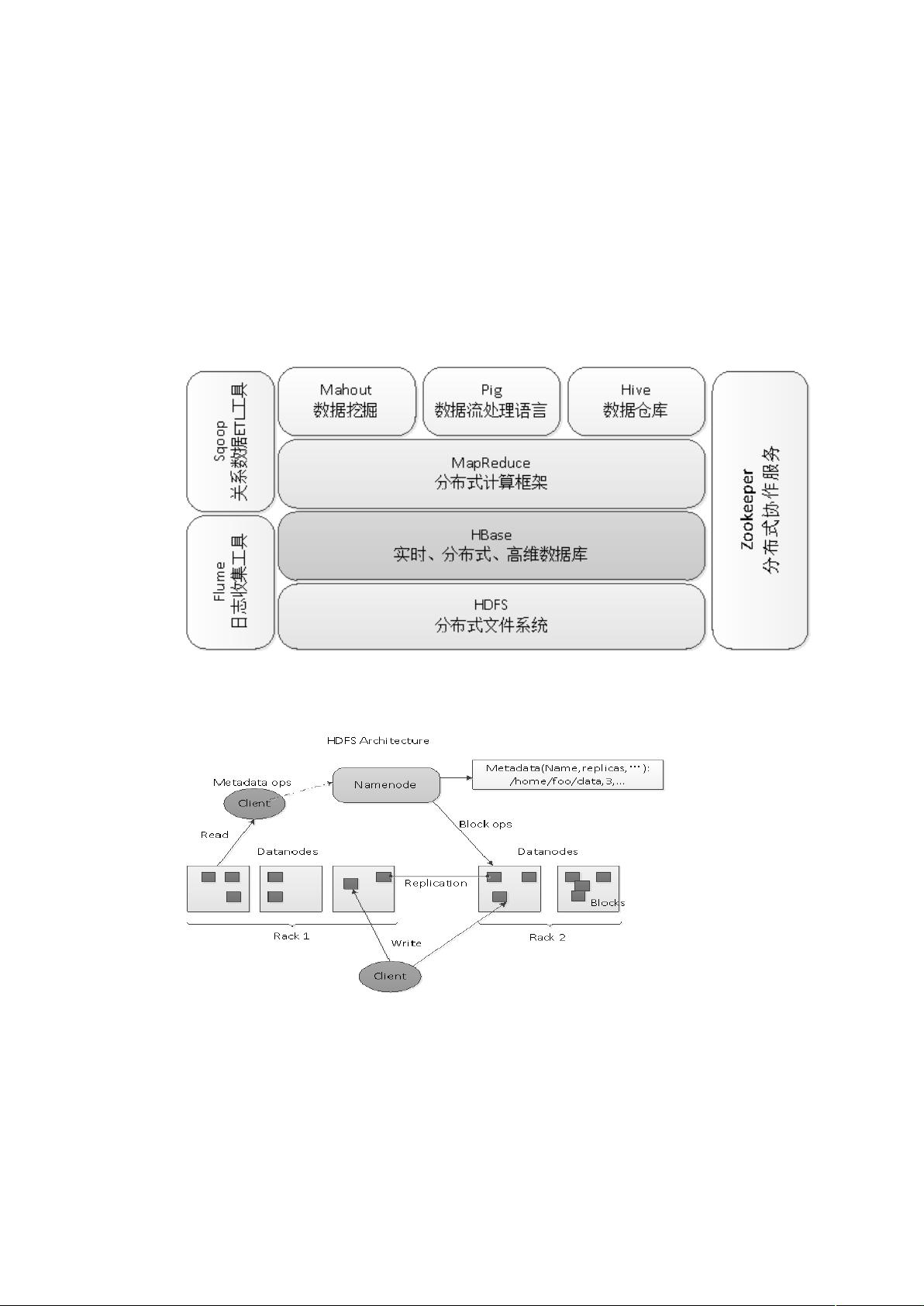
HDFS (Hadoop Distributed File System) 是Hadoop的核心组件之一,它实现了分布式文件系统,让用户能够在Hadoop集群上像操作单机一样存储和访问数据。尽管数据实际上分布在多台机器上,但HDFS提供了一致性、高可用性和容错性的特性,极大地提高了数据的可靠性和性能。
MapReduce框架本身是Hadoop的另一个核心,它支持用户编写并行任务,如查找特定模式或执行聚合操作。当用户提交MapReduce任务时,这些任务会被自动分解并在集群的不同节点上并行执行,大大加快了处理速度。随着Hadoop的版本升级,YARN (Yet Another Resource Negotiator) 出现,作为资源管理和调度器,它负责管理和分配集群的硬件资源,包括内存和CPU,并且支持多种计算框架,如Spark和Storm,使得Hadoop平台更加灵活和可扩展。
学习MapReduce的基础搭建和Java API编程,你需要掌握以下几个关键点:
1. **Hadoop体系结构**:理解Hadoop的组成,包括HDFS作为分布式存储系统,MapReduce作为处理框架,以及YARN作为资源管理和调度器的角色。
2. **MapReduce工作流程**:学会编写Map和Reduce函数,理解它们在数据处理中的作用,以及Shuffle和Sort阶段如何保证数据的正确分发。
3. **HDFS操作**:熟悉文件的创建、读取、写入和删除,以及副本策略和数据块的分布。
4. **Java API应用**:如何使用Hadoop的Java API进行文件系统操作和MapReduce任务编写,包括配置和提交任务。
5. **资源管理和监控**:了解如何使用YARN监控和优化资源使用,确保任务的有效调度和性能优化。
通过深入学习和实践,你将能够熟练地在Hadoop平台上进行大数据处理,为实际项目开发打下坚实的基础。

支持 /)-0样式的文件系统扩展属性。有关更多详细信息,请
参阅用户文档。
使用 )D!08!,客户端现在可以通过 A+,-
/0 浏览图像。
6,-网关获得了许多可支持性改进和错误修复。运行网关不再
需要 端口映射器,网关现在能够拒绝来自非特权端口的连
接。
-166 , 6 和 +6A
0 已经使用 @5 和 #"! 进行了现代化改造。
326的 2*-@/0现在支持写入9修改操作。用户可以通过
2*-@/0提交和终止应用程序。
326中的时间轴存储用于存储应用程序的通用和特定于应用
程序的信息,支持通过 E"进行身份验证。
,!-$ 支持动态分层用户队列,用户队列是在运行时
在任何指定的父队列下动态创建的。
2.3.2.Hadoop 构成:
由 许 多 元 素 构 成 , 其 最 底 部 是 +,- , 它 存 储

剩余63页未读,继续阅读
2966 浏览量
275 浏览量
点击了解资源详情
151 浏览量
109 浏览量
521 浏览量
221 浏览量
点击了解资源详情
点击了解资源详情

Sc散场
- 粉丝: 76
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 电子功用-数字电流模控制Boost变换器的建模及稳定性分析方法
- java-grok:简单的API,可让您轻松解析日志和其他文件
- SpaceShooter:简单的C ++ SFML库游戏
- GOO
- MATLAB 遍历算法
- 建立一流的以创新为导向的业务计划、营销和供应链管理体系
- 一站式工作
- 辽宁工程技术大学计算机类专业课程《数据结构》授课PPT课件+实例代码+上机实验+期末复习题(含答案)
- 供应链计划及排程技术与市场全球透视
- BattleTank:开放世界,面对面的坦克大战。 在虚幻4中
- C++写的贪吃蛇游戏
- portfolio-source:我的投资组合网站的源代码
- 树莓派智能小车 循迹 超声波避障 红外避障 红外追踪 遥控小车代码.zip
- 使用 MATLAB 为风电场制作动画:添加现实主义:演示中添加了现实主义-matlab开发
- Juicy.Voxels:Haskell中的卷文件加载器(PVMGifimage列表)
- 供应链管理原理及应用
