大规模管理Apache Spark集群的经验教训
需积分: 5 135 浏览量
更新于2024-06-21
收藏 576KB PDF 举报
"藏经阁-Lessons Learned From Managing.pdf 是一份关于在大规模环境中管理Apache Spark集群的经验分享,由阿里云关联的Databricks团队成员Josh Rosen和Henry Davidge撰写。文档介绍了他们在管理大量Spark集群时遇到的挑战、Databricks的产品特性以及其使命,并深入探讨了监控和数据管道方面的问题。"
这篇文档的核心知识点包括:
1. **Apache Spark与Databricks**: Josh Rosen是Apache Spark的提交者,自2012年起就参与贡献。Databricks作为Spark项目(现在是Apache Spark)的发起者,于2009年在加州大学伯克利分校创立,致力于简化大数据处理。其产品是一个统一的大数据分析平台。
2. **管理挑战**: 在Databricks中,由于存在大量不同配置和版本的Spark集群,以及客户可以在自己的集群上运行任意代码,系统复杂性显著增加。此外,与云提供商的深度集成也带来了额外的管理难题。
3. **监控问题**: Databricks需要处理大量的监控指标,如每分钟来自Databricks自身的30万+个指标和来自客户的200万+个指标,以及每秒200+MB的日志数据。这种规模对监控系统提出了极高要求。
4. **Databricks架构**: 控制平面位于Databricks的AWS账户中,而Spark集群则在客户的AWS账户中运行。这种架构允许Databricks服务响应客户创建、配置和终止集群的请求。
5. **数据管道**: Databricks的服务产生三种数据流:快速路径指标、丰富的结构化日志和非结构化数据。这些数据流对于理解系统的运行状态和进行故障排查至关重要。
6. **监控策略**: 针对海量的监控数据,可能需要建立高效的数据收集、存储和分析机制,以确保能够及时发现并解决问题。这可能涉及到使用分布式日志收集工具(如Fluentd或Logstash)、时间序列数据库(如InfluxDB)和可视化工具(如Grafana)。
7. **集群管理和优化**: 在大规模集群管理中,可能会涉及自动化部署、资源调度优化、性能调优以及安全和合规性的考虑。这需要深入理解Spark的内部工作原理以及与云环境的交互方式。
8. **客户支持与服务**: 由于客户可以运行任意代码,Databricks可能需要提供强大的客户支持和服务,以帮助客户解决可能出现的复杂问题,同时保证系统的稳定性和安全性。
总结来说,"藏经阁-Lessons Learned From Managing.pdf"提供了有关如何在大规模生产环境中有效管理和监控Apache Spark集群的宝贵经验,对于在类似场景下工作的数据工程师和技术团队具有很高的参考价值。
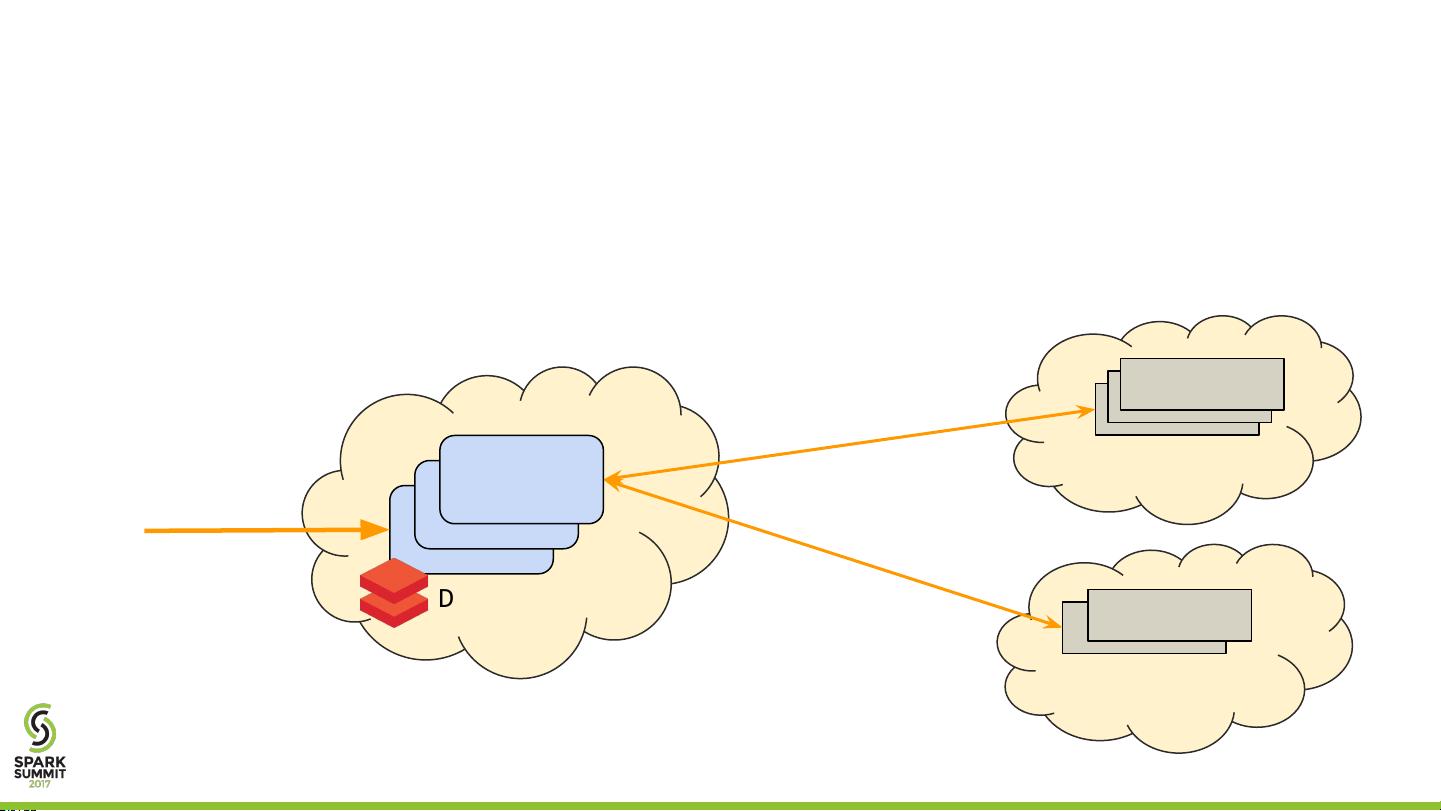
Background: Databricks Architecture
• Control plane in our AWS account
• Spark clusters in customer’ AWS accounts
Databricks
Create
Configure
Terminate
Customer 1
Customer 2
Cluster
Cluster
Cluster
Cluster
Cluster
service
service
service
customer
requests
剩余23页未读,继续阅读
2023-08-28 上传
2023-08-26 上传
2023-09-05 上传
2021-06-25 上传
2023-08-26 上传
2022-09-24 上传
2020-06-07 上传

weixin_40191861_zj
- 粉丝: 86
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







