HDFS详解:理论与Linux Shell操作实践指南
需积分: 7 22 浏览量
更新于2024-07-09
收藏 8.61MB DOCX 举报
第3章深入探讨了分布式文件系统Hadoop Distributed File System (HDFS)的相关理论和实践。HDFS是大数据处理中不可或缺的一部分,它是一个高容错、高吞吐量的分布式文件系统,特别适合于大规模数据集的存储和处理。本章的核心知识点包括:
1. **分布式文件系统基础**:介绍了分布式文件系统的概念,即文件被分割成多个副本并存储在不同的节点上,以提供数据的冗余和高可用性。
2. **HDFS简介**:讲述了HDFS的设计目标,即支持大规模数据集的高效读写,以及其在云计算环境中的角色。
3. **HDFS体系结构**:涵盖了NameNode(元数据管理)和DataNode(数据块存储)的角色,以及它们之间的交互机制。
4. **存储原理**:详细阐述了HDFS的数据分块策略、副本策略以及Block和Checksum的概念,确保数据的可靠性和一致性。
5. **数据读写过程**:解释了客户端如何通过NameNode获取文件块位置,以及如何执行读写操作,包括数据的复制、读取和写入流程。
6. **Linux Shell命令实践**:介绍了在Linux环境下使用Hadoop的常用Shell命令,如`hadoopfs`、`start-dfs.sh`,以及创建用户目录等基础操作。
7. **命令行工具的多样性**:区分了`hadoopfs`、`hadoopdfs`和`hdfsdfs`的不同用法,强调了在不同场景下的选择。
8. **目录操作**:强调了首次使用HDFS时创建用户目录的重要性,并提供了相应的命令示例。
9. **命令查询**:演示了如何通过`hadoopfs-help`命令查询HDFS命令的使用方法,便于进一步学习和熟悉Hadoop的命令集。
学习这一章节,不仅需要理解理论框架,还要通过实践操作熟练掌握HDFS的管理和操作,这对于理解和应用大数据技术至关重要。建议参考林子雨编著的《大数据技术原理与应用》第三章进行深入学习。

可以使用如下命令,到本地文件系统查看下载下来的文件 myLocalFile.txt:
1. $ cd ~
2. $ cd 下载
3. $ ls
4. $ cat myLocalFile.txt
Shell 命令
最后,了解一下如何把文件从 HDFS 中的一个目录拷贝到 HDFS 中的另外一个
目录。比如,如果要把 HDFS 的“/user/hadoop/input/myLocalFile.txt”文件,拷
贝到 HDFS 的另外一个目录“/input”中(注意,这个 input 目录位于 HDFS 根目
录下),可以使用如下命令:
1. ./bin/hdfs dfs -cp input/myLocalFile.txt /input
Shell 命令
二、利用 Web 界面管理 HDFS
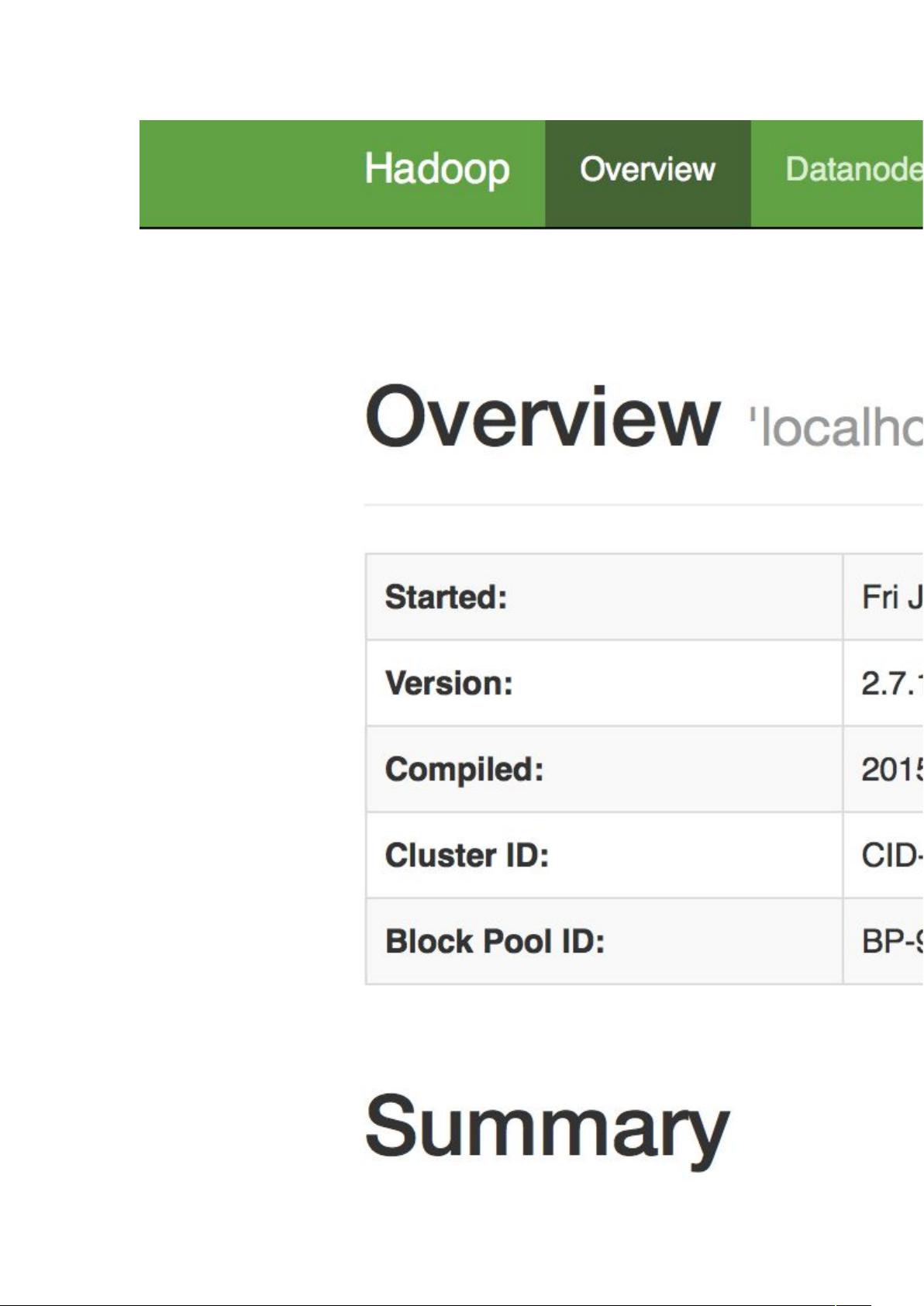
打开 Linux 自带的 Firefox 浏览器,点击此链接 HDFS 的 Web 界面,即可看到
HDFS 的 web 管理界面
剩余43页未读,继续阅读
点击了解资源详情
点击了解资源详情
122 浏览量
589 浏览量
342 浏览量
226 浏览量
205 浏览量
4632 浏览量
146 浏览量

PrettyFairy
- 粉丝: 15
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 微机接口技术及其应用课后习题答案
- Windows网络基本测试手段
- struts_2_design_and_programming_a_tutorial_2nd.7142682776
- vc++算法示例10个饿
- IBM Portal
- 《C++Builder6.0界面开发实例》
- Domino故障分析及处理方法
- JSP详细开发环境的配置
- Advanced UNIX Programming .pdf
- MyEclipse 6 Java EE 开发中文手册
- 基于MC56F8013的无刷直流电机调速控制器设计
- c++builder 实例精讲
- WCDMA核心网技术
- dos入门教程,基础篇
- 华南理工2007研究生入学考试试卷
- pl/sql学习文档
