揭秘Hadoop分布式计算框架:原理、架构与高可用性
分布式计算框架Hadoop是Apache软件基金会开发的重要工具,用于大规模并行处理和分布式文件存储。其主要由Hadoop Common、Hadoop Distributed File System (HDFS) 和 MapReduce 架构组成。
Hadoop Common是Hadoop的基础模块,提供了一套通用的库和服务,如I/O操作、加密、压缩等,使得开发者能够轻松地构建分布式应用程序。HDFS是Hadoop的核心组件,它是一个分布式文件系统,特别适合于存储大量数据和高吞吐量的应用场景。HDFS的设计基于master-slave架构,其中NameNode作为主节点,负责管理文件系统的元数据,如文件结构、block信息和DataNode位置,确保数据的一致性和可靠性。DataNode则是从属节点,负责实际的数据存储和处理,每个DataNode可以存储多个block块的副本,实现数据冗余和容错。
MapReduce是Hadoop的另一个关键组件,它是一种编程模型,允许用户编写处理大规模数据集的并行程序,通过将任务分解为一系列可独立执行的map和reduce阶段来简化编程。MapReduce确保了数据在分布式集群中的高效处理,即使数据分布在不同的节点上,也能进行有效的数据划分和合并。
HDFS的写入过程涉及Client向NameNode请求数据节点信息,将文件分割成block块并写入,而读取则通过NameNode获取block块信息和DataNode位置。为了提高数据可靠性,HDFS的每个block块都会创建多个副本,数量可以根据配置调整,这有助于在单个DataNode故障时仍能保证数据的完整性和可用性。
Hadoop分布式计算框架通过其高效的架构设计和组件协同,实现了大规模数据处理和存储,适用于各种大数据处理场景,如日志分析、搜索引擎、推荐系统等。学习和理解Hadoop原理及架构对于数据科学家、开发者和运维人员来说,都是非常重要的技能。
分布式计算框架分布式计算框架Hadoop原理及架构全解原理及架构全解
Hadoop是Apache软件基金会所开发的并行计算框架与分布式文件系统。最核心的模块包括Hadoop Common、HDFS与
MapReduce。HDFSHDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了
底层支持。采用Java语言开发,可以部署在多种普通的廉价机器上,以集群处理数量积达到大型主机处理性能。HDFS 架构
原理HDFS采用master/slave架构。一个HDFS集群包含一个单独的NameNode和多个DataNode。NameNode作为master服
务,它负责管理文件系统的命名空间和客户端对文件的访问。NameNode会保存文件系统的具体信息,包括文件信息、文件
被分割成具体block块的信息、以及每一个block块归属的DataNode的信息。对于整个集群来说,HDFS通过NameNode对用户
提供了一个单一的命名空间。DataNode作为slave服务,在集群中可以存在多个。通常每一个DataNode都对应于一个物理节
点。DataNode负责管理节点上它们拥有的存储,它将存储划分为多个block块,管理block块信息,同时周期性的将其所有的
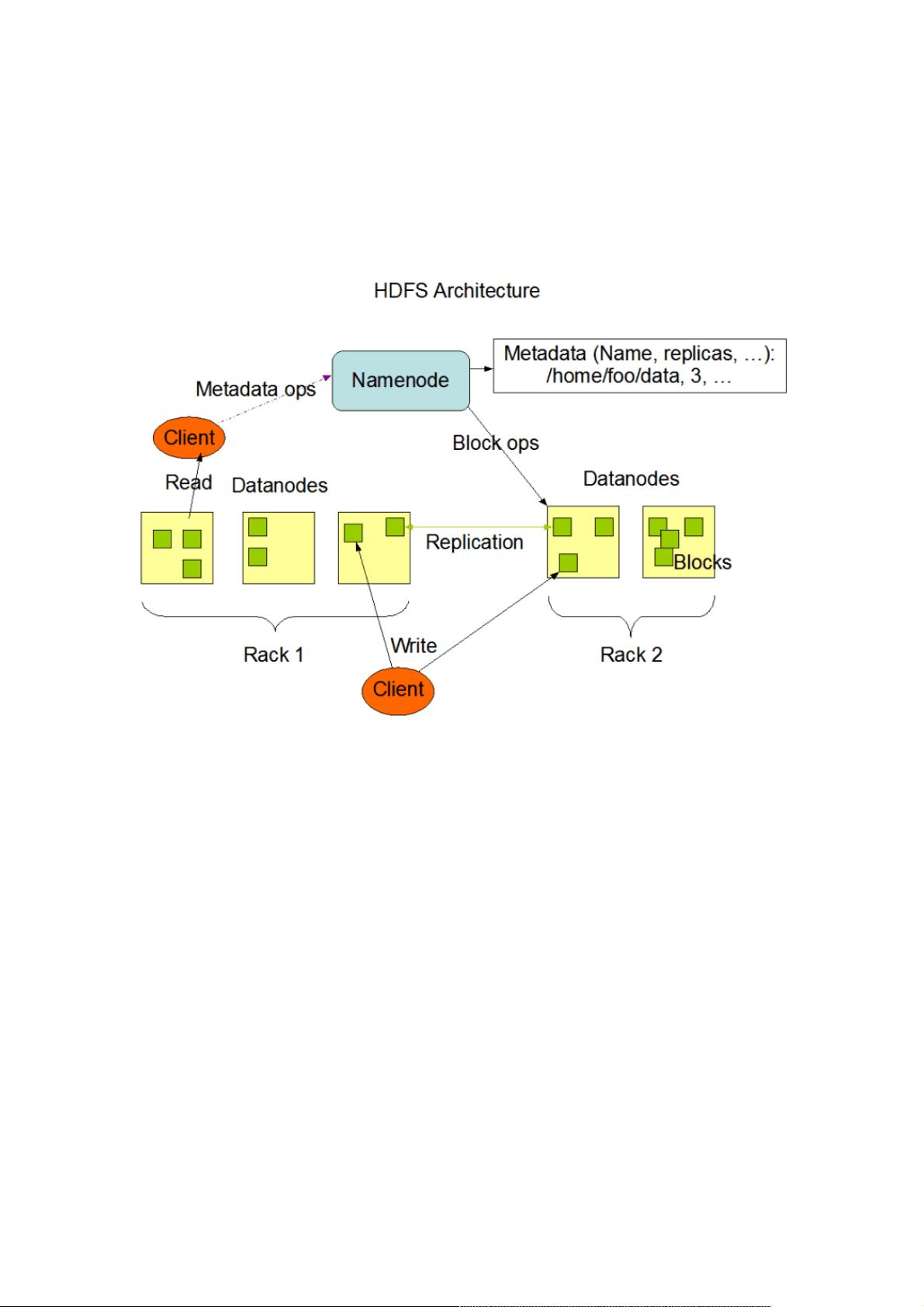
block块信息发送给NameNode。下图为HDFS系统架构图,主要有三个角色,Client、NameNode、DataNode。
文件写入时:Client向NameNode发起文件写入的请求。NameNode根据文件大小和文件块配置情况,返回给Client它所管理
部分DataNode的信息。Client将文件划分为多个block块,并根据DataNode的地址信息,按顺序写入到每一个DataNode块
中。当文件读取:Client向NameNode发起文件读取的请求。NameNode返回文件存储的block块信息、及其block块所在
DataNode的信息。Client读取文件信息。HDFS 数据备份HDFS被设计成一个可以在大集群中、跨机器、可靠的存储海量数据
的框架。它将所有文件存储成block块组成的序列,除了最后一个block块,所有的block块大小都是一样的。文件的所有block
块都会因为容错而被复制。每个文件的block块大小和容错复制份数都是可配置的。容错复制份数可以在文件创建时配置,后
期也可以修改。HDFS中的文件默认规则是write one(一次写、多次读)的,并且严格要求在任何时候只有一个writer。
NameNode负责管理block块的复制,它周期性地接收集群中所有DataNode的心跳数据包和Blockreport。心跳包表示
DataNode正常工作,Blockreport描述了该DataNode上所有的block组成的列表。
下载后可阅读完整内容,剩余3页未读,立即下载
2018-02-26 上传
点击了解资源详情
2019-01-07 上传
2007-08-13 上传
2019-01-18 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38635449
- 粉丝: 5
- 资源: 971
 我的内容管理
展开
我的内容管理
展开







