Prometheus监控与Grafana展示实战教程
需积分: 10 136 浏览量
更新于2024-07-18
收藏 4.31MB PDF 举报
"Prometheus Up and Running 是一本深入介绍Prometheus监控系统及其配套工具Grafana的教程。这本书提供了一条清晰的学习路径,从基础知识到实际应用,帮助读者理解和掌握Prometheus的全貌。"
在《Prometheus Up and Running》中,作者首先介绍了监控的重要性,监控是现代软件系统不可或缺的一部分,它有助于及时发现并解决问题,确保服务的稳定运行。书中通过简短的历史回顾,展示了监控技术的发展,从而引出Prometheus这个时下流行的开源监控解决方案。
Prometheus的架构设计是其核心优势之一。书中详细讲解了Prometheus的工作方式,包括客户端库、导出器、服务发现、抓取数据、存储、仪表板、记录规则、警报管理等关键组件。Prometheus采用时间序列数据库,支持高效的查询和分析,并允许用户通过配置规则定义报警条件,实现自动化的问题发现。
在实际操作部分,读者将学习如何启动Prometheus服务器,使用表达式浏览器进行数据查询,以及通过NodeExporter监控节点状态。此外,书中还涉及了Alertmanager的设置,用于处理和传递警报,确保及时响应系统异常。
第二部分主要围绕应用监控展开,介绍了如何对代码进行合适的度量(Instrumentation)。书中通过示例程序讲解了计数器、 Gauge、Summary和Histogram等不同类型的指标,以及如何在各种编程语言如Python、Go、Java中实现这些度量。特别强调了度量命名的重要性,以及如何权衡度量的数量和粒度,以达到最佳监控效果。
第三部分则探讨了如何将这些度量暴露(Exposition)出来,让Prometheus能够收集。书中涵盖了多种服务器框架和语言的集成方法,如Python的WSGI和Twisted,Go的HTTP服务器,Java的Servlet,以及Pushgateway的使用,使得各种应用程序都能够与Prometheus无缝对接。同时,书里还详细讲解了Prometheus的exposition格式、指标类型、标签以及相关的编码规则。
《Prometheus Up and Running》是一本全面的教程,不仅适合初学者了解Prometheus和Grafana的基础知识,也适合有一定经验的开发者深入学习监控系统的高级用法,提升运维效率。
Prometheus has integrations with many common service discovery mechanisms, such as Kubernetes, EC2,
and Consul. There is also a generic integration for those whose setup is a little off the beaten path (see
“File”).
This still leaves a problem though. Just because Prometheus has a list of machines and services doesn’t
mean we know how they fit into your architecture. For example, you might be using the EC2 Name tag
6
to
indicate what application runs on a machine, whereas others might use a tag called app .
As every organisation does it slightly differently, Prometheus allows you to configure how metadata from
service discovery is mapped to monitoring targets and their labels using relabelling.
Scraping
Service discovery and relabelling give us a list of targets to be monitored. Now Prometheus needs to fetch
the metrics. Prometheus does this by sending a HTTP request called a scrape. The response to the scrape is
parsed and ingested into storage. Several useful metrics are also added in, such as if the scrape succeeded
and how long it took. Scrapes happen regularly; usually you would configure it to happen every 10 to 60
seconds for each target.
PULL VERSUS PUSHPrometheus is a pull-based system. It decides when and what to scrape, based on its
configuration. There are also push-based systems, where the monitoring target decides if it is going to be
monitored and how often.There is vigorous debate online about the two designs, which often bears
similarities to debates around Vim versus EMACS. Suffice to say both have pros and cons, and overall it
doesn’t matter much.As a Prometheus user you should understand that pull is ingrained in the core of
Prometheus, and attempting to make it do push instead is at best unwise.
Storage
Prometheus stores data locally in a custom database. Distributed systems are challenging to make reliable,
so Prometheus does not attempt to do any form of clustering. In addition to reliability, this makes
Prometheus easier to run.
Over the years, storage has gone through a number of redesigns, with the storage system in Prometheus
2.0 being the third iteration. The storage system can handle ingesting millions of samples per second,
making it possible to monitor thousands of machines with a single Prometheus server. The compression
algorithm used can achieve 1.3 bytes per sample on real-world data. An SSD is recommended, but not
strictly required.
Dashboards
Prometheus has a number of HTTP APIs that allow you to both request raw data and evaluate PromQL
queries. These can be used to produce graphs and dashboards. Out of the box, Prometheus provides the
expression browser. It uses these APIs and is suitable for ad hoc querying and data exploration, but it is not a
general dashboard system.
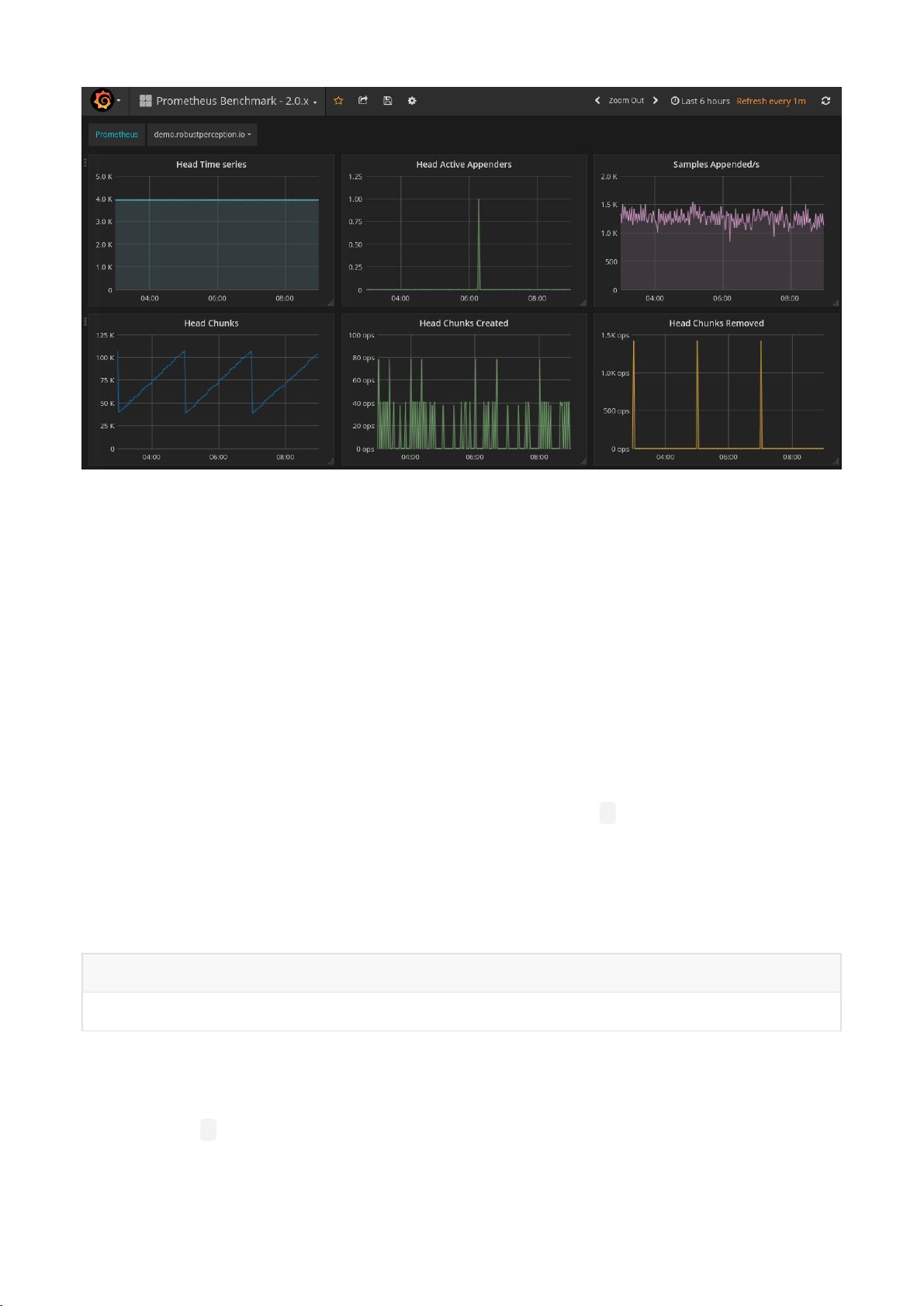
It is recommended that you use Grafana for dashboards. It has a wide variety of features, including official
support for Prometheus as a data source. It can produce a wide variety of dashboards, such as the one in
Figure 1-2. Grafana supports talking to multiple Prometheus servers, even within a single dashboard panel.
Figure 1-2. A Grafana dashboard

剩余278页未读,继续阅读
2019-03-17 上传
2019-01-17 上传
2018-07-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情









