【Basics】Getting Started with the Scrapy Web Scraping Framework: Structure and Basic Usage
发布时间: 2024-09-15 12:09:13 阅读量: 65 订阅数: 38 

Getting started with Spring Framework: covers Spring 5(epub)
# 1. Introduction to Scrapy: Framework and Basic Usage
Scrapy is a powerful Python framework designed for web scraping. It offers a comprehensive set of tools and components that allow developers to build scrapers with ease and efficiency. Scrapy's features include:
- **Ease of Use:** Scrapy has an intuitive and user-friendly API, enabling developers to get started quickly.
- **Scalability:** Scrapy supports various customizations and extensions, allowing developers to tailor the scraper to specific needs.
- **Performance:** Scrapy employs an asynchronous concurrency mechanism, capable of handling a large number of concurrent requests and improving scraping efficiency.
# 2. Scrapy Project Structure and Basic Usage
**2.1 Project Structure and Components**
A Scrapy project is a directory structure containing code, configuration files, and data. The fundamental components include:
- `scrapy.cfg`: The Scrapy configuration file used for setting up the scraper.
- `settings.py`: Project-specific settings file that overrides default settings in `scrapy.cfg`.
- `spiders`: The directory for spider code, containing all scraper classes.
- `pipelines`: The data pipeline directory used for processing and storing extracted data.
- `items.py`: The file where Items used in the project are defined.
- `middlewares.py`: The middleware directory for executing custom logic during the spider's request and response processing.
**2.2 Creating and Configuring a Spider**
To create a spider, create a Python file in the `spiders` directory and inherit from the `scrapy.Spider` class. The spider class must define the following methods:
- `name`: The unique name of the spider.
- `start_requests`: A generator for creating initial requests.
- `parse`: The callback function for parsing responses and extracting data.
```python
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
def start_requests(self):
yield scrapy.Request("***")
def parse(self, response):
# Parse response and extract data
pass
```
**2.3 Basic Process of Scraping a Web Page**
The basic process of scraping a web page with Scrapy is as follows:
1. The spider sends an HTTP request.
2. The Scrapy engine receives the request and sends it to the downloader middleware.
3. The downloader middleware processes the request and sends it to the downloader.
4. The downloader fetches the response and sends it to the response middleware.
5. The response middleware processes the response and sends it to the spider.
6. The spider parses the response and extracts data.
7. The extracted data is processed and stored through the pipeline.
**Mermaid Flowchart:**
```mermaid
sequenceDiagram
participant Scrapy
participant Engine
participant DownloaderMiddleware
participant Downloader
participant ResponseMiddleware
participant Spider
participant Pipeline
Scrapy->Engine: Send Request
Engine->DownloaderMiddleware: Process Request
DownloaderMiddleware->Downloader: Send Request
Downloader->DownloaderMiddleware: Process Response
DownloaderMiddleware->Engine: Send Response
Engine->ResponseMiddleware: Process Response
ResponseMiddleware->Spider: Parse Response
Spider->Pipeline: Process Data
Pipeline->Engine: Store Data
```
**Code Block:**
```python
from scrapy.spiders import Spider
from scrapy.http import Request
class MySpider(Spider):
name = "my_spider"
def start_requests(self):
yield Request("***", callback=self.parse)
def parse(self, response):
# Parse response and extract data
pass
```
**Logical Analysis:**
- The `start_requests` method generates an HTTP request and specifies the `parse` method as the callback function.
- The `parse` method parses the response and extracts data.
# 3. Scrapy Crawler Practical Application
### 3.1 Web Page Parsing and Data Extraction
**Web Page Parsing**
Web page parsing is a key step in Scrapy crawlers, aiming to extract required data from web pages formatted in HTML or XML. Scrapy provides multiple parsers such as:
- `lxml`: Based on the lxml library, supports XPath and CSS selectors.
- `html.parser`: Built-in HTML parser, supports XPath and CSS selectors.
- `cssselect`: Based on the cssselect library, supports only CSS selectors.
**Data Extraction**
Data extraction follows the parsing process, aiming to extract required data from the parsed document. Scrapy offers various data extraction methods:
- `XPath`: A query language for XML, used to extract data from HTML or XML documents.
- `CSS Selectors`: A query language based on CSS, used to extract data from HTML documents.
- `Regular Expressions`: A powerful tool for matching text patterns, used to extract data from web pages.
**Code Example:**
```python
# Extracting title using XPath
title = response.xpath('//title/text()').extract_first()
# Extracting article content using CSS selectors
content = response.css('article p::text').extract()
# Extracting email addresses using regular expressions
emails = re.findall(r'[\w\.-]+@[\w\.-]+', response.text)
```
### 3.2 Data Storage and Persistence
**Data Storage**
Scrapy provides various data storage options:
- `Files`: Store data in files such as CSV, JSON, or XML.
- `Databases`: Store data in relational databases such as MySQL, PostgreSQL, or Mon

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
JLINK_V8固件烧录故障全解析:常见问题与快速解决

# 摘要
JLINK_V8作为一种常用的调试工具,其固件烧录过程对于嵌入式系统开发和维护至关重要。本文首先概述了JLINK_V8固件烧录的基础知识,包括工具的功能特点和安装配置流程。随后,文中详细阐述了烧录前的准备、具体步骤和烧录后的验证工作,以及在硬件连接、软件配置及烧录失败中可能遇到的常见问题和解决方案
【Jetson Nano 初识】:掌握边缘计算入门钥匙,开启新世界

# 摘要
本论文介绍了边缘计算的兴起与Jetson Nano这一设备的概况。通过对Jetson Nano的硬件架构进行深入分析,探讨了其核心组件、性能评估以及软硬件支持。同时,本文指导了如何搭建Jetson Nano的开发环境,并集成相关开发库与API。此外,还通过实际案例展示了Jetson Nano在边缘计算中的应用,包括实时图像和音频数
MyBatis-Plus QueryWrapper故障排除手册:解决常见查询问题的快速解决方案
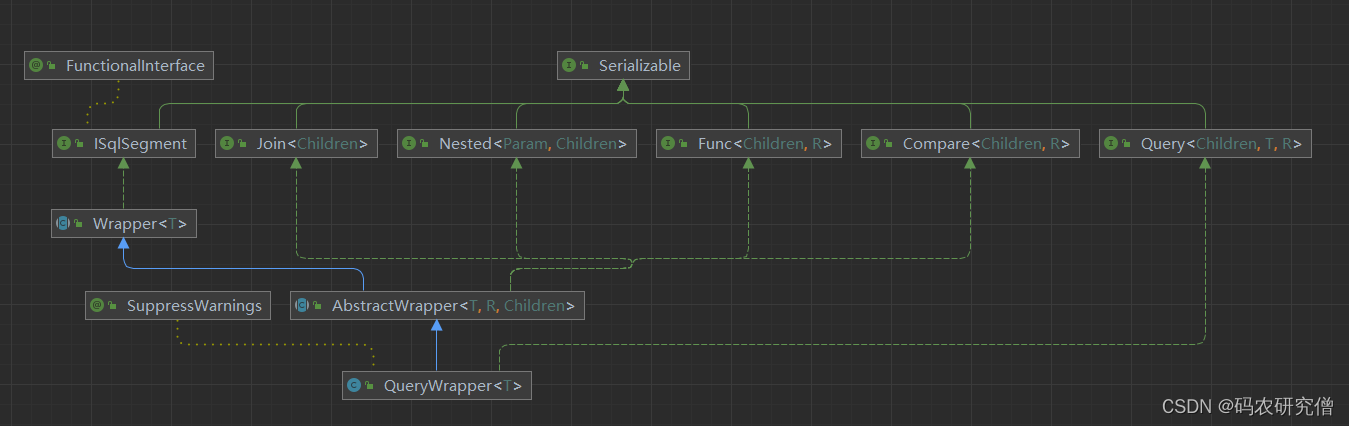
# 摘要
MyBatis-Plus作为一款流行的持久层框架,其提供的QueryWrapper工具极大地简化了数据库查询操作的复杂性。本文首先介绍了MyBatis-Plus和QueryWrapper的基本概念,然后深入解析了QueryWrapper的构建过程、关键方法以及高级特性。接着,文章探讨了在实际应用中查询常见问题的诊断与解决策略,以及在复杂场
【深入分析】SAP BW4HANA数据整合:ETL过程优化策略

# 摘要
SAP BW4HANA作为企业数据仓库的更新迭代版本,提供了改进的数据整合能力,特别是在ETL(抽取、转换、加载)流程方面。本文首先概述了SAP BW4HANA数据整合的基础知识,接着深入探讨了其ETL架构的特点以及集成方法论。在实践技巧方面,本文讨论了数据抽取、转换和加载过程中的优化技术和高级处理方法,以及性能调优策略。文章还着重讲述了ETL过
电子时钟硬件选型精要:嵌入式系统设计要点(硬件配置秘诀)

# 摘要
本文对嵌入式系统与电子时钟的设计和开发进行了综合分析,重点关注核心处理器的选择与评估、时钟显示技术的比较与组件选择、以及输入输出接口与外围设备的集成。首先,概述了嵌入式系统的基本概念和电子时钟的结构特点。接着,对处理器性能指标进行了评估,讨论了功耗管理和扩展性对系统效能和稳定性的重要性。在时钟显示方面,对比了不同显示技术的优劣,并探讨了显示模块设计和电源管理的优化策略。最后,本
【STM8L151电源设计揭秘】:稳定供电的不传之秘

# 摘要
本文对STM8L151微控制器的电源设计进行了全面的探讨,从理论基础到实践应用,再到高级技巧和案例分析,逐步深入。首先概述了STM8L151微控制器的特点和电源需求,随后介绍了电源设计的基础理论,包括电源转换效率和噪声滤波,以及STM8L151的具体电源需求。实践部分详细探讨了适合STM8L151的低压供电解决方案、电源管理策略和外围电源设计。最后,提供了电源设计的高级技巧,包括
NI_Vision视觉软件安装与配置:新手也能一步步轻松入门

# 摘要
本文系统介绍NI_Vision视觉软件的安装、基础操作、高级功能应用、项目案例分析以及未来展望。第一章提供了软件的概述,第二章详细描述了软件的安装流程及其后的配置与验证方法。第三章则深入探讨了NI_Vision的基础操作指南,包括界面布局、图像采集与处理,以及实际应用的演练。第四章着重于高级功能实
【VMware Workstation克隆与快照高效指南】:备份恢复一步到位

# 摘要
VMware Workstation的克隆和快照功能是虚拟化技术中的关键组成部分,对于提高IT环境的备份、恢复和维护效率起着至关重要的作用。本文全面介绍了虚拟机克隆和快照的原理、操作步骤、管理和高级应用,同时探讨了克隆与快照技术在企业备份与恢复中的应用,并对如何
【Cortex R52 TRM文档解读】:探索技术参考手册的奥秘
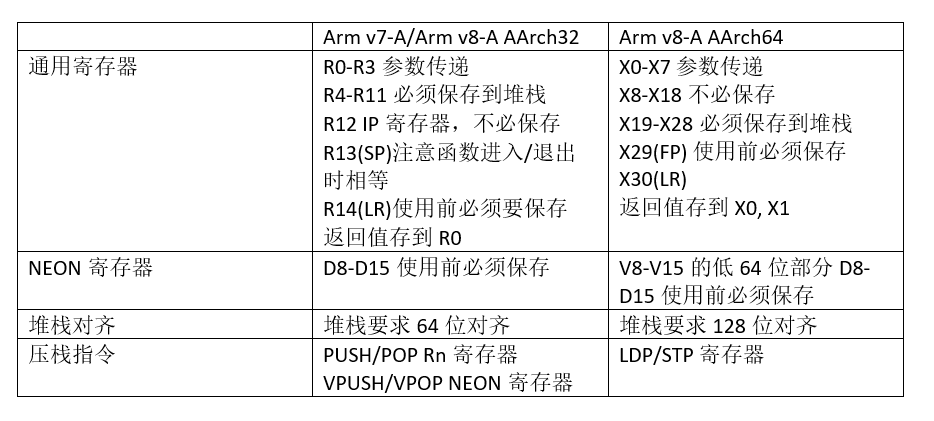
# 摘要
本文深入探讨了Cortex R52处理器的各个方面,包括其硬件架构、指令集、调试机制、性能分析以及系统集成与优化。文章首先概述了Cortex R52处理器的特点,并解析了其硬件架构的核心设计理念与组件。接着,本文详细解释了处理器的执行模式,内存管理机制,以及指令集的基础和高级特性。在调试与性能分析方面,文章介绍了Cortex R52的调试机制、性能监控技术和测试策略。最后,本文探讨了Cortex R52与外部组件的集成,实时操作系统支持,以及在特定应
西门子G120变频器安装与调试:权威工程师教你如何快速上手

# 摘要
西门子G120变频器在工业自动化领域广泛应用,其性能的稳定性与可靠性对于提高工业生产效率至关重要。本文首先概述了西门子G120变频器的基本原理和主要组件,然后详细介绍了安装前的准备工作,包括环境评估、所需工具和物料的准备。接下来,本文指导了硬件的安装步骤,强调了安装过程中的安全措施,并提供硬件诊断与故障排除的方法。此外,本文阐述了软件配置与调试的流程,包括控制面板操作、参数设置、调试技巧以及性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )