【Practical Exercise】Web Scraper Project: Scraping Product Information from E-commerce Websites and Conducting Price Comparisons
发布时间: 2024-09-15 12:58:29 阅读量: 30 订阅数: 48 

python-basic-web-scraper:python-basic-web-scraper
## Practical Exercise: Web Scraper Project - Harvesting E-commerce Product Information for Price Comparison
# 1. Overview of Web Scraper Project**
A web scraper, also known as a web spider or web crawler, is an automated tool designed to collect and extract data from the internet. Engaging in a web scraper project involves using scraper technology to obtain specific information from websites, process, and analyze it to fulfill particular needs.
This tutorial will guide you through every aspect of a web scraper project, from web parsing and data processing to price comparison and analysis. We will use real-world cases and sample code to walk you through the entire process step by step, helping you master the core concepts and practical skills of web scraper technology.
# 2. Harvesting Product Information from E-commerce Websites
### 2.1 Web Parsing Technology
#### 2.1.1 HTML and CSS Basics
HTML (HyperText Markup Language) and CSS (Cascading Style Sheets) are foundational technologies for web parsing. HTML is used to define the structure and content of web pages, while CSS is used to define the appearance and layout of web pages.
- **HTML Structure**: HTML uses tags to define the structure of web pages, such as `<head>`, `<body>`, `<div>`, `<p>`, etc. Each tag has a specific meaning and function, collectively building the framework of the web page.
- **CSS Styling**: CSS uses rules to define the appearance of web page elements, such as color, font, size, position, etc. With CSS, you can control the visual presentation of web pages, making them more readable and aesthetically pleasing.
#### 2.1.2 Web Parsing Tools and Libraries
Web parsing tools and libraries can help developers parse and extract web content with ease.
- **BeautifulSoup**: A popular Python library for parsing and processing HTML. It offers a variety of methods and attributes for conveniently extracting and manipulating web elements.
- **lxml**: Another Python library for parsing and processing HTML and XML. It is more powerful than BeautifulSoup but also more complex to use.
- **Requests**: A Python library for sending HTTP requests and retrieving web content. It provides a simple and user-friendly API for easily fetching and parsing web pages.
### 2.2 Scraper Frameworks and Tools
Scraper frameworks and tools provide more advanced features to help developers build and manage scraper projects.
#### 2.2.1 Introduction to Scrapy Framework
Scrapy is a powerful Python web scraper framework that offers the following features:
- **Built-in Parsers**: Scrapy has built-in HTML and CSS parsers that make it easy to extract web content.
- **Middleware**: Scrapy provides middleware mechanisms that allow developers to insert custom logic into the crawler's request and response processing.
- **Pipelines**: Scrapy provides pipeline mechanisms that allow developers to clean, process, and store the extracted data.
#### 2.2.2 Using the Requests Library
The Requests library is a Python library for sending HTTP requests and retrieving web content. It offers the following features:
- **Ease of Use**: The Requests library provides a clean and user-friendly API for sending HTTP requests and retrieving responses.
- **Support for Various Request Types**: The Requests library supports various HTTP request types, including GET, POST, PUT, DELETE, etc.
- **Session Management**: The Requests library can manage HTTP sessions, maintaining the state between requests.
**Code Example:**
```python
import requests
# Sending a GET request
response = requests.get("***")
# Retrieving response content
content = response.content
# Parsing HTML content
soup = BeautifulSoup(content, "html.parser")
# Extracting the web page title
title = soup.find("title").text
# Printing the web page title
print(title)
```
**Logical Analysis:**
This code example demonstrates how to use the Requests library to send HTTP requests and parse web content. It first uses the `requests.get()` method to send a GET request to a specified URL. Then, it retrieves the response content and uses BeautifulSoup to parse the HTML content. Finally, it extracts the web page title and prints it.
# 3. Product Information Data Processing
### 3.1 Data Cleaning and Preprocessing
**3.1.1 Data Cleaning Methods and Tools**
Data cleaning is a crucial step in the data processing process, aimed at removing errors, inconsistencies, ***mon cleaning methods include:
- **Removing incomplete or invalid data**: Records with too many missing values or obvious errors are deleted outright.
- **Filling in missing values**: For fields with fewer missing values, methods such as mean, median, or mode can be used to fill them in.
- **Data type conversion**: Convert data into appropriate data types, such as converting strings to numbers or dates.
- **Data formatting**: Standardize the data format, for example, by converting dates into a standard format.
- **Data normalization**: ***
***mon data cleaning tools include:
- Pandas: A powerful data processing library in Python, offering a wealth of cleaning functions.
- NumPy: A Python library for scientific computing, providing array operations and data cleaning features.
- OpenRefine: An interactive data cleaning tool supporting various data formats and custom scripts.
**Code Block: Using Pandas to Clean Data**
```python
import pandas as pd
# Reading data
df = pd.read_csv('product_info.csv')
# Deleting incomplete data
df = df.dropna()
# Filling in missing values
df['price'] = df['price'].fillna(df['price'].mean())
# Data type conversion
df['date'] = pd.to_datetime(df['date'])
# Data formatting
df['date'] = df['date'].dt.strftime('%Y-%m-%d')
```
**Logical Analysis:**
This code block uses Pandas to read a CSV file and then performs the following data cleaning operations:
- Deletes rows with missing values.
- Fills in missing price fields using the mean value.
- Converts the date field to datetime objects.
- Formats the date field to a standard date format.
### 3.1.2 Data Standardization and Normalization
Data standardization and normalization are two important steps in data preprocessing, aimed at converting data into a more suitable form for analysis and modeling.
**Data Standardization**
Data standardization refers to converting data to have ***mon standardization methods include:
- **Min-max scaling**: Scaling data between 0 and 1.
- **Mean normalization**: Subtracting the mean of the data and then dividing by its standard deviation.
- **Decimal scaling**: Multiplying data by the appropriate power of 10 to make the integer part of the data 1.
**Data Normalization**
Data normalization refers to converting data to hav***mon normalization methods include:
- **Normal distribution**: Converting data into a normal distribution.
- **Log transformation**: Taking the logarithm of the data, making its distribution closer to normal.
- **Box-Cox transformation**: A more flexible method that can transform data into various distributions.
**Code Block: Using Scikit-Learn to Standardize Data**
```python
from sklearn.preprocessing import StandardScaler
# Instantiating the scaler
scaler = StandardScaler()
# Standardizing the data
df_scaled = scaler.fit_transform(df)
```
**Logical Analysis:**
This code block uses Sci

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
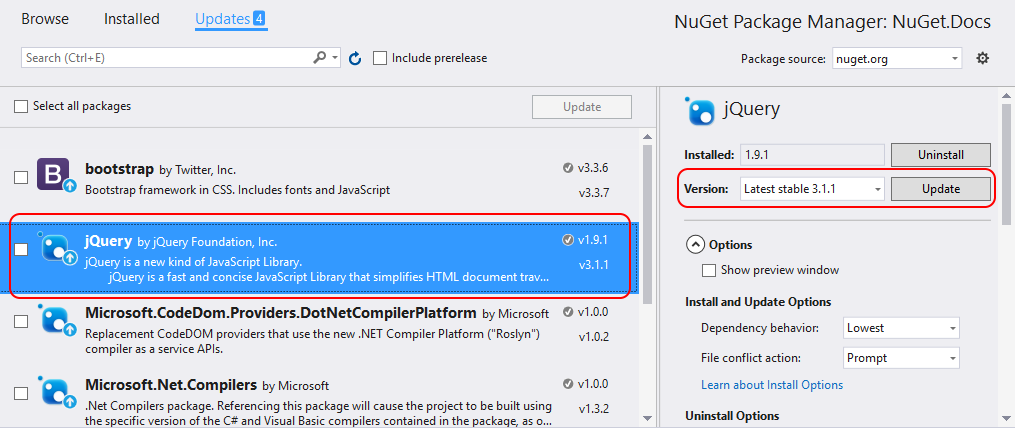
【VS2022升级全攻略】:全面破解.NET 4.0包依赖难题
# 摘要
本文对.NET 4.0包依赖问题进行了全面概述,并探讨了.NET框架升级的核心要素,包括框架的历史发展和包依赖问题的影响。文章详细分析了升级到VS2022的必要性,并提供了详细的升级步骤和注意事项。在升级后,本文着重讨论了VS2022中的包依赖管理新工具和方法,以及如何解决升级中遇到的问题,并对升级效果进行了评估。最后,本文展望了.NET框架的未来发
【ALU设计实战】:32位算术逻辑单元构建与优化技巧

# 摘要
算术逻辑单元(ALU)作为中央处理单元(CPU)的核心组成部分,在数字电路设计中起着至关重要的作用。本文首先概述了ALU的基本原理与功能,接着详细介绍32位ALU的设计基础,包括逻辑运算与算术运算单元的设计考量及其实现。文中还深入探讨了32位ALU的设计实践,如硬件描述语言(HDL)的实现、仿真验证、综合与优化等关
【网络效率提升实战】:TST性能优化实用指南

# 摘要
本文全面综述了TST性能优化的理论与实践,首先介绍了性能优化的重要性及基础理论,随后深入探讨了TST技术的工作原理和核心性能影响因素,包括数据传输速率、网络延迟、带宽限制和数据包处理流程。接着,文章重点讲解了TST性能优化的实际技巧,如流量管理、编码与压缩技术应用,以及TST配置与调优指南。通过案例分析,本文展示了TST在企业级网络效率优化中的实际应用和性能提升措施,并针对实战
【智能电网中的秘密武器】:揭秘输电线路模型的高级应用

# 摘要
本文详细介绍了智能电网中输电线路模型的重要性和基础理论,以及如何通过高级计算和实战演练来提升输电线路的性能和可靠性。文章首先概述了智能电网的基本概念,并强调了输电线路模型的重要性。接着,深入探讨了输电线路的物理构成、电气特性、数学表达和模拟仿真技术。文章进一步阐述了稳态和动态分析的计算方法,以及优化算法在输电线路模型中的应用。在实际应用方面,本文分析了实时监控、预测模型构建和维护管理策略。此外,探讨了当前技术面临的挑战和未来发展趋势,包括人
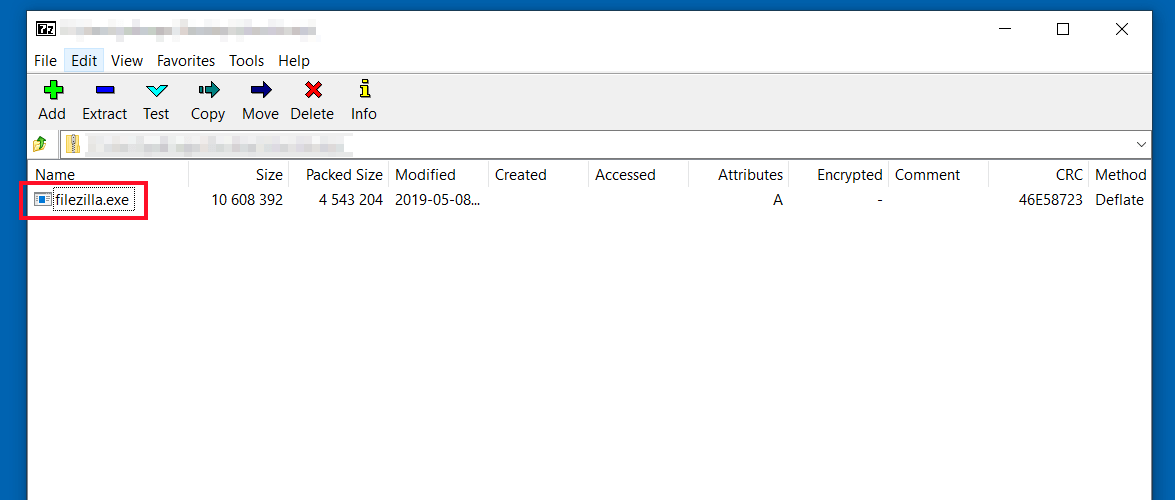
【扩展开发实战】:无名杀Windows版素材压缩包分析
# 摘要
本论文对无名杀Windows版素材压缩包进行了全面的概述和分析,涵盖了素材压缩包的结构、格式、数据提取技术、资源管理优化、安全性版权问题以及拓展开发与应用实例。研究指出,素材压缩包是游戏运行不可或缺的组件,其结构和格式的合理性直接影响到游戏性能和用户体验。文中详细分析了压缩算法的类型、标准规范以及文件编码的兼容性。此外,本文还探讨了高效的数据提取技
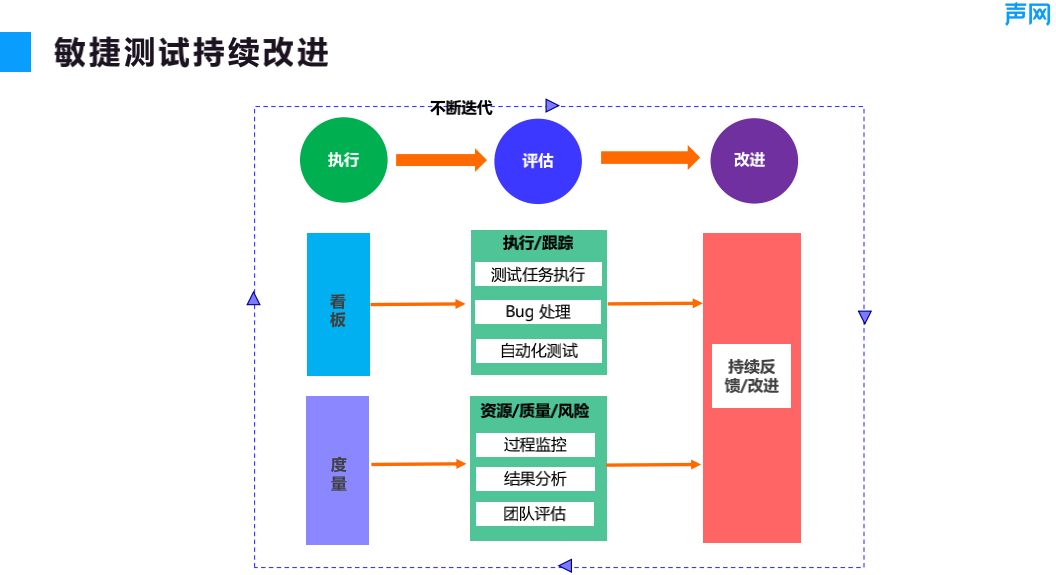
【软件测试终极指南】:10个上机练习题揭秘测试技术精髓
# 摘要
软件测试作为确保软件质量和性能的重要环节,在现代软件工程中占有核心地位。本文旨在探讨软件测试的基础知识、不同类型和方法论,以及测试用例的设计、执行和管理策略。文章从静态测试、动态测试、黑盒测试、白盒测试、自动化测试和手动测试等多个维度深入分析,强调了测试用例设计原则和测试数据准备的重要性。同时,本文也关注了软件测试的高级技术,如性能测试、安全测试以及移动
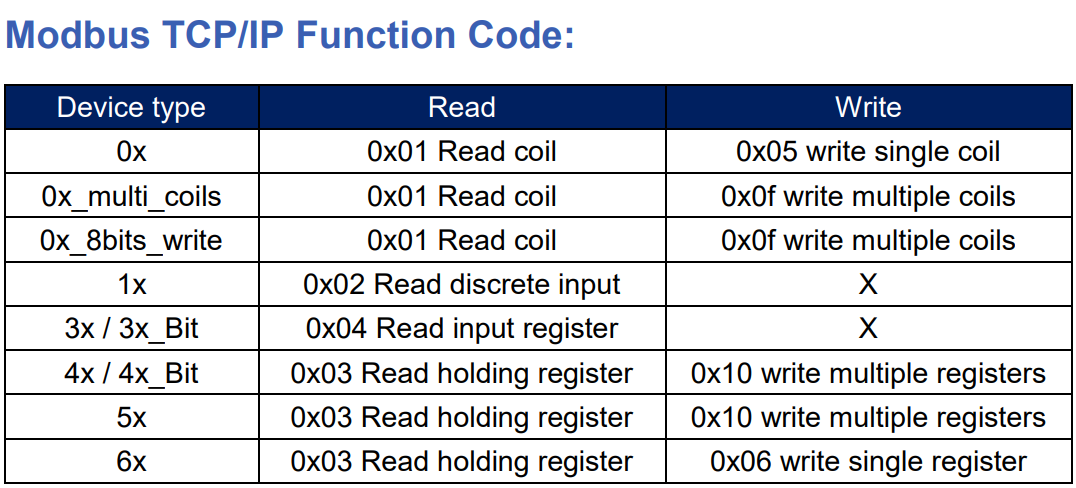
【NModbus库快速入门】:掌握基础通信与数据交换
# 摘要
本文全面介绍了NModbus库的特性和应用,旨在为开发者提供一个功能强大且易于使用的Modbus通信解决方案。首先,概述了NModbus库的基本概念及安装配置方法,接着详细解释了Modbus协议的基础知识以及如何利用NModbus库进行基础的读写操作。文章还深入探讨了在多设备环境中的通信管理,特殊数据类型处理以及如何定
单片机C51深度解读:10个案例深入理解程序设计
# 摘要
本文系统地介绍了基于C51单片机的编程及外围设备控制技术。首先概述了C51单片机的基础知识,然后详细阐述了C51编程的基础理论,包括语言基础、高级编程特性和内存管理。随后,文章深入探讨了单片机硬件接口操作,涵盖输入/输出端口编程、定时器/计数器编程和中断系统设计。在单片机外围设备控制方面,本文讲解了串行通信、ADC/DAC接口控制及显示设备与键盘接口的实现。最后,通过综合案例分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )