【Advanced】Advanced Skills for Data Parsing and Extraction
发布时间: 2024-09-15 12:15:44 阅读量: 17 订阅数: 29 
# [Advanced Techniques] Data Parsing and Extraction: Tips and Tricks
Data parsing and extraction refer to the process of extracting valuable information from various data sources. This process is crucial in today's data-driven world as it allows us to gain insights from both structured and unstructured data, enabling informed decision-making.
Data parsing and extraction generally involve the following steps:
1. **Data Acquisition:** Collecting data from diverse sources such as text files, HTML pages, databases, etc.
2. **Data Parsing:** Breaking down the data into meaningful elements using techniques like regular expressions, XPath, and HTML parsing libraries.
3. **Data Extraction:** Extracting the required information from the parsed data and storing it in a usable format.
# 2. Data Parsing Techniques
Data parsing techniques form the foundation for data extraction, offering a suite of tools and methods to extract the desired information from various data sources. This chapter will introduce three common data parsing techniques: Regular Expressions, XPath, and HTML parsing libraries.
### 2.1 Regular Expressions
Regular Expressions (Regex) are a powerful pattern matching language that allows users to match and extract specific data from text by defining patterns.
#### 2.1.1 Basic Syntax and Metacharacters
Regular expressions consist of the following basic elements:
- **Metacharacters:** Special characters with predefined meanings, such as `.` (matches any character), `*` (matches the preceding character zero or more times), and `+` (matches the preceding character one or more times).
- **Character Classes:** A set of characters enclosed in square brackets, where any one of the enclosed characters can be matched, such as `[abc]` (matches a, b, or c).
- **Quantifiers:** Specify the number of occurrences of a character or group, such as `?` (matches the preceding character zero or one time), `{n}` (matches the preceding character exactly n times), `{n,}` (matches the preceding character at least n times).
#### 2.1.2 Advanced Applications
Advanced applications of regular expressions include:
- **Grouping:** Using parentheses to group patterns, allowing for the referencing and extraction of data within groups.
- **Back References:** Using a backslash and a number to refer to a previously matched group.
- **Find and Replace:** Using the `re.sub()` function to find and replace matching text within a string.
**Code Block:**
```python
import re
# Matching numbers
pattern = r'\d+'
text = "The number is 12345"
match = re.search(pattern, text)
if match:
print(match.group()) # Output: 12345
# Matching a URL starting with "http"
pattern = r'***'
text = "The URL is ***"
match = re.search(pattern, text)
if match:
print(match.group()) # Output: ***
```
**Logical Analysis:**
- The first code block uses the `re.search()` function to match the first substring in the text that fits the pattern and prints the match.
- The second code block uses `.*` to match any number of characters, thus matching a URL starting with "http."
### 2.2 XPath
XPath (XML Path Language) is a language for locating and extracting data in XML documents. It uses path expressions to navigate the hierarchical structure of XML documents.
#### 2.2.1 Basic Syntax and Axes
XPath expressions consist of the following basic elements:
- **Axes:** Specify the direction from the current node to search, such as `child::` (child nodes) and `descendant::` (descendant nodes).
- **Node Tests:** Specify the type of node to match, such as `element()` (element nodes) and `text()` (text nodes).
- **Predicates:** Used to filter matched nodes, such as `[@id="myId"]` (nodes with an id attribute value of "myId").
#### 2.2.2 Advanced Query Techniques
Advanced query techniques in XPath include:
- **Union:** Using the `|` operator to combine multiple expressions, matching nodes that satisfy any of the expressions.
- **Intersection:** Using the `&` operator to combine multiple expressions, matching nodes that satisfy all of the expressions.
- **Functions:** Using built-in functions to manipulate nodes, such as `count()` (counts the number of nodes) and `substring()` (extracts substrings).
**Code Block:**
```xml
<root>
<child id="myId">
<grandchild>Hello</grandchild>
</child>
</root>
```
```python
import xml.etree.ElementTree as ET
# Finding the child node with an id attribute value of "myId"
tree = ET.parse('my_xml.xml')
root = tree.getroot()
child = root.find('.//child[@id="myId"]')
print(child.text) # Output: Hello
```
**Logical Analysis:**
- The code block uses the `xml.etree.ElementTree` library to parse an XML document.
- The `root.find()` method uses an XPath expression `'.//child[@i

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
R语言tm包中的文本聚类分析方法:发现数据背后的故事

# 1. 文本聚类分析的理论基础
## 1.1 文本聚类分析概述
文本聚类分析是无监督机器学习的一个分支,它旨在将文本数据根据内容的相似性进行分组。文本数据的无结构特性导致聚类分析在处理时面临独特挑战。聚类算法试图通过发现数据中的自然分布来形成数据的“簇”,这样同一簇内的文本具有更高的相似性。
## 1.2 聚类分
R语言中的数据可视化工具包:plotly深度解析,专家级教程

# 1. plotly简介和安装
Plotly是一个开源的数据可视化库,被广泛用于创建高质量的图表和交互式数据可视化。它支持多种编程语言,如Python、R、MATLAB等,而且可以用来构建静态图表、动画以及交互式的网络图形。
## 1.1 plotly简介
Plotly最吸引人的特性之一
模型结果可视化呈现:ggplot2与机器学习的结合
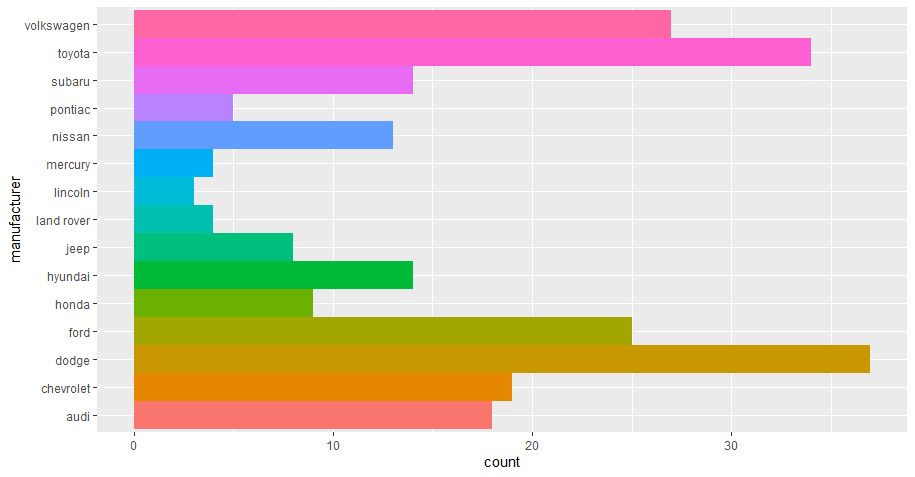
# 1. ggplot2与机器学习结合的理论基础
ggplot2是R语言中最受欢迎的数据可视化包之一,它以Wilkinson的图形语法为基础,提供了一种强大的方式来创建图形。机器学习作为一种分析大量数据以发现模式并建立预测模型的技术,其结果和过程往往需要通过图形化的方式来解释和展示。结合ggplot2与机器学习,可以将复杂的数据结构和模型结果以视觉友好的形式展现
【Tau包自定义函数开发】:构建个性化统计模型与数据分析流程

# 1. Tau包自定义函数开发概述
在数据分析与处理领域, Tau包凭借其高效与易用性,成为业界流行的工具之一。 Tau包的核心功能在于能够提供丰富的数据处理函数,同时它也支持用户自定义函数。自定义函数极大地提升了Tau包的灵活性和可扩展性,使用户可以针对特定问题开发出个性化的解决方案。然而,要充分利用自定义函数,开发者需要深入了解其开发流程和最佳实践。本章将概述Tau包自定义函数开发的基本概
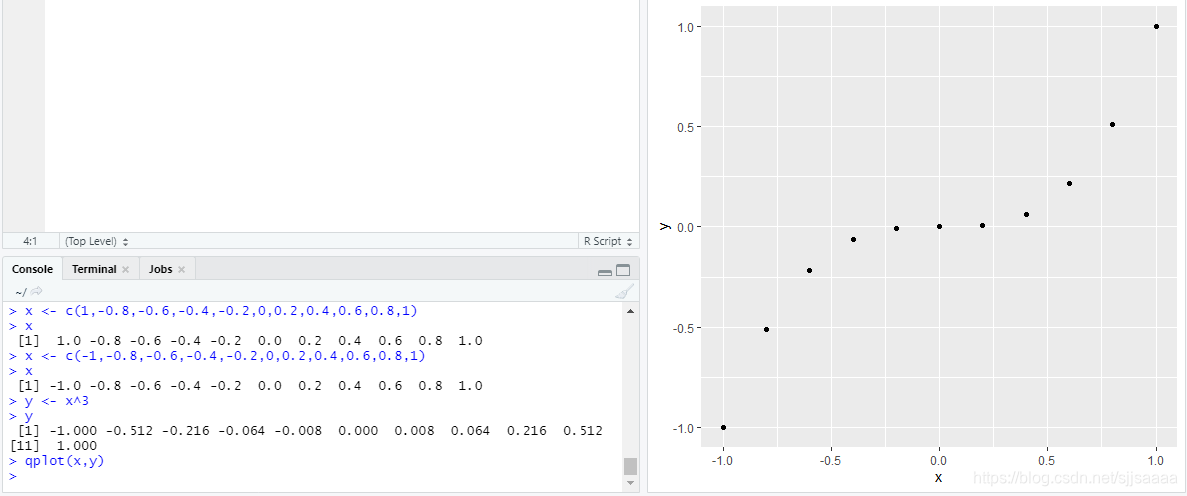
【R语言qplot深度解析】:图表元素自定义,探索绘图细节的艺术(附专家级建议)

# 1. R语言qplot简介和基础使用
## qplot简介
`qplot` 是 R 语言中 `ggplot2` 包的一个简单绘图接口,它允许用户快速生成多种图形。`qplot`(快速绘图)是为那些喜欢使用传统的基础 R 图形函数,但又想体验 `ggplot2` 绘图能力的用户设
【lattice包与其他R包集成】:数据可视化工作流的终极打造指南

# 1. 数据可视化与R语言概述
数据可视化是将复杂的数据集通过图形化的方式展示出来,以便人们可以直观地理解数据背后的信息。R语言,作为一种强大的统计编程语言,因其出色的图表绘制能力而在数据科学领域广受欢迎。本章节旨在概述R语言在数据可视化中的应用,并为接下来章节中对特定可视化工具包的深入探讨打下基础。
在数据科学项目中,可视化通
【R语言数据包安全编码实践】:保护数据不受侵害的最佳做法

# 1. R语言基础与数据包概述
## R语言简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。它在数据科学领域特别受欢迎,尤其是在生物统计学、生物信息学、金融分析、机器学习等领域中应用广泛。R语言的开源特性,加上其强大的社区
R语言图形变换:aplpack包在数据转换中的高效应用
# 1. R语言与数据可视化简介
在数据分析与科学计算的领域中,R语言凭借其强大的统计分析能力和灵活的数据可视化方法,成为了重要的工具之一
文本挖掘中的词频分析:rwordmap包的应用实例与高级技巧

# 1. 文本挖掘与词频分析的基础概念
在当今的信息时代,文本数据的爆炸性增长使得理解和分析这些数据变得至关重要。文本挖掘是一种从非结构化文本中提取有用信息的技术,它涉及到语言学、统计学以及计算技术的融合应用。文本挖掘的核心任务之一是词频分析,这是一种对文本中词汇出现频率进行统计的方法,旨在识别文本中最常见的单词和短语。
词频分析的目的不仅在于揭
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )