[Foundation] Introduction to Python Web Crawling: Setting Up the Environment and Basic Concepts
发布时间: 2024-09-15 11:49:32 阅读量: 22 订阅数: 38 

webcrawling:维基百科的简单爬网
# Introduction to Python Web Scraping: Setting Up the Environment and Basic Concepts
## 1. Overview of Python Web Scraping**
Python web scraping is an automated tool written in Python to extract data from the Internet. It mimics browser behavior to send HTTP requests, fetch web content, and extract the information needed. Python web scraping has a wide range of applications in the following areas:
* Data Collection: Collecting specific data from websites, such as product information, news articles, or social media posts.
* Web Monitoring: Regularly checking the availability, performance, and content changes of websites.
* Data Analysis: Gathering data from multiple websites to perform data analysis and gain insights.
## 2. Setting Up the Python Web Scraping Environment
### 2.1 Installation and Configuration of Python Environment
**1. Python Installation**
- Download the latest stable version from the official Python website (***
***
***
***
***
***
***'s package management tool used for installing, uninstalling, and managing Python packages.
- Ensure that pip is installed and update it to the latest version using the following command:
```
pip install --upgrade pip
```
### 2.2 Installation and Usage of Common Web Scraping Libraries
**1. requests Library**
- Used for sending HTTP requests and obtaining responses.
- Installation:
```
pip install requests
```
**2. BeautifulSoup Library**
- Used for parsing HTML and XML documents.
- Installation:
```
pip install beautifulsoup4
```
**3. Selenium Library**
- Used for automating browser operations and scraping dynamic web pages.
- Installation:
```
pip install selenium
```
**4. Scrapy Framework**
- A comprehensive web scraping framework offering rich features and scalability.
- Installation:
```
pip install scrapy
```
**5. Example Code**
```python
import requests
from bs4 import BeautifulSoup
# Sending an HTTP GET request
response = requests.get("***")
# Parsing HTML response
soup = BeautifulSoup(response.text, "html.parser")
# Finding all heading elements
titles = soup.find_all("h1")
# Iterating through heading elements and printing their text
for title in titles:
print(title.text)
```
## 3.1 HTTP Protocol and Web Page Structure
#### 3.1.1 Introduction to HTTP Protocol
The Hypertext Transfer Protocol (HTTP) is the most widely used protocol on the Internet for transferring data between web browsers and web servers. HTTP is a stateless protocol, meaning that each request is independent, and the server does not track the client's state.
The HTTP protocol consists of requests and responses. The client sends a request to the server, which includes the method of the request (such as GET or POST), the URI (Uniform Resource Identifier) of the request, and the request headers (which include additional information about the client and the request). The server responds to the request, which includes a response status code (such as 200 OK or 404 Not Found), response headers (which include additional information about the server and the response), and the response body (which contains the requested data).
#### 3.1.2 Web Page Structure
A web page is written in HTML (Hypertext Markup Language), which is a markup language used to define the structure and content of a web page. HTML elements are represented with angle brackets (<>), and different elements have various functions. For example, the <head> element contains metadata about the web page, while the <body> element contains the content of the web page.
A web page typically consists of the following parts:
- **HTML Header (<head>)**: Contains metadata about the web page, such as title, description, and keywords.
- **HTML Body (<body>)**: Contains the content of the web page, such as text, images, and videos.
- **CSS (Cascading Style Sheets)**: Used to control the style of the web page, such as font, color, and layout.
- **JavaScript**: Used to add interactivity and dynamism, such as form validation and animations.
#### 3.1.3 HTTP Requests and Responses
HTTP requests and responses use the following methods:
- **GET**: Used to retrieve data from the server.
- **POST**: Used to send data to the server.
- **PUT**: Used to update data on the server.
- **DELETE**: Used to remove data from the server.
HTTP response status codes indicate the result of the request:
- **200 OK**: Request successful.
- **404 Not Found**: The requested resource does not exist.
- **500 Internal Server Error**: Server encountered an internal error.
#### 3.1.4 HTTP Request Headers and Response Headers
HTTP request headers and response headers contain additional information about the client, server, and the request or response. Here are some common request headers:
- **User-Agent**: Contains information about the client, such as browser type and version.
- **Accept**: Contains the content types that the client can accept.
- **Content-Type**: Contains the type of the request body.
Here are some common response headers:
- **Content-Type**: Contains the type of the response body.
- **Content-Length**: Contains the length of the response body.
- **Server**: Contains information about the server, such as server software and version.
#### 3.1.5 HTTP Sessions and Cookies
HTTP sessions are used to track a client's activity on the server. A session is represented by a unique identifier, which is stored in the client's Cookies. Cookies are small text files stored on the client's computer, used to pass information between the client and server.
Sessions and Cookies allow the server to track the client's state, even if the client closes and reopens the browser between requests. For example, sessions can be used to track items in a shopping cart on an e-commerce website.
## 4. Python Web Scraping Real-World Examples
### 4.1 Simple Web Scraping and Data Parsing
**Objective:**
Extract data, including text, images, and links, from a simple static web page.
**Steps:**
1. **Import necessary libraries:**
```python
import requests
from bs4 import BeautifulSoup
```
2. **Send an HTTP request:**
```python
url = "***"
response = requests.get(url)
```
3. **Parse HTML response:**
```python
soup = BeautifulSoup(response.text, "html.parser")
```
4. **Extract text data:**
```python
text = soup.find("div", {"class": "article-body"}).text
```
5. **Extract image links:**
```python
images = [img["src"] for img in soup.find_all("img")]
```
6. **Extract links:**
```python
links = [a["href"] for a in soup.find_all("a")]
```
### 4.2 Dynamic Web Scraping and Anti-Scraping Mechanisms
**Objective:**
Extract data from a dynamic web page and deal with common anti-scraping mechanisms.
**Steps:**
1. **Use Selenium:**
```python
from selenium import webdriver
driver = webdriver.Chrome()
```
2. **Simulate browser behavior:**
```python
driver.get(url)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
```
3. **Extract data:**
```python
text = driver.find_element_by_css_selector("div.article-body").text
```
4. **Deal with anti-scraping mechanisms:**
- **UserAgent Spoofing:**
```python
options = webdriver.ChromeOptions()
options.add_argument("user-agent=Mozilla/5.0")
```
- **Proxy Servers:**
```python
proxy = "***.*.*.*:8080"
options.add_argument(f"--proxy-server={proxy}")
```
- **CAPTCHA Recognition:**
```python
from pytesseract import image_to_string
captcha = driver.find_element_by_id("captcha").screenshot("captcha.png")
text = image_to_string(captcha)
```
### Code Examples
**Simple Web Scraping:**
```python
import requests
from bs4 import BeautifulSoup
url = "***"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
text = soup.find("div", {"class": "article-body"}).text
images = [img["src"] for img in soup.find_all("img")]
links = [a["href"] for a in soup.find_all("a")]
# Logical Analysis:
# 1. Use the requests library to send an HTTP GET request.
# 2. Use BeautifulSoup to parse the HTML response.
# 3. Use the find() and find_all() methods to extract specific elements.
# 4. Store the extracted data in a list.
```
**Dynamic Web Scraping:**
```python
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(url)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
text = driver.find_element_by_css_selector("div.article-body").text
# Logical Analysis:
# 1. Use Selenium to simulate browser behavior.
# 2. Use execute_script() to execute JavaScript code.
# 3. Use find_element_by_css_selector() to extract specific elements.
# 4. Store the extracted data in variables.
```
## 5. Advanced Techniques in Python Web Scraping
### 5.1 Multi-threading and Multi-processing Scraping
#### 5.1.1 Multi-threaded Scraping
Multi-threaded scraping refers to using multiple threads to perform scraping tasks simultaneously, thus improving scraping efficiency. In Python, the `threading` module can be used to create and manage threads.
```python
import threading
def crawl_task(url):
# Scrape the URL and parse data
threads = []
for url in urls:
thread = threading.Thread(target=crawl_task, args=(url,))
threads.append(thread)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
```
**Logical Analysis:**
* Create a `crawl_task` function to scrape a specified URL and parse data.
* Create an empty list `threads` to store thread objects.
* Iterate over the URL list, create a thread object for each URL, and add it to the `threads` list.
* Start all threads.
* Wait for all threads to complete.
#### 5.1.2 Multi-processing Scraping
Multi-processing scraping refers to using multiple processes to perform scraping tasks simultaneously, further improving scraping efficiency. In Python, the `multiprocessing` module can be used to create and manage processes.
```python
import multiprocessing
def crawl_task(url):
# Scrape the URL and parse data
processes = []
for url in urls:
process = multiprocessing.Process(target=crawl_task, args=(url,))
processess.append(process)
for process in processes:
process.start()
for process in processes:
process.join()
```
**Logical Analysis:**
* Create a `crawl_task` function to scrape a specified URL and parse data.
* Create an empty list `processes` to store process objects.
* Iterate over the URL list, create a process object for each URL, and add it to the `processes` list.
* Start all processes.
* Wait for all processes to complete.
### 5.2 Proxy and Cookie Management
#### 5.2.1 Proxy Management
Proxy servers can help web scrapers hide their real IP addresses and avoid being blocked by websites. In Python, the `requests` library can be used to manage proxies.
```python
import requests
proxies = {
"http": "***",
"https": "***",
}
response = requests.get(url, proxies=proxies)
```
**Logical Analysis:**
* Create a proxy dictionary `proxies`, which includes HTTP and HTTPS proxy addresses.
* Use the `requests` library to send a request, specifying the `proxies` parameter.
#### 5.2.2 Cookie Management
Cookies can help web scrapers maintain session state and avoid repeated logins. In Python, the `requests` library can be used to manage Cookies.
```python
import requests
session = requests.Session()
response = session.get(url)
# Get Cookies
cookies = session.cookies.get_dict()
# Set Cookies
session.cookies.set("name", "value")
```
**Logical Analysis:**
* Create a `Session` object to manage Cookies.
* Use the `Session` object to send requests.
* Retrieve the Cookie dictionary through the `Session` object's `cookies` attribute.
* Set Cookies through the `Session` object's `cookies` attribute.
## 6. Python Web Scraping Project Practice
### 6.1 Planning and Design of Web Scraping Projects
**1. Requirements Analysis**
* Clearly define the target website's URL and data types for scraping.
* Analyze the website's structure, data distribution, and anti-scraping mechanisms.
**2. Technology Selection**
* Choose the appropriate web scraping framework (such as Scrapy, BeautifulSoup).
* Determine the method of data storage (such as database, file).
* Consider performance optimization solutions such as concurrency and distribution.
### 6.2 Web Scraping Project Development and Deployment
**1. Web Scraping Development**
* Write web scraping scripts to implement data scraping and parsing logic.
* Use multi-threading or multi-processing to improve scraping efficiency.
* Take countermeasures against anti-scraping mechanisms (such as changing proxies, cracking CAPTCHAs).
**2. Data Storage**
* Choose the appropriate database or file system to store the scraped data.
* Design the data table structure or file format to ensure data integrity and queryability.
**3. Deployment and Monitoring**
* Deploy the web scraper to a server or cloud platform.
* Set up monitoring mechanisms to promptly detect web scraper failures or performance bottlenecks.
* Regularly maintain the web scraper, update code, and respond to website changes.
**4. Code Examples**
```python
# Web Scraping Script Example
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['***']
start_urls = ['***']
def parse(self, response):
# Parse the webpage and extract data
for item in response.css('div.item'):
yield {
'title': item.css('h1::text').get(),
'description': item.css('p::text').get(),
}
```
```sql
# Database Table Structure Example
CREATE TABLE example (
id INT NOT NULL AUTO_INCREMENT,
title VARCHAR(255) NOT NULL,
description TEXT NOT NULL,
PRIMARY KEY (id)
);
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【用例优化秘籍】:提高硬件测试效率与准确性的策略

# 摘要
随着现代硬件技术的快速发展,硬件测试的效率和准确性变得越来越重要。本文详细探讨了硬件测试的基础知识、测试用例设计与管理的最佳实践,以及提升测试效率和用例准确性的策略。文章涵盖了测试用例的理论基础、管理实践、自动化和性能监控等关键领域,同时提出了硬件故障模拟和分析方法。为了进一步提高测试用例的精准度,文章还讨论了影响测试用例精准度的因素以及精确性测试工具的应用。
【ROSTCM自然语言处理基础】:从文本清洗到情感分析,彻底掌握NLP全过程
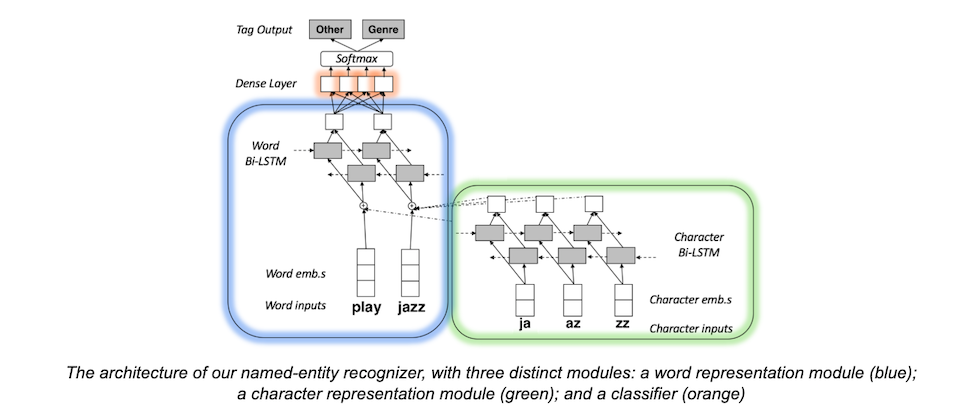
# 摘要
本文全面探讨了自然语言处理(NLP)的各个方面,涵盖了从文本预处理到高级特征提取、情感分析和前沿技术的讨论。文章首先介绍了NLP的基本概念,并深入研究了文本预处理与清洗的过程,包括理论基础、实践技术及其优
【面积分与线积分】:选择最佳计算方法,揭秘适用场景
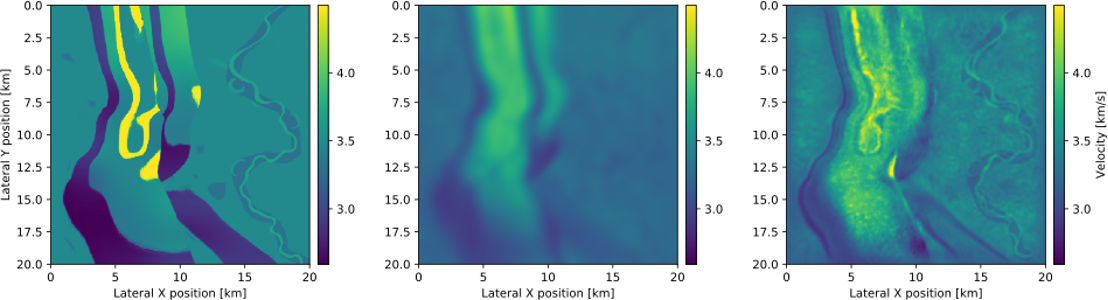
# 摘要
本文详细介绍了面积分与线积分的理论基础及其计算方法,并探讨了这些积分技巧在不同学科中的应用。通过比较矩形法、梯形法、辛普森法和高斯积分法等多种计算面积分的方法,深入分析了各方法的适用条件、原理和误差控制。同时,对于线积分,本文阐述了参数化方法、矢量积分法以及格林公式与斯托克斯定理的应用。实践应用案例分析章节展示了这些积分技术在物理学、工程计算
MIKE_flood性能调优专家指南:关键参数设置详解

# 摘要
本文对MIKE_flood模型的性能调优进行了全面介绍,从基础性能概述到深入参数解析,再到实际案例实践,以及高级优化技术和工具应用。本文详细阐述了关键参数,包括网格设置、时间步长和
【Ubuntu系统监控与日志管理】:维护系统稳定的关键步骤
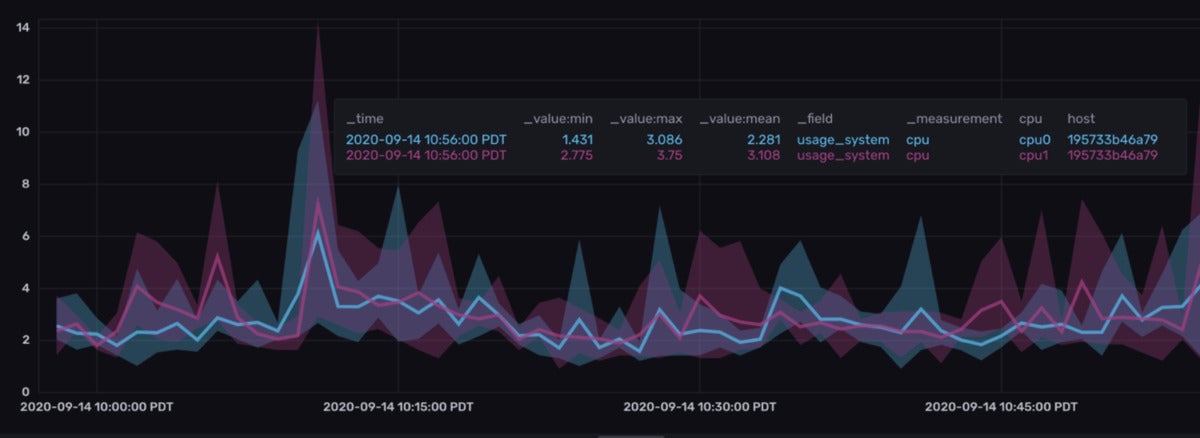
# 摘要
随着信息技术的迅速发展,监控系统和日志管理在确保Linux系统尤其是Ubuntu平台的稳定性和安全性方面扮演着至关重要的角色。本文从基础监控概念出发,系统地介绍了Ubuntu系统监控工具的选择与使用、监控数据的分析、告警设置以及日志的生成、管理和安全策略。通过对系统日志的深入分析
【蓝凌KMSV15.0:性能调优实战技巧】:提升系统运行效率的秘密武器
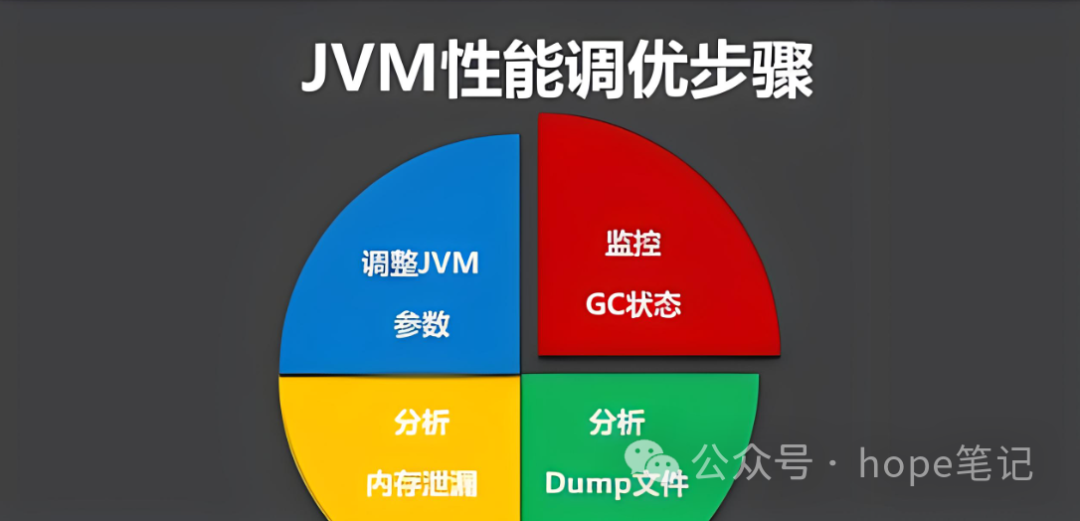
# 摘要
本文详细介绍了蓝凌KMSV15.0系统,并对其性能进行了全面评估与监控。文章首先概述了系统的基本架构和功能,随后深入分析了性能评估的重要性和常用性能指标。接着,文中探讨了如何使用监控工具和日志分析来收集和分析性能数据,提出了瓶颈诊断的理论基础和实际操作技巧,并通过案例分析展示了在真实环境中如何处理性能瓶颈问题。此外,本文还提供了系统配置优化、数据库性能
Dev-C++ 5.11Bug猎手:代码调试与问题定位速成

# 摘要
本文旨在全面介绍Dev-C++ 5.11这一集成开发环境(IDE),重点讲解其安装配置、调试工具的使用基础、高级应用以及代码调试实践。通过逐步阐述调试窗口的设置、断点、控制按钮以及观察窗口、堆栈、线程和内存窗口的使用,文章为开发者提供了一套完整的调试工具应用指南。同时,文章也探讨了常见编译错误的解读和修复,性能瓶颈的定
Mamba SSM版本对比深度分析:1.1.3 vs 1.2.0的全方位差异
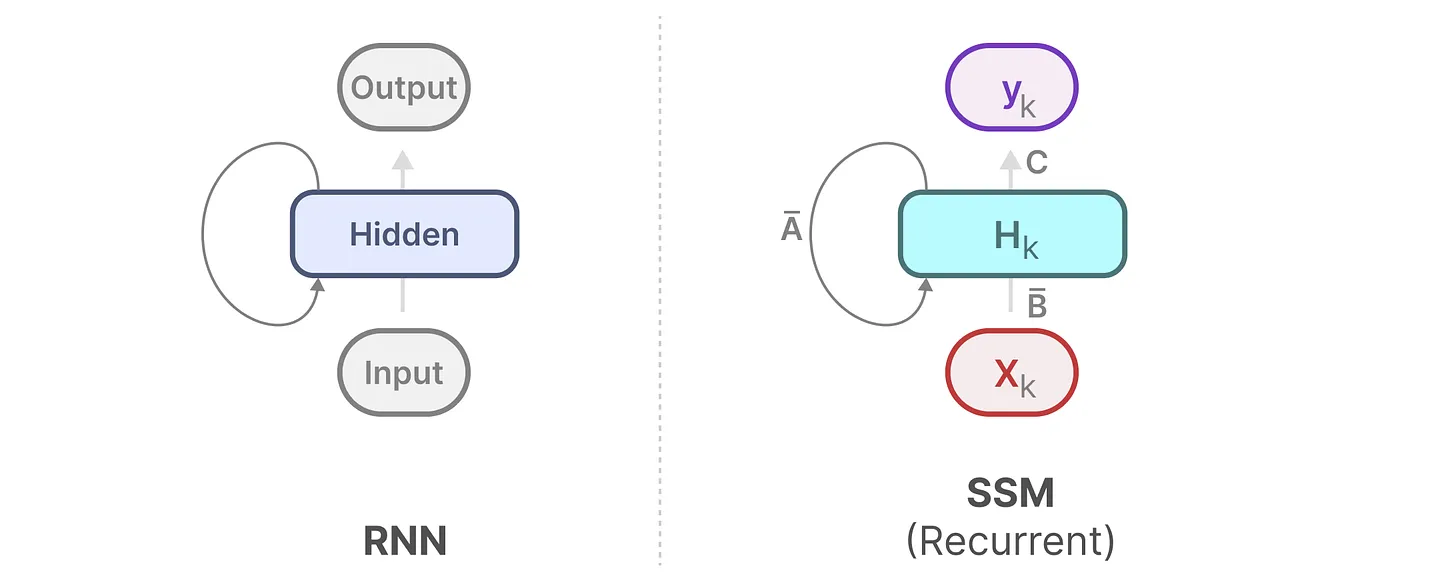
# 摘要
本文全面介绍了Mamba SSM的发展历程,特别着重于最新版本的核心功能演进、架构改进、代码质量提升以及社区和用户反馈。通过对不同版本功能模块更新的对比、性能优化的分析以及安全性的对比评估,本文详细阐述了Mamba SSM在保障软件性能与安全方面的持续进步。同时,探讨了架构设计理念的演变、核心组件的重构以及部署与兼容性的调整对整体系统稳定性的影响。本文还讨
【Java内存管理:堆栈与GC攻略】
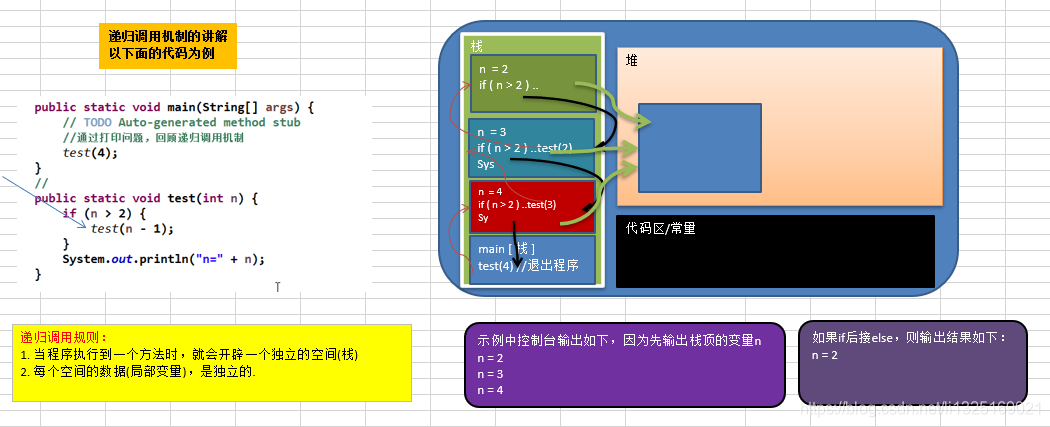
# 摘要
Java内存模型、堆内存和栈内存管理、垃圾收集机制、以及内存泄漏和性能监控是Java性能优化的关键领域。本文首先概述Java内存模型,然后深入探讨了堆内
BP1048B2应用案例分析:行业专家分享的3个解决方案与最佳实践
# 摘要
本文详细探讨了BP1048B2在多个行业中的应用案例及其解决方案。首先对BP1048B2的产品特性和应用场景进行了概述,紧接着提出行业解决方案的理论基础,包括需求分析和设计原则。文章重点分析了三个具体解决方案的理论依据、实践步骤和成功案例,展示了从理论到实践的过程。最后,文章总结了BP1048B2的最佳实践价值,预测了行业发展趋势,并给出了专家的建议和启示。通过案例分析和理论探讨,本文旨在为从业人
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )