【Advanced Chapter】Advanced Web Crawler Project Practice: Large-scale Data Collection: Implementing a Distributed Crawler System
发布时间: 2024-09-15 12:53:12 阅读量: 26 订阅数: 36 

leetcode有效期-python-beginner-webcrawler-infographic:python-初学者-webcrawle
# Advanced Web Crawler Project Implementation: Large-scale Data Collection - Building a Distributed Crawler System
## 1. Overview of Distributed Crawler Systems
A distributed crawler is a type of crawler system that leverages distributed computing technologies to accomplish large-scale web crawling tasks through the collaborative work of multiple nodes. It offers advantages such as high concurrency, efficiency, and reliability, and is widely used in areas such as e-commerce data collection, public opinion monitoring, and search engine optimization.
Distributed crawler systems typically consist of several components, including a crawler scheduler, crawler distributor, crawler executor, data storage system, and monitoring system. The crawler scheduler manages crawling tasks and assigns them to the crawler distributor; the crawler distributor then assigns tasks to the crawler executors; the crawler executors are responsible for executing the crawling tasks to retrieve web page content; the data storage system is responsible for storing the retrieved web page content; and the monitoring system is responsible for monitoring the operation status of the crawler system, promptly detecting and handling faults.
## 2. Distributed Crawler Architecture Design
### 2.1 Advantages and Challenges of Distributed Crawlers
**Advantages:**
***Scalability:** Distributed architectures allow for easy expansion of the crawler system to handle vast amounts of data and concurrent requests.
***High Availability:** Components within the distributed system can be redundant, enhancing system availability and fault tolerance.
***Parallel Processing:** Distributed crawlers can simultaneously crawl data across multiple nodes, significantly improving crawling efficiency.
***Data Consistency:** Distributed storage systems can ensure data consistency, even in the event of node failures or network outages.
**Challenges:**
***System Complexity:** Distributed architectures increase system complexity, requiring consideration of communication, coordination, and fault tolerance between components.
***Data Consistency:** Maintaining data consistency in a distributed environment requires additional mechanisms, such as distributed transactions or eventual consistency.
***Network Latency:** Network latency between distributed components can affect system performance and stability.
***Resource Management:** Distributed systems need to manage a large number of resources, such as computing, storage, and networking, to ensure smooth system operation.
### 2.2 Common Patterns in Distributed Crawler Architectures
**Master-Slave Pattern:**
* A master node coordinates crawling tasks and assigns them to slave nodes for execution.
* Slave nodes return crawling results to the master node for aggregation and storage.
* Advantages: Simple and easy to use, good scalability.
* Disadvantages: A master node failure can cause the system to collapse.
**Cluster Pattern:**
* Multiple nodes execute crawling tasks simultaneously without a master-slave relationship.
* Nodes communicate and coordinate through message queues or other mechanisms.
* Advantages: High availability, good scalability.
* Disadvantages: Complex coordination, difficulty in maintaining data consistency.
**Hybrid Pattern:**
* Combines the advantages of both master-slave and cluster patterns.
* The master node is responsible for task assignment and coordination, while slave nodes form clusters for parallel data crawling.
* Advantages: Balances high availability, scalability, and data consistency.
* Disadvantages: High complexity in implementation.
### 2.3 Selection and Design of Distributed Crawler Architectures
The selection of the architecture needs to consider the following factors:
***Crawling Scale:** The amount of data and concurrent requests to be processed.
***Data Consistency Requirements:** Whether strong or eventual consistency is required.
***System Availability Requirements:** The system's tolerance for faults.
***Resource Constraints:** Available computing, storage, and network resources.
When designing, consider the following aspects:
***Component Division:** Divide the crawler system into different components, such as scheduler, distributor, executor, and storage.
***Communication Mechanism:** Choose an appropriate communication mechanism, such as message queues, RPC, or HTTP.
***Fault Handling:** Design fault handling mechanisms to ensure the system continues to run in the event of component failures.
***Load Balancing:** Implement load balancing strategies to optimize resource utilization and system performance.
**Code Example:**
```python
# Master node code in the master-slave pattern
import time
import requests
# Creating a task queue
task_queue = []
# Crawling task
def crawl_task(url):
# Sending the crawl request
response = requests.get(url)
# Parsing and saving the crawl results
# Master node loop
while True:
# Getting tasks from the task queue
url = task_queue.pop(0)
# Assigning tasks to slave nodes
requests.post("***", json={"url": url})
# Waiting for results from slave nodes
# Saving crawl results
```
```python
# Slave node code in the master-slave pattern
import requests
# Receiving tasks assigned by the master node
url = requests.get("*
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
BMS通讯协议V2.07全解析:电池管理系统通信技术的终极指南(权威揭秘)
(1).jpg)
参考资源链接:[沃特玛BMS通讯协议V2.07详解](https://wenku.csdn.net/doc/oofsi3m9yc?spm=1055.2635.3001.10343)
# 1. BMS通讯协议V2.07概述
## 1.1 BMS通讯协议简介
电池管理系统(Battery Management System, BMS)通讯协议V2.07是一套用于电池单元与管理单元之间交换数据的标准协议。它的主要作用是确保电池系统的健康状态监控、充放电控制和信息
【Prime Time工作流程优化】:自动化与个性化设置的终极指南

参考资源链接:[Synopsys Prime Time中文教程:静态时序分析与形式验证详解](https://wenku.csdn.net/doc/6492b5a89aecc961cb2885db?spm=1055.2635.3001.10343)
# 1. Prime Time工作流程优化概述
在信息技术日新月异的今天,工作流程优化已成为提高企业竞争力的关键要素。随着技术的不断发展,Prime Time公
【计价软件故障快速解决】:常见问题及应对技巧
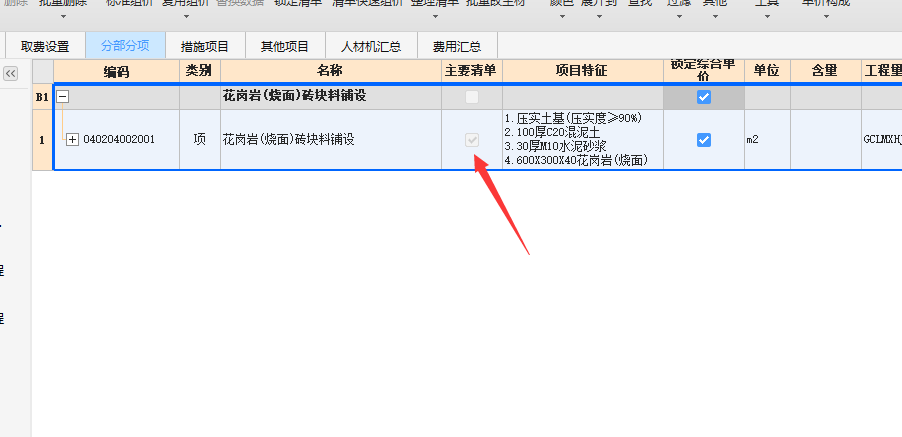
参考资源链接:[新点计价软件操作指南:量价费与子目工程量调整](https://wenku.csdn.net/doc/61bffjnss9?spm=1055.2635.3001.10343)
# 1. 计价软件故障快速解决概览
在现代商业环境中,计价软件是企业运营不可或缺的一部分,为准确的财务计算提供了技术支持。然而,由于软件系统的复杂性和不断变化的操作需求,故障在所难免。快速解决这些故障不仅能降低公司的损失,还能提
FANUC机械臂编程与应用:自动化解决方案的全面指南

参考资源链接:[FANUC机器人操作与安全手册:编程与维修指南](https://wenku.csdn.net/doc/645ef067543f844488899ce4?spm=1055.2635.3001.10343)
# 1. FANUC机械臂概述及其在自动化中的角色
## 1.1 机械臂技术的起源与发展
工业机械臂技术自20世纪中叶起源于汽车制造业,最初用于简化重复性高、劳动强度大的任务。如今,随着技术的进步,机械臂已经成为自动
【指针进阶技巧】:C语言高效内存管理,让你的程序运行如飞

参考资源链接:[C语言指针详细讲解ppt课件](https://wenku.csdn.net/doc/64a2190750e8173efdca92c4?spm=1055.2635.3001.10343)
# 1. 指针与内存管理基础
## 1.1 内存管理的重要性
内存管理是编写高效、稳定程序的核心部分。掌握内存管理的基础知识,有助于防止程序中出现内存泄漏、指针错误等问题,这对于软件的性能和可靠性
【射频天线设计全攻略】:CST仿真流程与案例深度解析

参考资源链接:[CST微波工作室初学者教程:电磁仿真轻松入门](https://wenku.csdn.net/doc/6401ad40cce7214c316eed7a?spm=1055.2635.3001.10343)
# 1. 射频天线设计基础概述
## 射频天线的重要性与应用场景
射频(Radio Frequency,RF)天线作为无线通信系统中不可或缺的组成部分,负责发送和接收无线信号。它们广泛应
数据仓库集成大揭秘:Kettle全量同步的流向解析
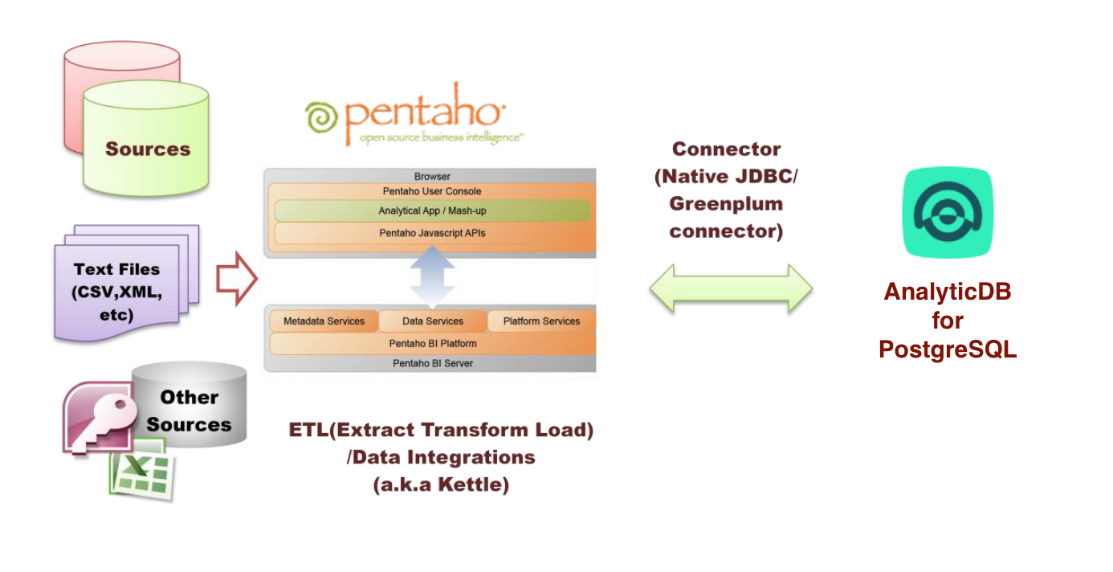
参考资源链接:[Kettle全量多表数据同步教程](https://wenku.csdn.net/doc/646eb837d12cbe7ec3f092fe?spm=1055.2635.3001.10343)
# 1. 数据仓库集成简介
在数字化时代,数据已成为企业最宝贵的资产之一。数据仓库集成作为企业信息系统中不可或缺的组成部分,扮演着至关重要的角色。通过对数据的整合,企业能够洞察业务趋势,
GC2083性能优化全攻略:实战技巧助你轻松升级
参考资源链接:[GC2083CSP: 1/3.02'' 2Mega CMOS Image Sensor 数据手册](https://wenku.csdn.net/doc/50kdu1upix?spm=1055.2635.3001.10343)
# 1. GC2083性能优化概述
## 1.1 性能优化的必要性
GC2083系统作为企业级应用的基石,其
数字设计原理与实践第四版深度剖析:掌握数字设计核心秘诀

参考资源链接:[John F.Wakerly《数字设计原理与实践》第四版课后答案解析:逻辑图与数制转换](https://wenku.csdn.net/doc/1qxugirwra?spm=1055.2635.3001.10343)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )