[Advanced] Tips for Web Scraping Dynamic Pages: Using the Splash Rendering Engine to Handle JavaScript-Driven Websites
发布时间: 2024-09-15 12:27:07 阅读量: 26 订阅数: 38 

Webscraping-API:带有快递服务器和X射线的Web剪贴API应用
# **【Advanced篇】Dynamic Web Scraping Techniques: Utilizing the Splash Rendering Engine for JavaScript-Driven Pages**
## 1. Overview of Dynamic Web Scraping
Dynamic web scraping refers to the process of retrieving content from web pages that require JavaScript execution in a browser to fully render. Unlike static pages, the content of dynamic pages is dynamically generated by client-side scripts, presenting challenges to traditional web crawlers. To tackle these challenges, rendering engines dedicated to dynamic web scraping have emerged, such as the Splash rendering engine.
## 2. Introduction to the Splash Rendering Engine
### 2.1 Principles and Advantages of the Splash Rendering Engine
The Splash rendering engine is a headless rendering service based on the Chromium browser. It allows developers to render dynamic web pages without a graphical user interface (GUI). It achieves this by providing a remotely controlled browser instance, enabling users to perform various operations such as loading URLs, executing JavaScript code, and obtaining rendered HTML.
The main advantages of the Splash rendering engine include:
- **Headless Rendering:** Splash can render web pages without a GUI, making it ideal for automation tasks and server-side rendering.
- **Remote Control:** Users can remotely control the Splash rendering engine via HTTP API or Python clients, offering great flexibility.
- **JavaScript Support:** The engine supports JavaScript execution, allowing users to interact with dynamic web pages.
- **High Performance:** Splash uses a multi-threaded architecture to handle multiple rendering requests in parallel, improving performance.
### 2.2 Installation and Configuration of the Splash Rendering Engine
**Installation**
The Splash rendering engine can be installed on various platforms, including Linux, macOS, and Windows. The installation process varies by platform, but typically involves the following steps:
1. Install Docker or Docker Compose.
2. Clone the Splash rendering engine's GitHub repository.
3. Run the `docker-compose up` command.
**Configuration**
The Splash rendering engine can be configured using environment variables. Here are some common configuration options:
| Variable | Description |
|---|---|
| SPLASH_PORT | The port the Splash rendering engine listens on |
| SPLASH_ARGS | Additional arguments passed to the Chromium browser |
| SPLASH_TIMEOUT | Timeout for the Splash rendering engine |
For example, to configure the Splash rendering engine to listen on port 8050, use the following command:
```
docker-compose up -d --scale splash=1 -e SPLASH_PORT=8050
```
**Code Example:**
```python
import splash
import requests
# Create a Splash client
splash_client = splash.Splash(port=8050)
# Load URL and render
response = splash_client.render("***")
# Get the rendered HTML
html = response.html
```
**Code Logic Analysis:**
This code creates a Splash client and uses the `render()` method to load and render a URL. The `render()` method returns a response object that contains the rendered HTML.
## 3. Utilizing the Splash Rendering Engine to Scrape Dynamic Web Pages
### 3.1 Integration of the Splash Rendering Engine with Web Scraping Frameworks
The Splash rendering engine can integrate with various popular web scraping framework

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
C# WinForm程序打包进阶秘籍:掌握依赖项与配置管理
# 摘要
本文系统地探讨了WinForm应用程序的打包过程,详细分析了依赖项管理和配置管理的关键技术。首先,依赖项的识别、分类、打包策略及其自动化管理方法被逐一介绍,强调了静态与动态链接的选择及其在解决版本冲突中的重要性。其次,文章深入讨论了应用程序配置的基础和高级技巧,如配置信息的加密和动态加载更新。接着,打包工具的选择、自动化流程优化以及问题诊断与解决策略被详细
参数设置与优化秘籍:西门子G120变频器的高级应用技巧揭秘

# 摘要
西门子G120变频器是工业自动化领域的关键设备,其参数配置对于确保变频器及电机系统性能至关重要。本文旨在为读者提供一个全面的西门子G120变频器参数设置指南,涵盖了从基础参数概览到高级参数调整技巧。本文首先介绍了参数的基础知识,包括各类参数的功能和类
STM8L151 GPIO应用详解:信号控制原理图解读

# 摘要
本文详细探讨了STM8L151微控制器的通用输入输出端口(GPIO)的功能、配置和应用。首先,概述了GPIO的基本概念及其工作模式,然后深入分析了其电气特性、信号控制原理以及编程方法。通过对GPIO在不同应用场景下的实践分析,如按键控制、LED指示、中断信号处理等,文章揭示了GPIO编程的基础和高级应
【NI_Vision进阶课程】:掌握高级图像处理技术的秘诀
# 摘要
本文详细回顾了NI_Vision的基本知识,并深入探讨图像处理的理论基础、颜色理论及算法原理。通过分析图像采集、显示、分析、处理、识别和机器视觉应用等方面的实际编程实践,本文展示了NI_Vision在这些领域的应用。此外,文章还探讨了NI_Vision在立体视觉、机器学习集成以及远程监控图像分析中的高级功能。最后,通过智能监控系统、工业自动化视觉检测和医疗图像处理应用等项目案例,
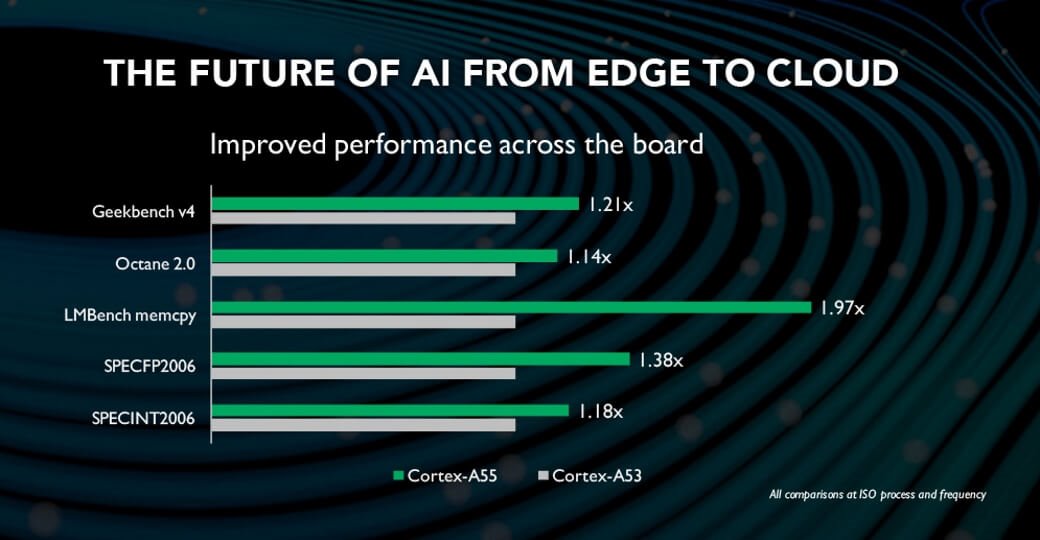
【Cortex R52与ARM其他处理器比较】:全面对比与选型指南
# 摘要
本文详细介绍了Cortex R52处理器的架构特点、应用案例分析以及选型考量,并提出了针对Cortex R52的优化策略。首先,文章概述了Cortex R52处理器的基本情
JLINK_V8固件烧录安全手册:预防数据损失和设备损坏
# 摘要
本文对JLINK_V8固件烧录的过程进行了全面概述,包括烧录的基础知识、实践操作、安全防护措施以及高级应用和未来发展趋势。首先,介绍了固件烧录的基本原理和关键技术,并详细说明了JLINK_V8烧录器的硬件组成及其操作软件和固件。随后,本文阐述了JLINK_V8固件烧录的操作步骤,包括烧录前的准备工作和烧录过程中的操作细节,并针对常见问题提供了相应的解决方法。此外,还探讨了数据备份和恢
Jetson Nano性能基准测试:评估AI任务中的表现,数据驱动的硬件选择

# 摘要
Jetson Nano作为一款针对边缘计算设计的嵌入式设备,其性能和能耗特性对于AI应用至关重要。本文首先概述了Jetson Nano的硬件架构,并强调了性能基准测试在评估硬件性能中的重要性。通过分析其处理器、内存配置、能耗效率和散热解决方案,本研究旨在提供详尽的硬件性能基准测试方法,并对Jetson Nano在不同AI任务中的表现进行系统评估。最
MyBatis-Plus QueryWrapper多表关联查询大师课:提升复杂查询的效率

# 摘要
本文围绕MyBatis-Plus框架的深入应用,从安装配置、QueryWrapper使用、多表关联查询实践、案例分析与性能优化,以及进阶特性探索等几个方面进行详细论述。首先介绍了MyBatis-Plus的基本概念和安装配置方法。随
【SAP BW4HANA集成篇】:与S_4HANA和云服务的无缝集成

# 摘要
随着企业数字化转型的不断深入,SAP BW4HANA作为新一代的数据仓库解决方案,在集成S/4HANA和云服务方面展现了显著的优势。本文详细阐述了SAP BW4HANA集成的背景、优势、关键概念以及业务需求,探讨了与S/4HANA集成的策略,包括集成架构设计、数据模型适配转换、数据同步技术与性能调优。同时,本文也深入分析了SAP BW4HANA与云服务集成的实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )