[Advanced] Analysis and Solutions of Anti-Crawler Cases: Analyzing Common Anti-Crawler Measures and Countermeasures
发布时间: 2024-09-15 12:50:57 阅读量: 15 订阅数: 30 
**2.1 IP Address Restrictions**
### 2.1.1 Principle and Implementation
IP address restrictions are a common anti-scraping technique that prevents web crawlers from scraping data by limiting access to a website from specific IP addresses or IP address ranges. There are typically two implementation methods:
- **Blacklist Restriction:** Add the IP addresses commonly used by web crawlers to a blacklist, thereby prohibiting their access to the website.
- **Whitelist Restriction:** Only allow access to the website from specific IP addresses or IP address ranges, denying access to all other IP addresses.
# ***mon Anti-Scraping Techniques Analysis
### 2.1 IP Address Restrictions
#### 2.1.1 Principle and Implementation
IP address restrictions are a technique that prevents web scrapers from accessing content by limiting access to websites or applications from specific IP addresses. It is achieved by adding the crawler's IP address to a blacklist or a whitelist. When a crawler attempts to access a protected website or application, it will be denied access or redirected to an error page.
#### 2.1.2 Bypass Strategies
There are several strategies for bypassing IP address restrictions:
- **Using Proxies:** Proxy servers act as intermediaries between the crawler and the target website. The crawler sends requests through a proxy server, thereby hiding its real IP address.
- **Rotating IP Addresses:** The crawler can use a pool of proxy servers, regularly rotating between them to avoid detection.
- **Using the Tor Network:** The Tor network is an anonymous network that routes traffic through multiple nodes, hiding the crawler's IP address.
### 2.2 User-Agent Detection
#### 2.2.1 Principle and Implementation
User-agent detection is a technique that identifies web crawlers by examining the user-agent string in the HTTP request sent by the crawler. The user-agent string contains information about the crawler, such as its name, version, and operating system. When a crawler attempts to access a protected website or application, it checks the user-agent string and compares it with a known list of crawlers. If the crawler is identified, it will be denied access or redirected to an error page.
#### 2.2.2 Bypass Strategies
There are several strategies for bypassing user-agent detection:
- **Forging User-Agent Strings:** The crawler can forge a user-agent string to make it appear as if it is coming from a legitimate browser.
- **Using Browser Fingerprints:** Browser fingerprinting is a technique for identifying unique characteristics of a browser. The crawler can bypass user-agent detection by using browser fingerprints.
- **Using Custom Request Headers:** The crawler can customize HTTP request headers to avoid triggering user-agent detection.
### 2.3 Cookie and Session Verification
#### 2.3.1 Principle and Implementation
Cookie and session verification are techniques that identify and track users by exchanging cookies or session IDs between the client (crawler) and the server. When a crawler attempts to access a protected website or application, it will receive an HTTP response containing a cookie or session ID. The crawler must return the same cookie or session ID in subsequent requests to prove it is a legitimate user. If the crawler cannot provide the correct cookie or session ID, it will be denied access or redirected to an error page.
#### 2.3.2 Bypass Strategies
There are several strategies for bypassing cookie and session verification:
- **Disabling Cookies:** The crawler can disable cookies to avoid receiving and returning them.
- **Forging Cookies:** The crawler can forge cookies to make them appear as if they are coming from a legitimate user.
- **Hijacking Sessions:** The crawler can hijack sessions to gain access to the sessions of legitimate users.
# 3. Anti-Anti-Scraping Techniques Exploration
Although anti-scraping techniques can effectively block a

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【R语言图形美化与优化】:showtext包在RShiny应用中的图形输出影响分析

# 1. R语言图形基础与showtext包概述
## 1.1 R语言图形基础
R语言是数据科学领域内的一个重要工具,其强大的统计分析和图形绘制能力是许多数据科学家选择它的主要原因。在R语言中,绘图通常基于图形设备(Graphics Devices),而标准的图形设备多使用默认字体进行绘图,对于非拉丁字母字符支持较为有限。因此,为了在图形中使用更丰富的字
rgdal包的空间数据处理:R语言空间分析的终极武器

# 1. rgdal包概览和空间数据基础
## 空间数据的重要性
在地理信息系统(GIS)和空间分析领域,空间数据是核心要素。空间数据不仅包含地理位置信息,还包括与空间位置相关的属性信息,使得地理空间分析与决策成为可能。
## rgdal包的作用
rgdal是R语言中用于读取和写入多种空间数据格式的包。它是基于GDAL(Geospatial Data Abstraction Library)的接口,支持包括
R语言Cairo包图形输出调试:问题排查与解决技巧

# 1. Cairo包与R语言图形输出基础
Cairo包为R语言提供了先进的图形输出功能,不仅支持矢量图形格式,还极大地提高了图像渲染的质量
【数据处理流程】:R语言高效数据清洗流水线,一步到位指南
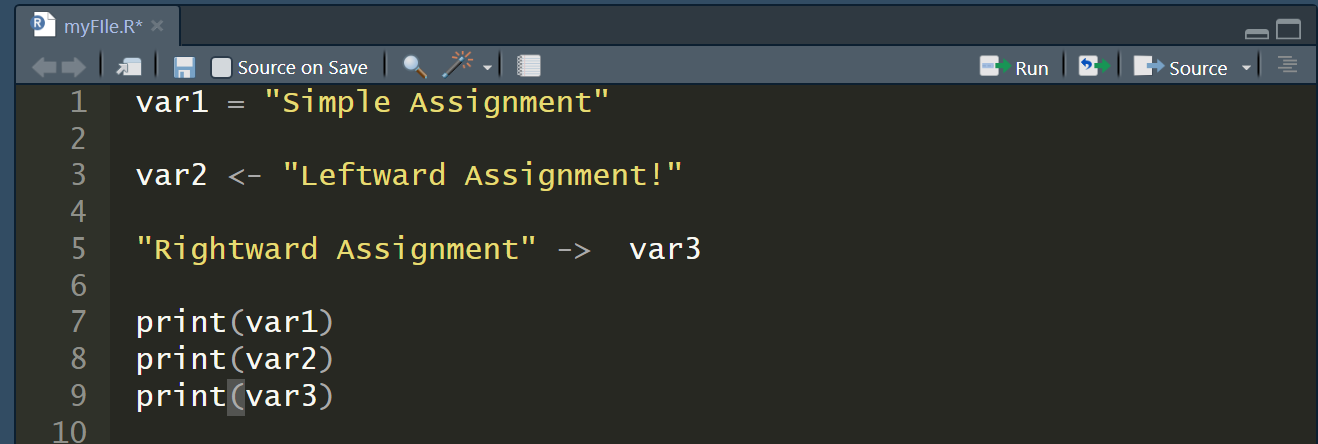
# 1. R语言数据处理概述
## 数据处理的重要性
在数据分析和科学计算领域,数据处理是不可或缺的步骤。R语言作为一种专业的统计分析工具,因其开源、灵活、强大的数据处理能力,在数据科学界备受推崇。它不仅支持基本的数据操作,还能轻松应对复杂的数据清洗和分析工作。
## R语言在数据处理中的应用
R语言提供了一系列用于数据处理的函数和库,如`dplyr`、`data.table`和`tidyr`等,它们极大地简化了数据清洗、
【空间数据查询与检索】:R语言sf包技巧,数据检索的高效之道

# 1. 空间数据查询与检索概述
在数字时代,空间数据的应用已经成为IT和地理信息系统(GIS)领域的核心。随着技术的进步,人们对于空间数据的处理和分析能力有了更高的需求。空间数据查询与检索是这些技术中的关键组成部分,它涉及到从大量数据中提取
R语言数据讲述术:用scatterpie包绘出故事
# 1. R语言与数据可视化的初步
## 1.1 R语言简介及其在数据科学中的地位
R语言是一种专门用于统计分析和图形表示的编程语言。自1990年代由Ross Ihaka和Robert Gentleman开发以来,R已经发展成为数据科学领域的主导语言之一。它的
geojsonio包在R语言中的数据整合与分析:实战案例深度解析
# 1. geojsonio包概述及安装配置
在地理信息数据处理中,`geojsonio` 是一个功能强大的R语言包,它简化了GeoJSON格式数据的导入导出和转换过程。本章将介绍 `geojsonio` 包的基础安装和配置步骤,为接下来章节中更高级的应用打下基础。
## 1.1 安装geojsonio包
在R语言中安装 `geojsonio` 包非常简单,只需使用以下命令:
```
【R语言空间数据与地图融合】:maptools包可视化终极指南
# 1. 空间数据与地图融合概述
在当今信息技术飞速发展的时代,空间数据已成为数据科学中不可或缺的一部分。空间数据不仅包含地理位置信息,还包括与该位置相关联的属性数据,如温度、人口、经济活动等。通过地图融合技术,我们可以将这些空间数据在地理信息框架中进行直观展示,从而为分析、决策提供强有力的支撑。
空间数据与地图融合的过程是将抽象的数据转化为易于理解的地图表现形式。这种形式不仅能够帮助决策者从宏观角度把握问题,还能够揭示数据之间的空间关联性和潜在模式。地图融合技术的发展,也使得各种来源的数据,无论是遥感数据、地理信息系统(GIS)数据还是其他形式的空间数据,都能被有效地结合起来,形成综合性
R语言数据包用户社区建设
# 1. R语言数据包用户社区概述
## 1.1 R语言数据包与社区的关联
R语言是一种优秀的统计分析语言,广泛应用于数据科学领域。其强大的数据包(packages)生态系统是R语言强大功能的重要组成部分。在R语言的使用过程中,用户社区提供了一个重要的交流与互助平台,使得数据包开发和应用过程中的各种问题得以高效解决,同时促进
R语言统计建模与可视化:leaflet.minicharts在模型解释中的应用

# 1. R语言统计建模与可视化基础
## 1.1 R语言概述
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。它在数据挖掘和统计建模领域得到了广泛的应用。R语言以其强大的图形功能和灵活的数据处理能力而受到数据科学家的青睐。
## 1.2 统计建模基础
统计建模
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )