【Fundamentals】Web Crawler Security Strategies: Avoiding IP Blocking and Detection Mechanisms
发布时间: 2024-09-15 12:04:57 阅读量: 27 订阅数: 37 

web-security-fundamentals::school:Mike的网络安全课程
# 2.1 Network Security Threats and Risk Assessment
Network security threats refer to potential damages or disruptions to network systems, data, or resources. Web crawler security strategies mainly target the security threats brought by crawlers, including:
***Data breaches:** Crawlers can collect and steal sensitive data, such as personal information, financial information, or business secrets.
***Service disruption:** Excessive crawler requests can lead to server overload or crashes, affecting the normal operation of websites or applications.
***Malware propagation:** Crawlers can spread malware or viruses, damaging systems or stealing data.
***Phishing:** Crawlers can collect user data, used for phishing attacks to deceive users into revealing sensitive information.
***Loss of competitive advantage:** Crawlers can collect data from competitors for analysis and the formulation of competitive strategies, damaging the competitive advantage of enterprises.
# 2. Theoretical Foundations of Crawler Security Strategies
### 2.1 Network Security Threats and Risk Assessment
**Network Security Threats**
Network security threats refer to any actions or events that could potentially damage network systems, data, ***mon network security threats include:
- **Malware:** Viruses, worms, trojans, and other malicious software intended to damage systems or steal data.
- **Phishing:** Deceiving users into providing sensitive information through forged emails or websites.
- **Denial of Service (DoS) attacks:** Rendering target systems inoperable by sending a large volume of traffic to them.
- **Man-in-the-Middle (MitM) attacks:** Intercepting and manipulating network communications to steal data or perform unauthorized operations.
- **Data breaches:** Unauthorized access to or acquisition of sensitive data.
**Risk Assessment**
Risk assessment is the process of identifying, analyzing, and evaluating the impact of network security threats on organizations. Risk assessment typically includes the following steps:
1. **Identifying threats:** Determine network security threats that may pose a threat to the organization.
2. **Analyzing threats:** Assess the likelihood and impact of each threat.
3. **Assessing risks:** Calculate the overall risk to the organization for each threat.
4. **Developing countermeasures:** Develop strategies and measures to address risks.
### 2.2 Crawler Detection Mechanisms and Countermeasures
**Crawler Detection Mechanisms**
Crawler detection m***mon crawler detection mechanisms include:
- **IP address blacklist:** Blocking access by listing known crawler IP addresses.
- **User-Agent identification:** Checking the User-Agent header to identify known crawlers.
- **Request pattern analysis:** Analyzing request patterns, such as request frequency, request size, and request interval, to identify crawler behavior.
- **CAPTCHA:** Displaying a CAPTCHA to users, requiring them to input it to distinguish between humans and crawlers.
- **Honeypots:** Setting up trap pages that mimic real pages to attract crawlers for behavior analysis.
**Countermeasures**
Crawler detection mechanisms can be countered, and these countermeasures include:
- **IP address rotation:** Using proxy servers or other techniques to rotate IP addresses, avoiding being blocked by IP address blacklists.
- **User-Agent spoofing:** Spoofing the User-Agent header to make it appear as if it is coming from a real browser.
- **Request frequency control:** Adjusting request frequency and intervals to avoid triggering request pattern analysis.
- **CAPTCHA cracking:** Using Optical Character Recognition (OCR) or machine learning technology to crack CAPTCHAs.
- **Honeypot evasion:** Analyzing the features of honeypot pages to identify and evade them.
# 3. Practical Application of Crawler Security Strategies
### 3.1 IP Address Management and Rotation
**Introduction**
An IP address is a unique address that identifies a device on the internet. When a crawler accesses a target website, it uses its IP address to send requests to the site. If a crawler uses a fixed IP address, the website can easily identify and block its access. Therefore, an important practice in crawler security strategies is the management and rotation of IP addresses.
**Methods**
There are

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Vue Select选择框数据监听秘籍:掌握数据流与$emit通信机制

# 摘要
本文深入探讨了Vue框架中Select组件的数据绑定和通信机制。从Vue Select组件与数据绑定的基础开始,文章逐步深入到Vue的数据响应机制,详细解析了响应式数据的初始化、依赖追踪,以及父子组件间的数据传递。第三章着重于Vue Select选择框的动态数据绑定,涵盖了高级用法、计算属性的优化,以及数据变化监听策略。第四章则专注于实现Vue Se
【操作秘籍】:施耐德APC GALAXY5000 UPS开关机与故障处理手册
# 摘要
本文对施耐德APC GALAXY5000 UPS进行全面介绍,涵盖了设备的概述、基本操作、故障诊断与处理、深入应用与高级管理,以及案例分析与用户经验分享。文章详细说明了UPS的开机、关机、常规检查、维护步骤及监控报警处理流程,同时提供了故障诊断基础、常见故障排除技巧和预防措施。此外,探讨了高级开关机功能、与其他系统的集成以及高级故障处理技术。最后,通过实际案例和用户经验交流,强调了该UPS在不同应用环境中的实用性和性能优化。
# 关键字
UPS;施耐德APC;基本操作;故障诊断;系统集成;案例分析
参考资源链接:[施耐德APC GALAXY5000 / 5500 UPS开关机步骤
wget自动化管理:编写脚本实现Linux软件包的批量下载与安装
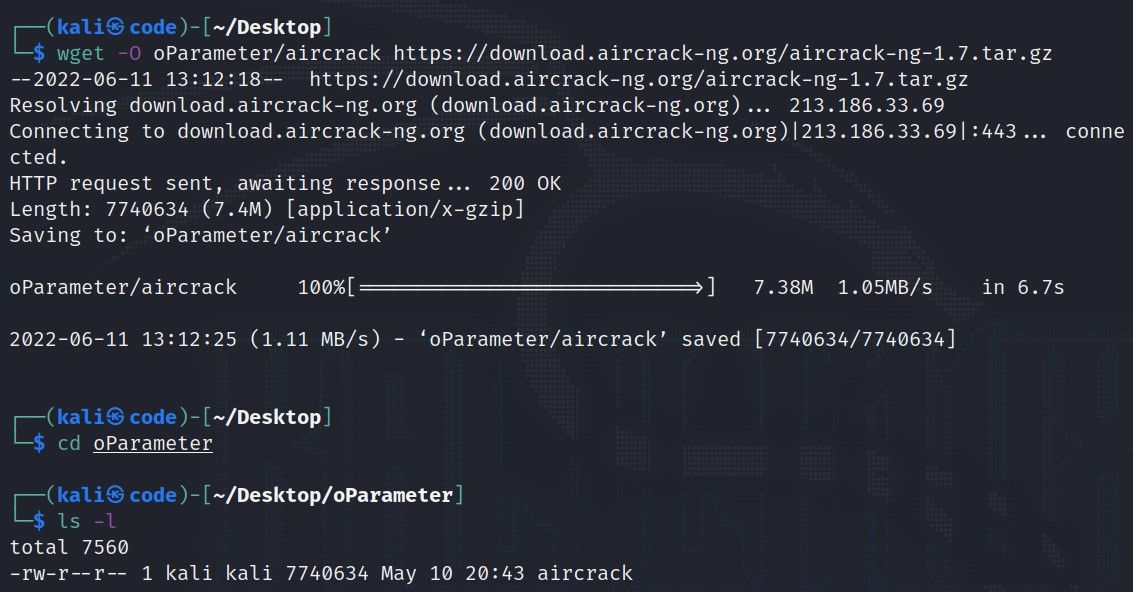
# 摘要
本文对wget工具的自动化管理进行了系统性论述,涵盖了wget的基本使用、工作原理、高级功能以及自动化脚本的编写、安装、优化和安全策略。首先介绍了wget的命令结构、选项参数和工作原理,包括支持的协议及重试机制。接着深入探讨了如何编写高效的自动化下载脚本,包括脚本结构设计、软件包信息解析、批量下载管理和错误
Java中数据结构的应用实例:深度解析与性能优化
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
SPiiPlus ACSPL+变量管理实战:提升效率的最佳实践案例分析

# 摘要
SPiiPlus ACSPL+是一种先进的控制系统编程语言,广泛应用于自动化和运动控制领域。本文首先概述了SPiiPlus ACSPL+的基本概念与变量管理基础,随后深入分析了变量类型与数据结构,并探讨了实现高效变量管理的策略。文章还通过实战技巧,讲解了变量监控、调试、性能优化和案例分析,同时涉及了高级应用,如动态内存管理、多线程变量同步以及面向对象的变
DVE基础入门:中文版用户手册的全面概览与实战技巧

# 摘要
本文旨在为初学者提供DVE(文档可视化编辑器)的入门指导和深入了解其高级功能。首先,概述了DVE的基础知识,包括用户界面布局和基本编辑操作,如文档的创建、保存、文本处理和格式排版。接着,本文探讨了DVE的高级功能,如图像处理、高级文本编辑技巧和特殊功能的使用。此外,还介绍了DVE的跨平台使用和协作功能,包括多用户协作编辑、跨平台兼容性以及与其他工具的整合。最后,通过
【Origin图表专业解析】:权威指南,坐标轴与图例隐藏_显示的实战技巧

# 摘要
本文系统地介绍了Origin软件中图表的创建、定制、交互功能以及性能优化,并通过多个案例分析展示了其在不同领域中的应用。首先,文章对Origin图表的基本概念、坐标轴和图例的显示与隐藏技巧进行了详细介绍,接着探讨了图表高级定制与性能优化的方法。文章第四章结合实战案例,深入分析了O
EPLAN Fluid团队协作利器:使用EPLAN Fluid提高设计与协作效率
# 摘要
EPLAN Fluid是一款专门针对流体工程设计的软件,它能够提供全面的设计解决方案,涵盖从基础概念到复杂项目的整个设计工作流程。本文从EPLAN Fluid的概述与基础讲起,详细阐述了设计工作流程中的配置优化、绘图工具使用、实时协作以及高级应用技巧,如自定义元件管理和自动化设计。第三章探讨了项目协作机制,包括数据管理、权限控制、跨部门沟通和工作流自定义。通过案例分析,文章深入讨论
【数据迁移无压力】:SGP.22_v2.0(RSP)中文版的平滑过渡策略

# 摘要
本文深入探讨了数据迁移的基础知识及其在实施SGP.22_v2.0(RSP)迁移时的关键实践。首先,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )