【Foundation】Web Crawler Practical: Scraping Static Web Page Text Data
发布时间: 2024-09-15 11:55:41 阅读量: 18 订阅数: 33 
# 2.1 HTTP Protocol and Web Page Structure Analysis
## 2.1.1 Fundamental Principles of HTTP Protocol
HTTP (Hypertext Transfer Protocol) is an application layer protocol used to transmit data between web browsers and web servers. Based on a request-response model, the client (typically a web browser) sends an HTTP request to the server, which processes the request and returns an HTTP response.
An HTTP request consists of the following parts:
* Request Line: Specifies the request method (e.g., GET, POST), the requested resource path, and the HTTP version.
* Request Headers: Contains additional information about the client and the request, such as User-Agent, Accept, and Content-Type.
* Request Body: Contains the data of the request (optional).
An HTTP response consists of the following parts:
* Status Line: Contains the HTTP status code (e.g., 200 OK), status message, and HTTP version.
* Response Headers: Contains additional information about the response, such as Content-Type, Content-Length, and Date.
* Response Body: Contains the data of the response (optional).
# 2. Web Page Text Data Crawling Practice
## 2.1 HTTP Protocol and Web Page Structure Analysis
### 2.1.1 Fundamental Principles of HTTP Protocol
HTTP (Hypertext Transfer Protocol) is a protocol for transmitting data between Web clients and servers. It is a stateless protocol, which means that each request is independent and the server does not store any information about the client's state.
An HTTP request consists of the following parts:
***Request Line:** Specifies the request method (e.g., GET or POST), the requested resource (e.g., URL), and the HTTP version.
***Request Headers:** Contains additional information about the client and the request, such as User-Agent, Content-Type, and Cookie.
***Request Body:** If the request is a POST request, it contains the data to be submitted to the server.
An HTTP response consists of the following parts:
***Status Line:** Specifies the response status code (e.g., 200 OK or 404 Not Found) and the HTTP version.
***Response Headers:** Contains additional information about the response, such as Content-Type, Content-Length, and Cache-Control.
***Response Body:** Contains the data sent from the server to the client.
### 2.1.2 Composition and Analysis of Web Page Structure
A web page is written in HTML (Hypertext Markup Language), which defines the structure and content of the web page. An HTML document consists of the following elements:
***Tags:** Used to define web page elements, such as titles, paragraphs, and lists.
***Attributes:** Provide additional information for tags, such as ID, class, and style.
***Content:***
***arse a web page, understanding HTML syntax and using parsing libraries such as Beautiful Soup or lxml is necessary. These libraries can convert an HTML document into an object tree, allowing easy access and manipulation of web page elements.
## 2.2 Web Page Text Data Extraction Techniques
### 2.2.1 Regular Expression Matching
Regular expressions are a powerful tool for matching string patterns. They can be used to extract specific text data from web pages, such as email addresses, phone numbers, and dates.
Regular expression syntax includes:
***Character Classes:** Match specific character sets, such as letters, numbers, and punctuation

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Epochs调优的自动化方法
# 1. Epochs在机器学习中的重要性
机器学习是一门通过算法来让计算机系统从数据中学习并进行预测和决策的科学。在这一过程中,模型训练是核心步骤之一,而Epochs(迭代周期)是决定模型训练效率和效果的关键参数。理解Epochs的重要性,对于开发高效、准确的机器学习模型至关重要。
在后续章节中,我们将深入探讨Epochs的概念、如何选择合适值以及影响调优的因素,以及如何通过自动化方法和工具来优化Epochs的设置,从而
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
【实时系统空间效率】:确保即时响应的内存管理技巧

# 1. 实时系统的内存管理概念
在现代的计算技术中,实时系统凭借其对时间敏感性的要求和对确定性的追求,成为了不可或缺的一部分。实时系统在各个领域中发挥着巨大作用,比如航空航天、医疗设备、工业自动化等。实时系统要求事件的处理能够在确定的时间内完成,这就对系统的设计、实现和资源管理提出了独特的挑战,其中最为核心的是内存管理。
内存管理是操作系统的一个基本组成部
【Python预测模型构建全记录】:最佳实践与技巧详解
# 1. Python预测模型基础
Python作为一门多功能的编程语言,在数据科学和机器学习领域表现得尤为出色。预测模型是机器学习的核心应用之一,它通过分析历史数据来预测未来的趋势或事件。本章将简要介绍预测模型的概念,并强调Python在这一领域中的作用。
## 1.1 预测模型概念
预测模型是一种统计模型,它利用历史数据来预测未来事件的可能性。这些模型在金融、市场营销、医疗保健和其
【批量大小与存储引擎】:不同数据库引擎下的优化考量

# 1. 数据库批量操作的理论基础
数据库是现代信息系统的核心组件,而批量操作作为提升数据库性能的重要手段,对于IT专业人员来说是不可或缺的技能。理解批量操作的理论基础,有助于我们更好地掌握其实践应用,并优化性能。
## 1.1 批量操作的定义和重要性
批量操作是指在数据库管理中,一次性执行多个数据操作命
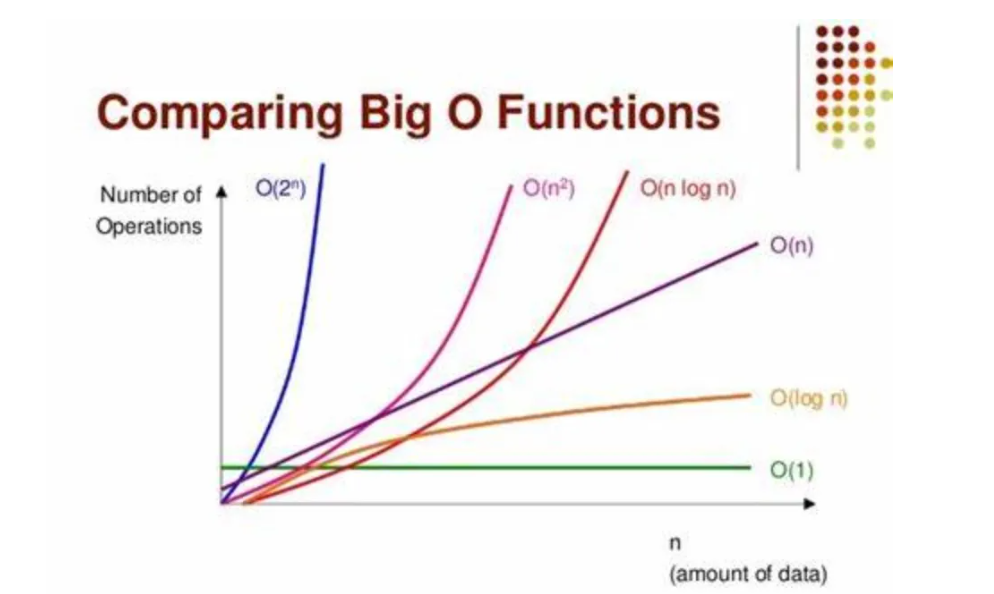
【算法竞赛中的复杂度控制】:在有限时间内求解的秘籍
# 1. 算法竞赛中的时间与空间复杂度基础
## 1.1 理解算法的性能指标
在算法竞赛中,时间复杂度和空间复杂度是衡量算法性能的两个基本指标。时间复杂度描述了算法运行时间随输入规模增长的趋势,而空间复杂度则反映了算法执行过程中所需的存储空间大小。理解这两个概念对优化算法性能至关重要。
## 1.2 大O表示法的含义与应用
大O表示法是用于描述算法时间复杂度的一种方式。它关注的是算法运行时
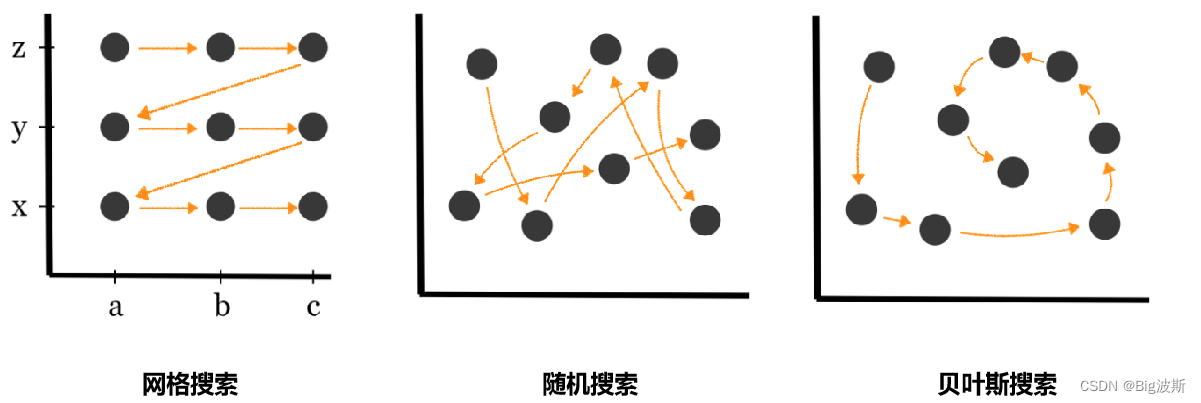
贝叶斯优化:智能搜索技术让超参数调优不再是难题
# 1. 贝叶斯优化简介
贝叶斯优化是一种用于黑盒函数优化的高效方法,近年来在机器学习领域得到广泛应用。不同于传统的网格搜索或随机搜索,贝叶斯优化采用概率模型来预测最优超参数,然后选择最有可能改进模型性能的参数进行测试。这种方法特别适用于优化那些计算成本高、评估函数复杂或不透明的情况。在机器学习中,贝叶斯优化能够有效地辅助模型调优,加快算法收敛速度,提升最终性能。
接下来,我们将深入探讨贝叶斯优化的理论基础,包括它的工作原理以及如何在实际应用中进行操作。我们将首先介绍超参数调优的相关概念,并探讨传统方法的局限性。然后,我们将深入分析贝叶斯优化的数学原理,以及如何在实践中应用这些原理。通过对
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
学习率与神经网络训练:影响研究与优化策略
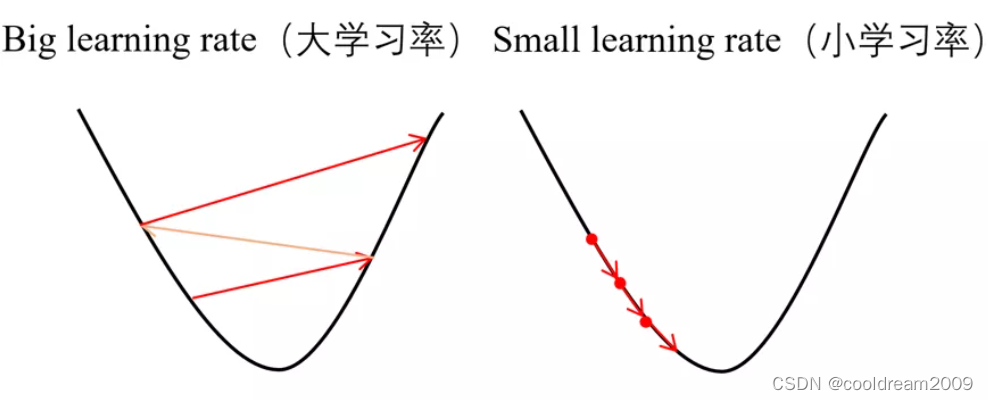
# 1. 学习率在神经网络训练中的作用
神经网络训练是一个复杂的优化过程,而学习率(Learning Rate)是这个过程中的关键超参数之一。学习率决定了在优化过程中,模型参数更新的步长大小。如果学习率设置得过高,可能会导致模型无法收敛,而过低的学习率则会使训练过程过慢,且有可能陷入局部最小值。选择合适的学习率,对提高模型性能、加速训练过程以及避免梯度消失或爆炸等问题至关重要。
学习率的调整能够影响模型
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )