【Basic】Detailed Explanation of HTTP Request Library Requests: Sending GET and POST Requests
发布时间: 2024-09-15 11:51:48 阅读量: 38 订阅数: 50 
# 2.1 GET Requests
### 2.1.1 Basic Usage of GET Requests
GET requests are the most commonly used HTTP method for retrieving resources from a server. The `get()` method is used in the Requests library to send GET requests, with the syntax as follows:
```python
requests.get(url, params=None, **kwargs)
```
Where:
* `url`: The URL address of the request
* `params`: The request parameters, passed in as a dictionary
* `**kwargs`: Other optional parameters, such as `headers`, `timeout`, etc.
For example, sending a simple GET request to get the content of Baidu's homepage:
```python
import requests
url = '***'
response = requests.get(url)
```
# 2. Using the Requests Library
### 2.1 GET Requests
#### 2.1.1 Basic Usage of GET Requests
GET requests are the most basic HTTP method, used for retrieving resources from a server. The `get()` method in the Requests library is used to send GET requests.
```python
import requests
url = '***'
response = requests.get(url)
```
The above code sends a GET request to the `/api/v1/users` endpoint of `***`. The `response` object contains the server's response.
#### 2.1.2 Passing Parameters in GET Requests
GET request parameters can be passed via the `params` parameter. `params` is a dictionary, where the keys are parameter names and the values are parameter values.
```python
params = {'page': 1, 'limit': 10}
response = requests.get(url, params=params)
```
The above code sends a GET request to the `/api/v1/users` endpoint of `***`, and passes `page` and `limit` as parameters.
### 2.2 POST Requests
#### 2.2.1 Basic Usage of POST Requests
POST requests are used to submit data to the server. The `post()` method in the Requests library is used to send POST requests.
```python
data = {'username': 'admin', 'password': 'password'}
response = requests.post(url, data=data)
```
The above code sends a POST request to the `/api/v1/users` endpoint of `***`, and submits `username` and `password` as data.
#### 2.2.2 Data Formats for POST Requests
Data for POST requests can be in various formats, including JSON, form data, and binary data. The Requests library provides `json` and `data` parameters to specify the data format.
```python
# JSON format
data = {'username': 'admin', 'password': 'password'}
response = requests.post(url, json=data)
# Form data format
data = {'username': 'admin', 'password': 'password'}
response = requests.post(url, data=data)
# Binary data format
data = b'...'
response = requests.post(url, data=data)
```
### 2.3 Other Request Methods
The Requests library also supports other HTTP methods, including HEAD, PUT, and DELETE. The usage of these methods is similar to GET and POST.
#### 2.3.1 HEAD Requests
HEAD requests are used to retrieve header information of a resource, without getting the content itself.
```python
response = requests.head(url)
```
#### 2.3.2 PUT Requests
PUT requests are used to update resources.
```python
data = {'username': 'admin', 'password': 'password'}
response = requests.put(url, data=data)
```
#### 2.3.3 DELETE Requests
DELETE requests are used to delete resources.
```python
response = requests.delete(url)
```
# 3.1 Response Status Codes
#### 3.1.1 Meanings of Common Status Codes
HTTP response status codes are three-digit codes that indicate the server'***mon HTTP status codes and their meanings are as follows:
| Status Code | Meaning |
|---|---|
| 200 | OK |
| 201 | Created |
| 204 | No Content |
| 301 | Moved Permanently |
| 302 | Found |
| 400 | Bad Request |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not Found |
| 500 | Internal Server Error |
| 502 | Bad Gateway |
| 503 | Service Unavailable |
#### 3.1.2 Handling Responses with Different Status Codes
When using the Requests library to send requests, we can obtain the response status code through the `response.status_code` attribute. Based on different status codes, we can adopt different handling strategies:
- **200 OK:** Indicates a successful request, we can directly parse the response content.
- **201 Created:** Indicates the request successfully created a resource, we can obtain the `Location` header field to get the URI of the new resource.
- **204 No Content:** Indicates a successful request, but no content is returned.
- **301 Moved Permanently:** Indicates that the requested resource has been permanently moved to a new URI, we can obtain the new URI through the `Location` header field.
- **302 Found:** Indicates that the requested resource has been temporarily moved to a new URI, we can obtain the new URI through the `Location` header field.
- **400 Bad Request:** Indicates a request syntax error, we can check if the request parameters are correct.
- **401 Unauthorized:** Indicates that the request is unauthorized, we can check if the request headers contain correct authorization information.
- **403 Forbidden:** Indicates that the request is forbidden, we can check if the request permissions are correct.
- **404 Not Found:** Indicates that the requested resource does not exist, we can check if the requested URI is correct.
- **500 Internal Server Error:** Indicates a server internal error, we can contact the server administrator to resolve the issue.
- **502 Bad Gateway:** Indicates that the server received an invalid response as a gateway or proxy, we can check if the server configuration is correct.
- **503 Service Unavailable:** Indicates that the server is temporarily unavailable, we can try again later.
### 3.2 Response Content
#### 3.2.1 Obtaining Response Content
The Requests library provides several methods to obtain response content, including:
- **`response.text`**: Gets the text form of the response content.
- **`response.json()`**: Gets the JSON format of the response content.
- **`response.content`**: Gets the binary form of the response content.
- **`response.raw`**: Gets the raw byte stream of the response content.
#### 3.2.2 Parsing Response Content
Depending on the format of the response content, we can use different methods to parse:
- **Text format:** Can be parsed using regular expressions, HTML parsers, or XML parsers.
- **JSON format:** Can be parsed using the `json` module.
- **Binary format:** Can be parsed using the `struct` module or other binary data parsing libraries.
- **Raw byte stream:** Can be parsed using the `io` module or other byte stream processing libraries.
# 4. Session Management in the Requests Library
### 4.1 Session Object
#### 4.1.1 Creating and Using Session Objects
Session objects are used to manage HTTP sessions; they can maintain session state across multiple requests. The Requests library provides the `requests.Session()` function to create Session objects.
```python
import requests
# Create a Session object
session = requests.Session()
# Send requests using the Session object
response = session.get("***")
```
#### 4.1.2 Persistence of Session Objects
Session objects can be persisted to disk so that they can still be used after the program restarts. The Requests library provides `session.save()` and `session.load()` methods to achieve persistence.
```python
# Persist the Session object
session.save("session.pkl")
# Load the persisted Session object
session = requests.Session()
session.load("session.pkl")
```
### 4.2 Cookie Management
#### 4.2.1 Obtaining and Setting Cookies
Cookies are small chunks of data sent by the server to the client to recognize the client in subsequent requests. The Requests library provides the `session.cookies` attribute to obtain and set Cookies.
```python
# Obtain Cookies
cookies = session.cookies
# Set a Cookie
session.cookies["name"] = "value"
```
#### 4.2.2 Persistence of Cookies
Cookies can also be persisted to disk for later use after the program restarts. The Requests library provides `session.cookies.save()` and `session.cookies.load()` methods to achieve this.
```python
# Persist Cookies
session.cookies.save("cookies.pkl")
# Load persisted Cookies
session.cookies.load("cookies.pkl")
```
### 4.3 Interaction between Session and Cookie
There is a close interaction between Session objects and Cookies. Session objects can manage Cookies, while Cookies can help Session objects maintain session state.
When sending requests using a Session object, the Session object will automatically send the Cookies associated with the session to the server. Once the server receives the Cookies, it can recognize the client and provide the appropriate response.
### 4.4 Application Scenarios for Session and Cookie
Session and Cookie are particularly useful in the following scenarios:
- **User Authentication:** Cookies can store user login status to enable automatic login in subsequent requests.
- **Shopping Cart Management:** Cookies can store shopping cart information to maintain the state of the shopping cart across different pages.
- **Personalized Recommendations:** Cookies can store user browsing history and preferences to provide personalized recommendations.
# 5. Exception Handling in the Requests Library
When using the Requests library to make HTTP requests, various exceptions may occur. These exceptions may be caused by network connection issues, server response issues, or coding errors. It is crucial to properly handle these exceptions to ensure the robustness and reliability of the application.
### 5.1 Common Exception Types
Common exception types thrown by the Requests library include:
- **ConnectionError:** Thrown when a connection to the server cannot be established. This could be due to network connection issues or the server being unavailable.
- **TimeoutError:** Thrown when a request times out. This could be due to slow server responses or network delays.
- **HTTPError:** Thrown when the server returns a non-200 status code. This indicates that the server has encountered an error or cannot process the request.
### 5.2 Strategies for Handling Exceptions
To handle exceptions thrown by the Requests library, the following strategies can be adopted:
#### 5.2.1 Retry Mechanism
For connection errors and timeout errors, a retry mechanism can be implemented. The retry mechanism allows the application to automatically retry requests when errors occur, until successful or the maximum number of retries is reached.
#### 5.2.2 Logging
For all exceptions, detailed information should be logged, including the exception type, error message, and stack trace. This helps diagnose problems and track the status of the application.
#### 5.2.3 Example of Exception Handling Code
The following code example demonstrates how to use a try-except block to handle exceptions thrown by the Requests library:
```python
try:
response = requests.get(url)
except ConnectionError as e:
# Handle connection errors
print("Unable to connect to the server:", e)
except TimeoutError as e:
# Handle timeout errors
print("Request timed out:", e)
except HTTPError as e:
# Handle HTTP errors
print("Server returned an error:", e)
```
In practical applications, the logic for exception handling can be customized according to specific needs. For instance, for connection errors, an exponential backoff retry strategy can be implemented to avoid putting too much pressure on the server. For HTTP errors, different actions can be taken based on the status code, such as redirection or displaying error messages.
# 6.1 Proxy Settings
### 6.1.1 Configuration and Usage of Proxies
In some cases, a proxy server is needed to access network resources, for example:
- To circumvent network restrictions
- To hide the real IP address
- To increase access speed
The Requests library supports proxies, which can be configured using the `proxies` parameter, as follows:
```python
proxies = {
"http": "***<proxy server address>:<port>",
"https": "***<proxy server address>:<port>"
}
```
For example, accessing Baidu using an HTTP proxy server:
```python
import requests
proxies = {
"http": "***"
}
response = requests.get("***", proxies=proxies)
```
### 6.1.2 Verification of Proxies
Some proxy servers require authentication, and the Requests library supports providing authentication information through the `auth` parameter, as follows:
```python
auth = (
"<username>",
"<password>"
)
```
For example, accessing Baidu using an authenticated HTTP proxy server:
```python
import requests
proxies = {
"http": "***"
}
auth = ("username", "password")
response = requests.get("***", proxies=proxies, auth=auth)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
矢量控制技术深度解析:电气机械理论与实践应用全指南
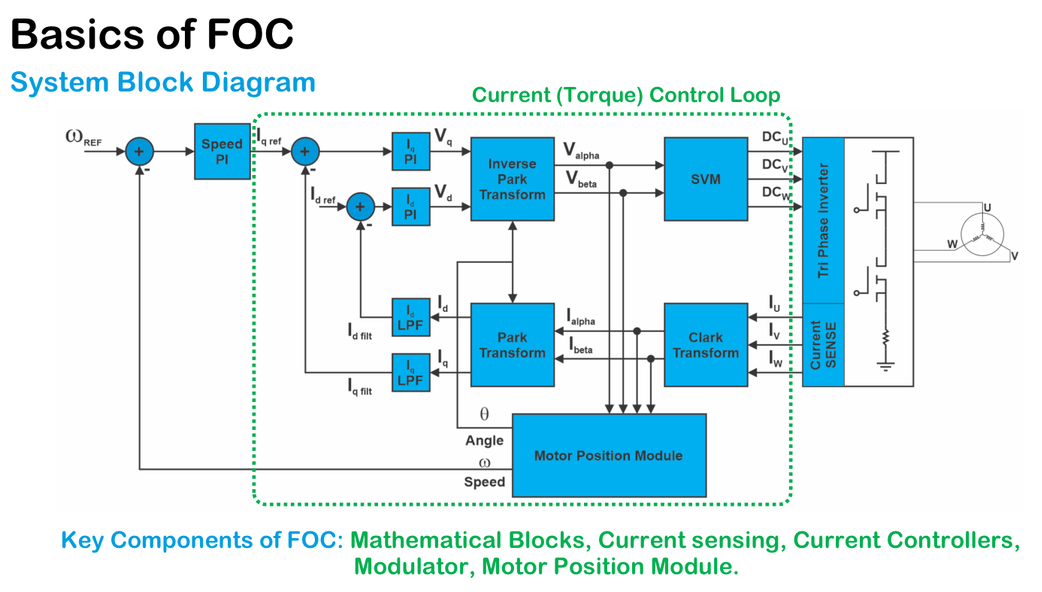
# 摘要
矢量控制技术是电力电子和电气传动领域的重要分支,它通过模拟直流电机的性能来控制交流电机,实现高效率和高精度的电机控制。本文首先概述了矢量控制的基本概念和理论基础,包括电气机械控制的数学模型、矢量变换理论以及相关的数学工具,如坐标变换、PI调节器和PID控制。接着,文章探讨了矢量控制技术在硬件和软件层面的实现,包括电力
【深入解析】:掌握Altium Designer PCB高级规则的优化设置
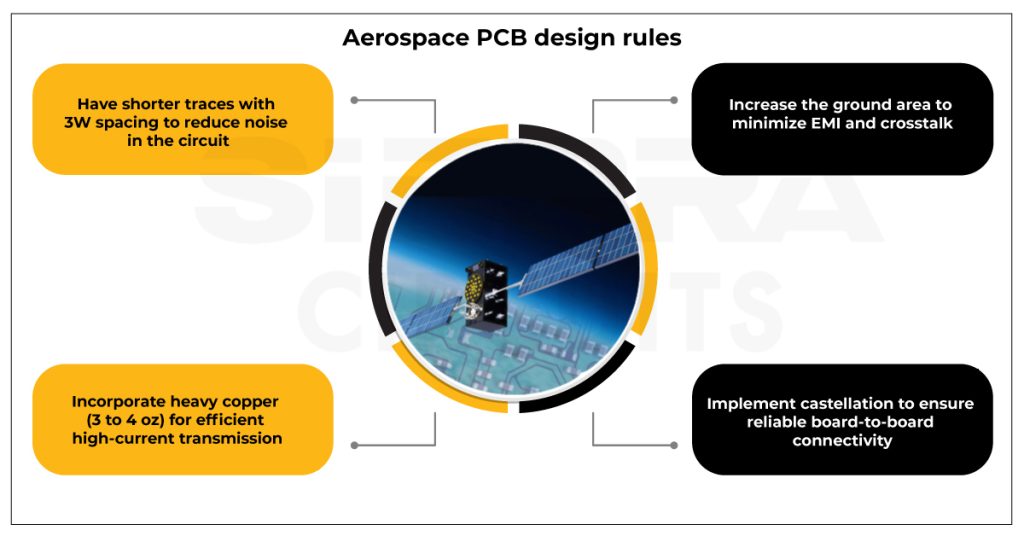
# 摘要
随着电子设备的性能需求日益增长,PCB设计的复杂性和精确性要求也在提升。Altium Designer作为领先的电子设计自动化软件,其高级规则对确保PCB设计质量起着至关重要的作用。本文详细介绍了Altium Designer PCB设计的基础知识、高级规则的理论基础、实际应用、进阶技巧以及优化案例研究,强调了
Oracle11g x32位在Linux下的安全设置:全面保护数据库的秘诀

# 摘要
Oracle 11g数据库安全是保障企业数据资产的关键,涉及多个层面的安全加固和配置。本文从操作系统层面的安全加固出发,探讨了用户和权限管理、文件系统的安全配置,以及网络安全的考量。进一步深入分析了Oracle 11g数据库的安全设置,如身份验证和授权机制、审计策略实施和数据加密技术的应用。文章还介绍了数据库内部的安全策略,包括安全配置的高级选项、防护措
RJ接口升级必备:技术演进与市场趋势的前瞻性分析

# 摘要
RJ接口作为通信和网络领域的重要连接器,其基础知识和演进历程对技术发展具有深远影响。本文首先回顾了RJ接口的发展历史和技术革新,分析了其物理与电气特性以及技术升级带来的高速数据传输与抗干扰能力的提升。然后,探讨了RJ接口在不同行业应用的现状和特点,包括在通信、消费电子和工业领域的应用案例。接着,文章预测了RJ接口市场的未来趋势,包括市场需求、竞争环境和标准化进程。
MATLAB线性方程组求解:这4种策略让你效率翻倍!
# 摘要
MATLAB作为一种高效的数学计算和仿真工具,在解决线性方程组方面展现出了独特的优势。本文首先概述了MATLAB求解线性方程组的方法,并详细介绍了直接法和迭代法的基本原理及其在MATLAB中的实现。直接法包括高斯消元法和LU分解,而迭代法涵盖了雅可比法、高斯-赛德尔法和共轭梯度法等。本文还探讨了矩阵分解技术的优化应用,如QR分解和奇异值分解(SVD),以及它们在提升求解效率和解决实际问题中的作用。最后,通过具体案例分析,本文总结了工程应用中不同类型线性方程组的求解策略,并提出了优化求解效率的建议。
# 关键字
MATLAB;线性方程组;高斯消元法;LU分解;迭代法;矩阵分解;数值稳
【效率提升算法设计】:算法设计与分析的高级技巧
# 摘要
本文全面探讨了算法设计的基础知识、分析技术、高级技巧以及实践应用,并展望了未来算法的发展方向。第一章概述了算法设计的基本概念和原则,为深入理解算法提供了基础。第二章深入分析了算法的时间复杂度与空间复杂度,并探讨了算法的正确性证明和性能评估方法。第三章介绍了高级算法设计技巧,包括分治策略、动态规划和贪心算法的原理和应用。第四章将理论与实践相结合,讨论了数据结构在算法设计中的应用、算法设计模式和优化策略。最后一章聚焦于前
【全面性能评估】:ROC曲线与混淆矩阵在WEKA中的应用

# 摘要
本文从性能评估的角度,系统介绍了ROC曲线和混淆矩阵的基本概念、理论基础、计算方法及其在WEKA软件中的应用。首先,本文对ROC曲线进行了深入
MTi故障诊断到性能优化全攻略:保障MTi系统稳定运行的秘诀

# 摘要
本文系统地阐述了MTi系统的故障诊断和性能调优的理论与实践。首先介绍了MTi系统故障诊断的基础知识,进而详细分析了性能分析工具与方法。实践应用章节通过案例研究展示了故障诊断方法的具体操作。随后,文章讨论了MTi系统性能调优策略,并提出了保障系统稳定性的措施。最后,通过案例分析总结了经验教训,为类似系统的诊断和优化提供了宝贵的参考。本文
数字电路实验三进阶课程:高性能组合逻辑设计的7大技巧

# 摘要
组合逻辑设计是数字电路设计中的核心内容,对提升系统的性能与效率至关重要。本文首先介绍了组合逻辑设计的基础知识及其重要性,随后深入探讨了高性能组合逻辑设计的理论基础,包括逻辑门的应用、逻辑简化原理、时间分析及组合逻辑电路设计的优化。第三章详细阐述了组合逻辑设计的高级技巧,如逻辑电路优化重构、流水线技术的结合以及先进设计方法学的应用。第四章通过实践应用探讨了设计流程、仿真验证
【CUDA图像处理加速技术】:中值滤波的稀缺优化策略与性能挑战分析

# 摘要
随着并行计算技术的发展,CUDA已成为图像处理领域中加速中值滤波算法的重要工具。本文首先介绍了CUDA与图像处理基础,然后详细探讨了CUDA中值滤波算法的理论和实现,包括算法概述、CUDA的并行编程模型以及优化策略。文章进一步分析了中值滤波算法面临的性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )