【Advanced Level】Advanced Anti-Crawling Strategies and Countermeasures: Using Machine Learning to Identify Anti-Crawling Mechanisms
发布时间: 2024-09-15 12:43:32 阅读量: 22 订阅数: 30 
# 1. Overview of Anti-Crawling Strategies
Anti-crawling strategies aim to prevent or slow down unauthorized web crawlers' access to websites or applications. These strategies are crucial for protecting sensitive data, preventing service disruptions, and maintaining website performance. Anti-crawling strategies typically involve various technologies, including:
***Feature-based identification:** Identifying crawler features such as HTTP request headers, response characteristics, and behavioral patterns.
***Machine learning-based identification:** Using machine learning algorithms to train models to recognize crawlers, such as anomaly detection and classification algorithms.
***Circumventing anti-crawling mechanisms:** Using proxies, IP pools, browser fingerprint spoofing, and CAPTCHA cracking to bypass anti-crawling strategies.
***Optimizing crawling strategies:** Adjusting crawling frequency, concurrency control, request header spoofing, and data parsing to optimize crawler performance and reduce the risk of detection.
# 2. The Application of Machine Learning in Anti-Crawling
### 2.1 Selection of Machine Learning Algorithms
In the field of anti-crawling, the choice of machine learning algorithms is crucial. Depending on different anti-crawling scenarios and data characteristics, appropriate algorithm types can be selected.
#### 2.1.1 Supervised Learning Algorithms
Supervised learning algorithms require labeled data for training, aiming to learn the mapping relationship between input data and output labels. In anti-crawling, common supervised learning algorithms include:
- **Logistic Regression:** Used for binary classification problems, such as distinguishing between crawlers and normal users.
- **Support Vector Machines:** Used for classification and regression problems, possessing good generalization ability and robustness.
- **Decision Trees:** Used for classification and regression problems, easy to understand and interpret.
#### 2.1.2 Unsupervised Learning Algorithms
Unsupervised learning algorithms do not require labeled data for training, aiming to discover hidden patterns and structures in the data. In anti-crawling, common unsupervised learning algorithms include:
- **Clustering Algorithms:** Used to group data points into different categories, potentially identifying crawler clusters.
- **Anomaly Detection Algorithms:** Used to detect data points that differ from normal data, potentially identifying suspicious crawler behavior.
- **Dimensionality Reduction Algorithms:** Used to reduce data dimensions, extract key features, potentially improving the efficiency of machine learning models.
### 2.2 Training and Evaluation of Machine Learning Models
#### 2.2.1 Data Preprocessing and Feature Engineering
Before training machine learning models, data preprocessing and feature engineering are necessary, including:
- **Data Cleaning:** Remove missing values, outliers, and noisy data.
- **Feature Extraction:** Extract features related to anti-crawling from raw data, such as HTTP request headers, response characteristics, and behavioral patterns.
- **Feature Selection:** Select the most discriminative and relevant features to avoid overfitting.
#### 2.2.2 Model Training and Param***
***mon parameter optimization methods include:
- **Grid Search:** Perform a grid search within a given parameter range to find the optimal combination of parameters.
- **Bayesian Optimization:** Based on Bayes' theorem, iteratively update parameters to improve search efficiency.
- **Gradient Descent:** Compute parameter gradients and update parameters along the gradient direction until convergence.
#### 2.2.3 Model Evaluation and Performance Metrics
After training, ***mon performance metrics include:
- **Accuracy:** The ratio of the number of correctly predicted samples to the total number of samples.
- **Recall:** The ratio of the number of correctly predicted positive samples to the total number of actual positive samples.
- **F1 Score:** The harmonic mean of accuracy and recall, considering both accuracy and recall.
# 3. Identification of Anti-Crawling Mechanisms
### 3.1 Feature-based Identification Methods
Feature-based identification methods analyze specific features in network requests and responses to identify crawlers. These features include:
#### 3.1.1 HTTP Request Header Features
***User-Agent:** Crawlers typically use non-standard User-Agent strings, indicating they are automated programs.
***Referer:** Crawlers often lack a Referer header, or the Referer header points to non-ex

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Highcharter包创新案例分析:R语言中的数据可视化,新视角!

# 1. Highcharter包在数据可视化中的地位
数据可视化是将复杂的数据转化为可直观理解的图形,使信息更易于用户消化和理解。Highcharter作为R语言的一个包,已经成为数据科学家和分析师展示数据、进行故事叙述的重要工具。借助Highcharter的高级定制
【R语言高级用户必读】:rbokeh包参数设置与优化指南
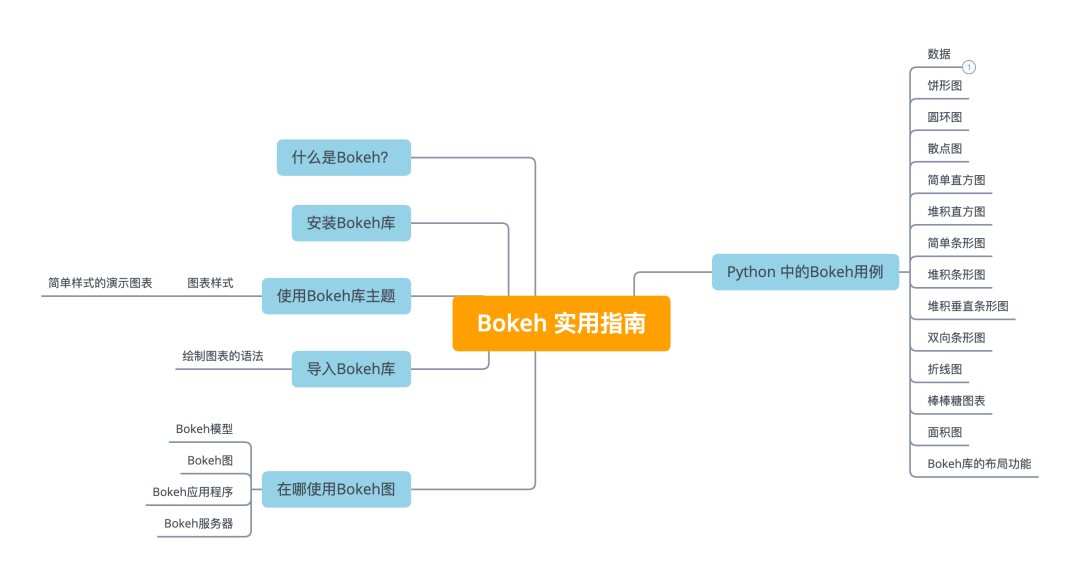
# 1. R语言和rbokeh包概述
## 1.1 R语言简介
R语言作为一种免费、开源的编程语言和软件环境,以其强大的统计分析和图形表现能力被广泛应用于数据科学领域。它的语法简洁,拥有丰富的第三方包,支持各种复杂的数据操作、统计分析和图形绘制,使得数据可视化更加直观和高效。
## 1.2 rbokeh包的介绍
rbokeh包是R语言中一个相对较新的可视化工具,它为R用户提供了一个与Python中Bokeh库类似的
【R语言进阶课程】:用visNetwork包深入分析社交网络

# 1. 社交网络分析基础
社交网络分析是一种研究社会关系结构的方法,它能够揭示个体或组织之间的复杂连接模式。在IT行业中,社交网络分析可以用于优化社交平台的用户体验,提升数据处理效率,或是在数据科学领域中挖掘潜在信息。本章节将介绍社交网络分析的基本概念、重要性,以及如何将其应用于解决现实世
【R语言数据包与大数据】:R包处理大规模数据集,专家技术分享
# 1. R语言基础与数据包概述
## 1.1 R语言简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。自1997年由Ross Ihaka和Robert Gentleman创建以来,它已经发展成为数据分析领域不可或缺的工具,尤其在统计计算和图形表示方面表现出色。
## 1.2 R语言的特点
R语言具备高度的可扩展性,社区贡献了大量的数据
R语言在遗传学研究中的应用:基因组数据分析的核心技术

# 1. R语言概述及其在遗传学研究中的重要性
## 1.1 R语言的起源和特点
R语言是一种专门用于统计分析和图形表示的编程语言。它起源于1993年,由Ross Ihaka和Robert Gentleman在新西兰奥克兰大学创建。R语言是S语言的一个实现,具有强大的计算能力和灵活的图形表现力,是进行数据分析、统计计算和图形表示的理想工具。R语言的开源特性使得它在全球范围内拥有庞大的社区支持,各种先
【大数据环境】:R语言与dygraphs包在大数据分析中的实战演练

# 1. R语言在大数据环境中的地位与作用
随着数据量的指数级增长,大数据已经成为企业与研究机构决策制定不可或缺的组成部分。在这个背景下,R语言凭借其在统计分析、数据处理和图形表示方面的独特优势,在大数据领域中扮演了越来越重要的角色。
## 1.1 R语言的发展背景
R语言最初由罗伯特·金特门(Robert Gentleman)和罗斯·伊哈卡(Ross Ihaka)在19
【R语言与Hadoop】:集成指南,让大数据分析触手可及

# 1. R语言与Hadoop集成概述
## 1.1 R语言与Hadoop集成的背景
在信息技术领域,尤其是在大数据时代,R语言和Hadoop的集成应运而生,为数据分析领域提供了强大的工具。R语言作为一种强大的统计计算和图形处理工具,其在数据分析领域具有广泛的应用。而Hadoop作为一个开源框架,允许在普通的
【数据动画制作】:ggimage包让信息流动的艺术

# 1. 数据动画制作概述与ggimage包简介
在当今数据爆炸的时代,数据动画作为一种强大的视觉工具,能够有效地揭示数据背后的模式、趋势和关系。本章旨在为读者提供一个对数据动画制作的总览,同时介绍一个强大的R语言包——ggimage。ggimage包是一个专门用于在ggplot2框架内创建具有图像元素的静态和动态图形的工具。利用ggimage包,用户能够轻松地将静态图像或动
ggflags包在时间序列分析中的应用:展示随时间变化的国家数据(模块化设计与扩展功能)

# 1. ggflags包概述及时间序列分析基础
在IT行业与数据分析领域,掌握高效的数据处理与可视化工具至关重要。本章将对`ggflags`包进行介绍,并奠定时间序列分析的基础知识。`ggflags`包是R语言中一个扩展包,主要负责在`ggplot2`图形系统上添加各国旗帜标签,以增强地理数据的可视化表现力。
时间序列分析是理解和预测数
数据科学中的艺术与科学:ggally包的综合应用

# 1. ggally包概述与安装
## 1.1 ggally包的来源和特点
`ggally` 是一个为 `ggplot2` 图形系统设计的扩展包,旨在提供额外的图形和工具,以便于进行复杂的数据分析。它由 RStudio 的数据科学家与开发者贡献,允许用户在 `ggplot2` 的基础上构建更加丰富和高级的数据可视化图
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )