【Basic】Data Extraction Skills: The Application of Regular Expressions in Web Crawling
发布时间: 2024-09-15 11:53:50 阅读量: 26 订阅数: 50 
# **1. Fundamentals: Data Extraction Techniques - The Application of Regular Expressions in Web Scraping**
Regular Expressions (Regex) are a powerful tool for text pattern matching, utilizing a set of special characters and syntactic rules to define the text patterns to be matched. The basic syntax of regular expressions includes:
- **Matching Characters:** `.` matches any single character, `[abc]` matches any one of the characters within the square brackets, and `[^abc]` matches any character not in the square brackets.
- **Repetition Matching:** `*` matches the preceding character 0 or more times, `+` matches the preceding character 1 or more times, `?` matches the preceding character 0 or 1 time.
- **Grouping:** `()` groups expressions, allowing for operations to be performed on them, such as referencing or repeating.
- **Anchors:** `^` matches the start of a string, `$` matches the end of a string.
- **Escape Characters:** `\` escapes special characters, removing their special meaning.
# 2. The Application of Regular Expressions in Data Extraction
Regular Expressions (Regex) are a powerful pattern-matching language that allows us to match and extract complex data patterns using concise syntax. In the realm of data extraction, regular expressions play a crucial role as they help us quickly and accurately extract the required information from unstructured text.
### 2.1 Basic Syntax of Regular Expressions
A regular expression consists of a series of metacharacters and literal characters, where metacharacters have special meanings, and literal characters match themselves. Below are some commonly used regular expression metacharacters:
| Metacharacter | Meaning |
|---|---|
| `.` | Matches any single character |
| `*` | Matches the preceding character zero or more times |
| `+` | Matches the preceding character one or more times |
| `?` | Matches the preceding character zero or one time |
| `[]` | Matches any single character within the brackets |
| `^` | Matches the start of the string |
| `$` | Matches the end of the string |
For example, the following regular expression matches any word starting with the letter "a":
```
^a.*
```
### 2.2 Advanced Applications of Regular Expressions
Beyond basic syntax, regular expressions offer many advanced features, such as:
- **Grouping and Referencing:** Use parentheses `()` to group sub-expressions and `\n` to refer to the nth group.
- **Conditional Matching:** Use the `|` separator to match multiple options.
- **Backreferences:** Use `\b` to match word boundaries.
- **Greedy and Non-Greedy Matching:** Use `+?` and `*?` to control the greediness of the match.
### 2.3 The Practical Application of Regular Expressions in Data Extraction
In data extraction, regular expressions can be used for a variety of tasks, such as:
- **Extracting Email Addresses:**
```
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}
```
- **Extracting Phone Numbers:**
```
(\d{3}[-.\s]??\d{3}[-.\s]??\d{4}|\(\d{3}\)\s*\d{3}[-.\s]??\d{4}|\d{3}[-.\s]??\d{4})
```
- **Extracting Dates:**
```
(0[1-9]|[12]\d|3[01])[- /.](0[1-9]|1[012])[- /.](19|20)\d\d
```
**Code Block:**
```python
import re
text = "John Doe, 123 Main Street, Anytown, CA 12345, john.***"
# Extracting Name
name = re.search(r"^(.*?),", text).group(1)
# Extracting Address
address = re.search(r"^(.*?), \d{5}", text).group(1)
# Extracting Email Address
email = re.search(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}", text)
print(name)
print(address)
print(email)
```
**Logical Analysis:**
- The `re.search()` function is used to search for the first substring in the string that matches the regular expression.
- The `group(1)` method re

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AMESim液压仿真秘籍:专家级技巧助你从基础飞跃至顶尖水平

# 摘要
AMESim液压仿真软件是工程师们进行液压系统设计与分析的强大工具,它通过图形化界面简化了模型建立和仿真的流程。本文旨在为用户提供AMESim软件的全面介绍,从基础操作到高级技巧,再到项目实践案例分析,并对未来技术发展趋势进行展望。文中详细说明了AMESim的安装、界面熟悉、基础和高级液压模型的建立,以及如何运行、分析和验证仿真结果。通过探索自定义组件开发、多学科仿真集成以及高级仿真算法的应用,本文
【高频领域挑战】:VCO设计在微波工程中的突破与机遇
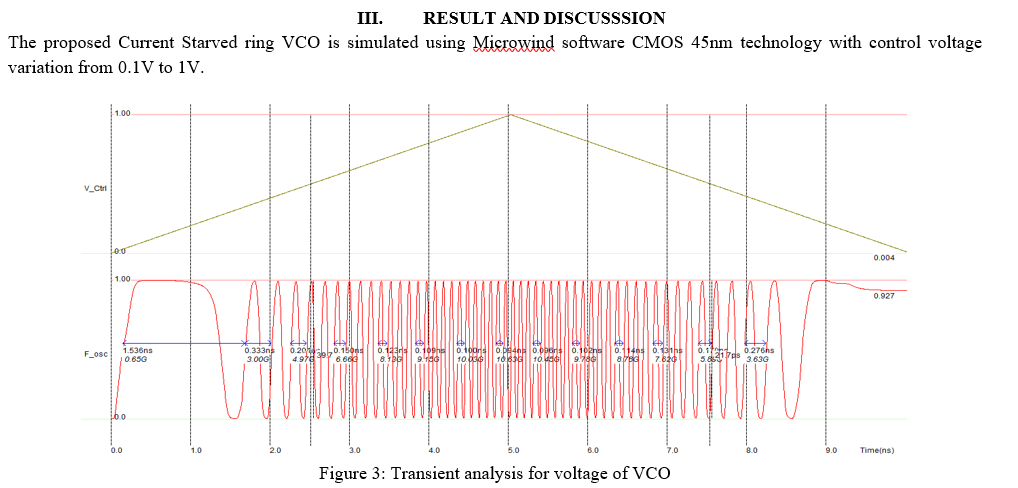
# 摘要
本论文深入探讨了压控振荡器(VCO)的基础理论与核心设计原则,并在微波工程的应用技术中展开详细讨论。通过对VCO工作原理、关键性能指标以及在微波通信系统中的作用进行分析,本文揭示了VCO设计面临的主要挑战,并提出了相应的技术对策,包括频率稳定性提升和噪声性能优化的方法。此外,论文还探讨了VCO设计的实践方法、案例分析和故障诊断策略,最后对VCO设计的创新思路、新技术趋势及未来发展挑战
实现SUN2000数据采集:MODBUS编程实践,数据掌控不二法门
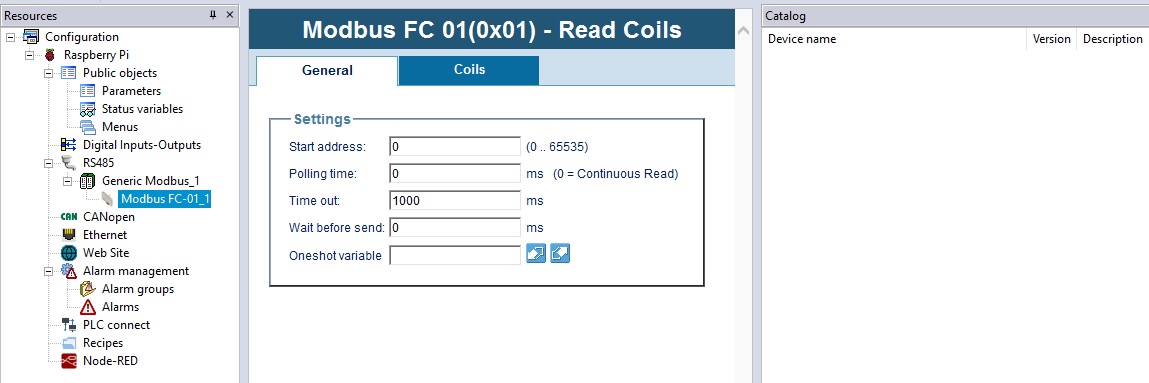
# 摘要
本文系统地介绍了MODBUS协议及其在数据采集中的应用。首先,概述了MODBUS协议的基本原理和数据采集的基础知识。随后,详细解析了MODBUS协议的工作原理、地址和数据模型以及通讯模式,包括RTU和ASCII模式的特性及应用。紧接着,通过Python语言的MODBUS库,展示了MODBUS数据读取和写入的编程实践,提供了具体的实现方法和异常管理策略。本文还结合SUN20
【性能调优秘籍】:深度解析sco506系统安装后的优化策略
# 摘要
本文对sco506系统的性能调优进行了全面的介绍,首先概述了性能调优的基本概念,并对sco506系统的核心组件进行了介绍。深入探讨了核心参数调整、磁盘I/O、网络性能调优等关键性能领域。此外,本文还揭示了高级性能调优技巧,包括CPU资源和内存管理,以及文件系统性能的调整。为确保系统的安全性能,文章详细讨论了安全策略、防火墙与入侵检测系统的配置,以及系统审计与日志管理的优化。最后,本文提供了系统监控与维护的
网络延迟不再难题:实验二中常见问题的快速解决之道
# 摘要
网络延迟是影响网络性能的重要因素,其成因复杂,涉及网络架构、传输协议、硬件设备等多个方面。本文系统分析了网络延迟的成因及其对网络通信的影响,并探讨了网络延迟的测量、监控与优化策略。通过对不同测量工具和监控方法的比较,提出了针对性的网络架构优化方案,包括硬件升级、协议配置调整和资源动态管理等。
期末考试必备:移动互联网商业模式与用户体验设计精讲

# 摘要
移动互联网的迅速发展带动了商业模式的创新,同时用户体验设计的重要性日益凸显。本文首先概述了移动互联网商业模式的基本概念,接着深入探讨用户体验设计的基础,包括用户体验的定义、重要性、用户研究方法和交互设计原则。文章重点分析了移动应用的交互设计和视觉设计原则,并提供了设计实践案例。之后,文章转向移动商业模式的构建与创新,探讨了商业模式框架
【多语言环境编码实践】:在各种语言环境下正确处理UTF-8与GB2312

# 摘要
随着全球化的推进和互联网技术的发展,多语言环境下的编码问题变得日益重要。本文首先概述了编码基础与字符集,随后深入探讨了多语言环境所面临的编码挑战,包括字符编码的重要性、编码选择的考量以及编码转换的原则和方法。在此基础上,文章详细介绍了UTF-8和GB2312编码机制,并对两者进行了比较分析。此外,本文还分享了在不同编程语言中处理编码的实践技巧,
【数据库在人事管理系统中的应用】:理论与实践:专业解析

# 摘要
本文探讨了人事管理系统与数据库的紧密关系,分析了数据库设计的基础理论、规范化过程以及性能优化的实践策略。文中详细阐述了人事管理系统的数据库实现,包括表设计、视图、存储过程、触发器和事务处理机制。同时,本研究着重讨论了数据库的安全性问题,提出认证、授权、加密和备份等关键安全策略,以及维护和故障处理的最佳实践。最后,文章展望了人事管理系统的发展趋
【Docker MySQL故障诊断】:三步解决权限被拒难题
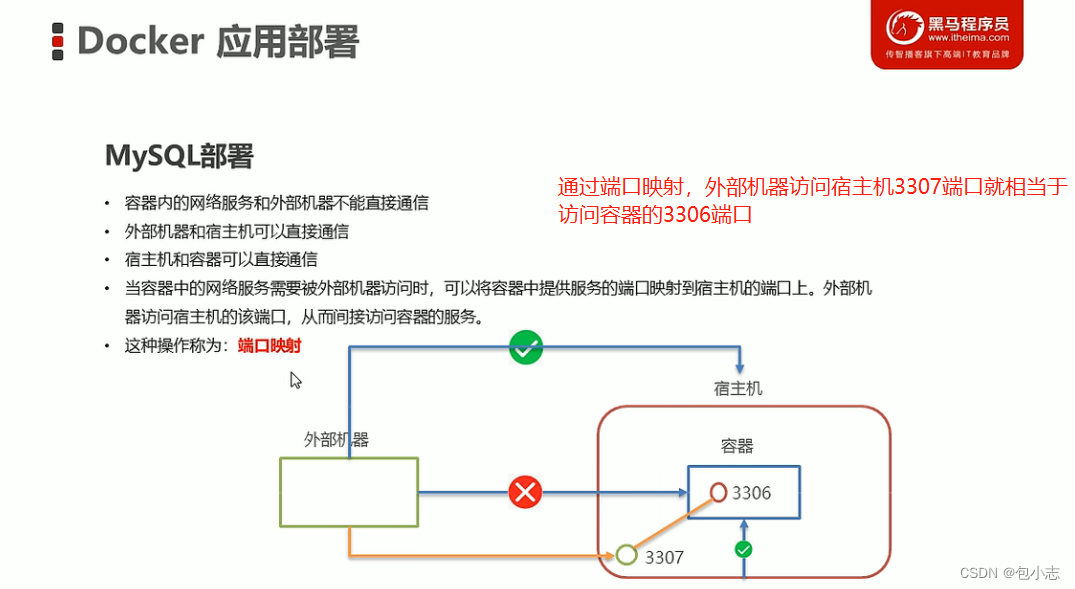
# 摘要
随着容器化技术的广泛应用,Docker已成为管理MySQL数据库的流行方式。本文旨在对Docker环境下MySQL权限问题进行系统的故障诊断概述,阐述了MySQL权限模型的基础理论和在Docker环境下的特殊性。通过理论与实践相结合,提出了诊断权限问题的流程和常见原因分析。本文还详细介绍了如何利用日志文件、配置检查以及命令行工具进行故障定位与修复,并探讨了权限被拒问题的解决策略和预防措施
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )