【Basic】Image Scraping and Downloading: Methods for Handling Image Resources
发布时间: 2024-09-15 11:58:14 阅读量: 22 订阅数: 37 

Website Scraping with Python: Using BeautifulSoup and Scrapy
# **2.1 Principles and Methods of Image Scraping and Downloading: Techniques for Handling Image Resources**
### **2.1.1 HTML Parsing and URL Extraction**
The first step in image scraping is parsing the HTML code of the target website to extract the URLs of the images. An HTML parser can transform the HTML code into a tree-like structure, facilitating the traversal and search for the desired elements.
```python
from bs4 import BeautifulSoup
html = """
<html>
<body>
<img src="image1.jpg" alt="Image 1">
<img src="image2.jpg" alt="Image 2">
</body>
</html>
soup = BeautifulSoup(html, 'html.parser')
# Extracting all image URLs
image_urls = [img['src'] for img in soup.find_all('img')]
```
### **2.1.2 Regular Expressions and XPath**
Besides HTML parsers, regular expressions and XPath are also effective methods for extracting URLs. Regular expressions are a pattern-matching language that can match strings that conform to specific patterns. XPath is an XML path language used for navigating and extracting data from XML documents.
```python
import re
# Using regular expressions to extract URLs
image_urls = re.findall(r'src="(.+?)"', html)
# Using XPath to extract URLs
image_urls = soup.xpath('//img/@src')
```
# **2. Practical Tips for Image Scraping and Downloading**
### **2.1 Principles and Methods of Image Scraping**
#### **2.1.1 HTML Parsing and URL Extraction**
**Principles:**
The initial step in image scraping is to parse the HTML code of a webpage to extract the URLs of images. In HTML, images are typically represented by the `<img>` tag, whose `src` attribute contains the image's URL.
**Methods:**
The BeautifulSoup library in Python makes it easy to parse HTML code. The following code example demonstrates how to extract image URLs:
```python
import requests
from bs4 import BeautifulSoup
url = '***'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Finding all image tags
images = soup.find_all('img')
# Extracting image URLs
image_urls = [image.get('src') for image in images]
```
#### **2.1.2 Regular Expressions and XPath**
**Principles:**
Regular expressions and XPath are two powerful pattern-matching technologies that can also be used to extract image URLs. Regular expressions use patterns to match strings, while XPath uses path expressions to navigate XML documents (HTML code is essentially XML).
**Methods:**
The following code examples demonstrate how to use regular expressions and XPath to extract image URLs:
Using regular expressions:
```python
import re
html = '<html><body><img src="image1.jpg" /><img src="image2.jpg" /></body></html>'
image_urls = re.findall(r'<img.*?src="(.*?)"', html)
```
Using XPath:
```python
from lxml import etree
html = '<html><body><img src="image1.jpg" /><img src="image2.jpg" /></body></html>'
tree = etree.HTML(html)
image_urls = tree.xpath('//img/@src')
```
### **2.2 Protocols and Strategies for Image Downloading**
#### **2.2.1 HTTP/HTTPS Protocols**
**Principles:**
HTTP (Hypertext Transfer Protocol) and HTTPS (HTTP Secure) are protocols used for data transfer over networks. HTTP transmits data in plain text, whereas HTTPS uses encrypted transmission for greater security.
**Strategies:**
When scraping images, prefer the HTTPS protocol to ensure data security. If the target website does not support HTTPS, then use the HTTP protocol.
#### **2.2.2 Proxies and Multithreading**
**Principles:**
A proxy server acts as an intermediary between the client and the server. Using a proxy can conceal the client's real IP address and bypass anti-scraping mechanisms. Multithreading technology can execute multiple tasks simultaneously, increasing scraping efficiency.
**Strategies:**
If the target website has anti-scraping mechanisms, proxies can be used to bypass them. The `proxies` parameter in Python's requests library can be used to specify a proxy server. Multithreading can be implemented using Python's `threading` module.
### **2.3 Common Tools and Libraries for Image Processing**
#### **2.3.1 Python's requests Library**
**Function:**
The requests library is a powerful library in Python for sending HTTP requests. It provides a simple API that makes it easy to retrieve web content and download files.
**Code Example:**
```python
import requests
url = '***'
response = requests.get(url)
image_data = response.content
```
#### **2.3.2 The PIL/Pillow Library**
**Function:**
PIL (Python Imaging Library) and Pillow (a fork of PIL) are powerful libraries in Python for image processing. They provide a range of functions for loading, processing, saving, and displaying images.
**Code Example:**
```python
from PIL import Image
image = Image.open('image.
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实变函数论:大师级解题秘籍】

# 摘要
实变函数论是数学分析的一个重要分支,涉及对实数系函数的深入研究,包括函数的极限、连续性、微分、积分以及更复杂结构的研究。本文概述了实变函数论的基本理论,重点探讨了实变函数的基本概念、度量空间与拓扑空间的性质、以及点集拓扑的基本定理。进一步地,文章深入分析了测度论和积分论的理论框架,讨论了实变函数空间的结构特性,包括L^p空间的性质及其应用。文章还介绍了实变函数论的高级技巧
【Betaflight飞控软件快速入门】:从安装到设置的全攻略

# 摘要
本文对Betaflight飞控软件进行了全面介绍,涵盖了安装、配置、基本功能使用、高级设置和优化以及故障排除与维护的详细步骤和技巧。首先,本文介绍了Betaflight的基本概念及其安装过程,包括获取和安装适合版本的固件,以及如何使用Betaflight Conf
Vue Select选择框高级过滤与动态更新:打造无缝用户体验
# 摘要
本文详细探讨了Vue Select选择框的实现机制与高级功能开发,涵盖了选择框的基础使用、过滤技术、动态更新机制以及与Vue生态系统的集成。通过深入分析过滤逻辑和算法原理、动态更新的理论与实践,以及多选、标签模式的实现,本文为开发者提供了一套完整的Vue Select应用开发指导。文章还讨论了Vue Select在实际应用中的案例,如表单集成、复杂数据处理,并阐述了测试、性能监控和维
揭秘DVE安全机制:中文版数据保护与安全权限配置手册

# 摘要
随着数字化时代的到来,数据价值与安全风险并存,DVE安全机制成为保护数据资产的重要手段。本文首先概述了DVE安全机制的基本原理和数据保护的必要性。其次,深入探讨了数据加密技术及其应用,以
三角矩阵实战案例解析:如何在稀疏矩阵处理中取得优势

# 摘要
稀疏矩阵和三角矩阵是计算机科学与工程领域中处理大规模稀疏数据的重要数据结构。本文首先概述了稀疏矩阵和三角矩阵的基本概念,接着深入探讨了稀疏矩阵的多种存储策略,包括三元组表、十字链表以及压缩存储法,并对各种存储法进行了比较分析。特别强调了三角矩阵在稀疏存储中的优势,讨论了在三角矩阵存储需求简化和存储效率提升上的策略。随后,本文详细介绍了三角矩阵在算法应用中的实践案例,以及在编程实现方
Java中数据结构的应用实例:深度解析与性能优化
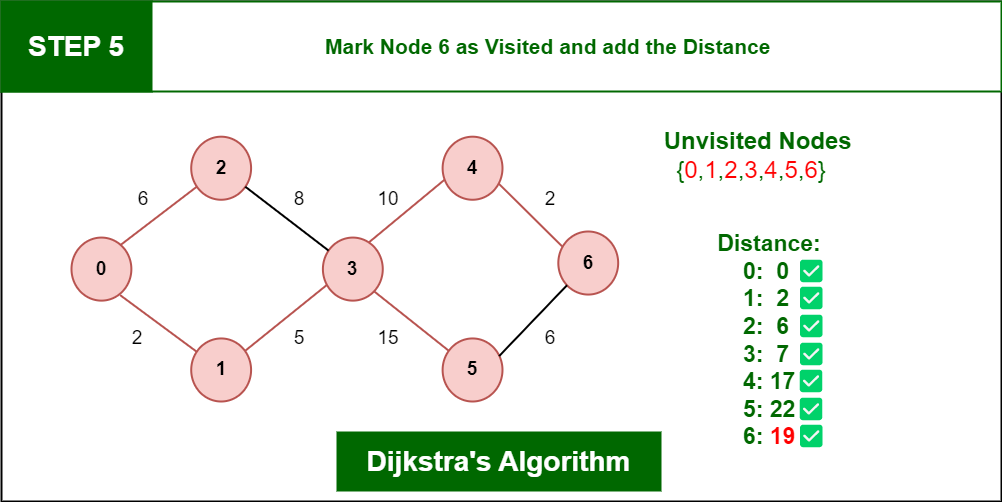
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
【性能提升】:一步到位!施耐德APC GALAXY UPS性能优化技巧

# 摘要
本文旨在深入探讨不间断电源(UPS)系统的性能优化与管理。通过细致分析UPS的基础设置、高级性能调优以及创新的维护技术,强调了在不同应用场景下实现性能优化的重要性。文中不仅提供了具体的设置和监控方法,还涉及了故障排查、性能测试和固件升级等实践案例,以实现对UPS的全面性能优化。此外,文章还探讨了环境因素、先进的维护技术及未来发展趋势,为UPS性能优化提供了全
坐标转换秘籍:从西安80到WGS84的实战攻略与优化技巧
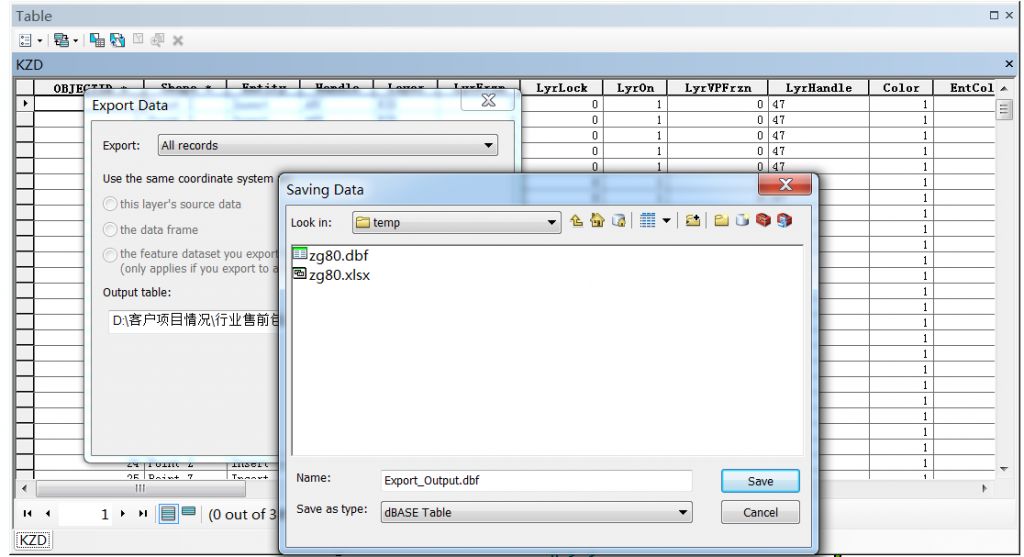
# 摘要
本文全面介绍了坐标转换的相关概念、基础理论、实战攻略和优化技巧,重点分析了从西安80坐标系统到WGS84坐标系统的转换过程。文中首先概述了坐标系统的种类及其重要性,进而详细阐述了坐标转换的数学模型,并探讨了实战中工具选择、数据准备、代码编写、调试验证及性能优化等关键步骤。此外,本文还探讨了提升坐标转换效率的多种优化技巧,包括算法选择、数据处理策略,以及工程实践中的部
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )