【Advanced篇】Design and Implementation of Distributed Crawler Architecture: A Redis-based Distributed Task Queue
发布时间: 2024-09-15 12:34:42 阅读量: 34 订阅数: 37 

java+sql server项目之科帮网计算机配件报价系统源代码.zip
**【Advanced篇】Design and Implementation of Distributed Crawler Architecture: A Redis-based Distributed Task Queue**
Distributed crawlers are a type of crawler technology that utilizes distributed system architecture to improve the efficiency and scalability of crawlers. It distributes crawling tasks to multiple distributed nodes and achieves collaborative work through coordination and communication mechanisms. The distributed crawler architecture has the following advantages:
- **High concurrency:** The distributed architecture can process a large number of requests in parallel, improving the efficiency of the crawler.
- **High scalability:** Nodes can be flexibly added or removed, scaling the crawler according to needs.
- **Fault tolerance:** When a node fails, other nodes can take over its tasks, ensuring the stability of the crawler.
# 2. Design of Distributed Crawler Architecture
The design of the distributed crawler architecture is key to its efficiency and scalability. It involves the collaborative work of multiple components, as well as communication and interaction between these components. This chapter will delve into the components, functions, architectural patterns, and load balancing strategies of distributed crawlers.
### 2.1 Components and Functions of Distributed Crawlers
A typical distributed crawler system consists of the following components:
- **Crawler client:** A program responsible for fetching data from target websites.
- **Scheduler:** Manages crawler clients, allocates fetching tasks, and coordinates the fetching process.
- **URL manager:** Stores and manages the list of URLs to be fetched.
- **Data parser:** Extracts and parses required data from the fetched HTML pages.
- **Storage system:** Stores the fetched data, such as relational databases, NoSQL databases, or distributed file systems.
### 2.2 Architectural Patterns of Distributed Crawlers
The architectural pattern of a distributed crawler determines the organization and interaction between components. There are mainly three architectural patterns:
#### 2.2.1 Master-Worker Pattern
In the Master-Worker pattern, a master node (Master) is responsible for scheduling and managing crawler clients (Worker). The Master allocates fetching tasks to Workers, which execute the tasks and return the results.
**Advantages:**
- Centralized management, easy to control and coordinate.
- Simple load balancing, as the Master is responsible for task allocation.
**Disadvantages:**
- The Master node becomes a single point of failure; its failure can cause the entire system to collapse.
- Limited scalability; the processing capacity of the Master node limits the system's concurrency.
#### 2.2.2 Peer-to-Peer Pattern
In the Peer-to-Peer pattern, all crawler clients are peers, with no centralized control node. Each client is responsible for its own fetching tasks and shares the fetched data with other clients.
**Advantages:**
- High availability; there is no single point of failure.
- Good scalability; clients can be easily added or removed.
**Disadvantages:**
- Complex coordination; a distributed consistency algorithm needs to be implemented.
- Load balancing is difficult; an additional mechanism is required to ensure even task distribution.
#### 2.2.3 Hybrid Pattern
The Hybrid pattern combines the advantages of the Master-Worker pattern and the Peer-to-Peer pattern. It has a centralized scheduler (Master) responsible for task allocation and coordinating the fetching process. At the same time, crawler clients (Workers) can communicate and share data with each other.
**Advantages:**
- Balances centralized management and distributed scalability.
- Good fault tolerance; a new Master can be automatically elected if the Master fails.
**Disadvantages:**
- High implementation complexity; both centralized and distributed characteristics need to be considered.
### 2.3 Load Balancing Strategies of Distributed Crawlers
Load balancing strategies deter***mon load balancing strategies include:
#### 2.3.1 Round-Robin Strategy
The round-robin strategy is the simplest load balancing strategy, which sequentially allocates tasks to crawler clients.
**Advantages:**
- Simple implementation, easy to understand.
- Ensures a fair allocation for all clients.
**Disadvantages:**
- Does not consider the load of clients, which may lead to some clients being overloaded while others are idle.
#### 2.3.2 Hashing Strategy
The hashing strategy alloca

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SGP.22_v2.0(RSP)中文版深度剖析】:掌握核心特性,引领技术革新
# 摘要
SGP.22_v2.0(RSP)作为一种先进的技术标准,在本论文中得到了全面的探讨和解析。第一章概述了SGP.22_v2.0(RSP)的核心特性,为读者提供了对其功能与应用范围的基本理解。第二章深入分析了其技术架构,包括设计理念、关键组件功能以及核心功能模块的拆解,还着重介绍了创新技术的要点和面临的难点及解决方案。第三章通过案例分析和成功案例分享,展示了SGP.22_v2.0(RSP)在实际场景中的应用效果、
小红书企业号认证与内容营销:如何创造互动与共鸣
# 摘要
本文详细解析了小红书企业号的认证流程、内容营销理论、高效互动策略的制定与实施、小红书平台特性与内容布局、案例研究与实战技巧,并展望了未来趋势与企业号的持续发展。文章深入探讨了内容营销的重要性、目标受众分析、内容创作与互动策略,以及如何有效利用小红书平台特性进行内容分发和布局。此外,通过案例分析和实战技巧的讨论,本文提供了一系列实战操作方案,助力企业号管理者优化运营效果,增强用户粘性和品牌影响力
【数字电路设计】:优化PRBS生成器性能的4大策略
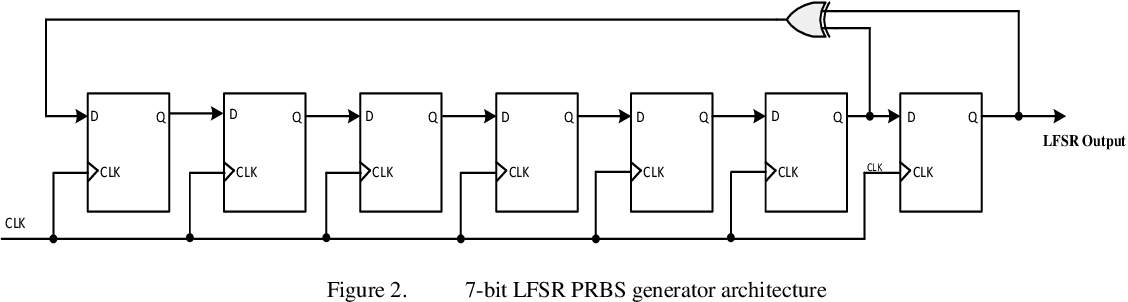
# 摘要
本文全面介绍了数字电路设计中的PRBS生成器原理、性能优化策略以及实际应用案例分析。首先阐述了PRBS生成器的工作原理和关键参数,重点分析了序列长度、反馈多项式、时钟频率等对生成器性能的影响。接着探讨了硬件选择、电路布局、编程算法和时序同步等多种优化方法,并通过实验环境搭建和案例分析,评估了这些策
【从零到专家】:一步步精通图书馆管理系统的UML图绘制

# 摘要
统一建模语言(UML)是软件工程领域广泛使用的建模工具,用于软件系统的设计、分析和文档化。本文旨在系统性地介绍UML图绘制的基础知识和高级应用。通过概述UML图的种类及其用途,文章阐明了UML的核心概念,包括元素与关系、可视化规则与建模。文章进一步深入探讨了用例图、类图和序列图的绘制技巧和在图书馆管理系统中的具体实例。最后,文章涉及活动图、状态图的绘制方法,以及组件图和
【深入理解Vue打印插件】:专家级别的应用和实践技巧
# 摘要
本文深入探讨了Vue打印插件的基础知识、工作原理、应用配置、优化方法、实践技巧以及高级定制开发,旨在为Vue开发者提供全面的打印解决方案。通过解析Vue打印插件内部的工作原理,包括指令和组件解析、打印流程控制机制以及插件架构和API设计,本文揭示了插件在项目
【Origin图表深度解析】:隐藏_显示坐标轴标题与图例的5大秘诀

# 摘要
本文旨在探讨Origin图表中坐标轴标题和图例的设置、隐藏与显示技巧及其重要性。通过分析坐标轴标题和图例的基本功能,本文阐述了它们在提升图表可读性和信息传达规范化中的作用。文章进一步介绍了隐藏与显示坐标轴标题和图例的需求及其实践方法,包括手动操作和编程自动化技术,强调了灵活控制这些元素对于创建清晰、直观图表的重要性。最后,本文展示了如何自定义图表以满足高级需求,并通过
【GC4663与物联网:构建高效IoT解决方案】:探索GC4663在IoT项目中的应用
# 摘要
GC4663作为一款专为物联网设计的芯片,其在物联网系统中的应用与理论基础是本文探讨的重点。首先,本文对物联网的概念、架构及其数据处理与传输机制进行了概述。随后,详细介绍了GC4663的技术规格,以及其在智能设备中的应用和物联网通信与安全机制。通过案例分析,本文探讨了GC4663在智能家居、工业物联网及城市基础设施中的实际应用,并分
Linux系统必备知识:wget命令的深入解析与应用技巧,打造高效下载与管理

# 摘要
本文旨在深入介绍Linux系统中广泛使用的wget命令的基础知识、高级使用技巧、实践应用、进阶技巧与脚本编写,以及在不同场景下的应用案例分析。通过探讨wget命令的下载控制、文件检索、网络安全、代理设置、定时任务、分段下载、远程文件管理等高级功能,文章展示了wget
EPLAN Fluid故障排除秘籍:快速诊断与解决,保证项目顺畅运行
# 摘要
EPLAN Fluid作为一种工程设计软件,广泛应用于流程控制系统的规划和实施。本文旨在提供EPLAN Fluid的基础介绍、常见问题的解决方案、实践案例分析,以及高级故障排除技巧。通过系统性地探讨故障类型、诊断步骤、快速解决策略、项目管理协作以及未来发展趋势,本文帮助读者深入理解EPLAN Fluid的应用,并提升在实际项目中的故障处理能力。
华为SUN2000-(33KTL, 40KTL) MODBUS接口故障排除技巧

# 摘要
本文旨在全面介绍MODBUS协议及其在华为SUN2000逆变器中的应用。首先,概述了MODBUS协议的起源、架构和特点,并详细介绍了其功能码和数据模型。随后,对华为SUN2000逆变器的工作原理、通信接口及与MODBUS接口相关的设置进行了讲解。文章还专门讨论了MODBUS接口故障诊断的方法和工具,以及如
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )