岭南师范学院大数据核心技术期末试题详解
41 浏览量
更新于2024-08-03
收藏 132KB DOC 举报
本资源是一份岭南师范学院2015-2016学年度第二学期期末考试试题A卷,主要涉及大数据核心技术的相关内容。试卷包含三个部分:单项选择题、判断题和简答题。
1. 大数据技术的特点:
- Volume(大体量):大数据的数据量非常庞大,可以从数百TB到PB或EB级别,强调数据的海量性。
- Variety(多样性):数据来源广泛,包括多种格式和形态,如结构化、半结构化和非结构化数据。
- Velocity(时效性):对实时性和响应速度有高要求,数据需要在短时间内进行处理和分析。
- Veracity(准确性):处理大数据时,数据的准确性和完整性至关重要,需要确保结果可靠性。
- Value(大价值):大数据蕴含着巨大的商业价值,通过分析挖掘可以发现新的业务洞察和竞争优势。
2. Hadoop集群启动顺序:
- 启动Hadoop时,按照`namenode` -> `datanode` -> `secondarynamenode` -> `resourcemanager` -> `nodemanager`的顺序进行。
3. HBase技术特点:
- 列式存储:以列的形式存储数据,适合大量读取操作。
- 稀疏多维映射表:表结构灵活,适合非稠密数据。
- 一致性:提供严格的读写一致性,保证数据的一致性。
- 高速性能:设计用于高效的数据读写。
- 扩展性:线性扩展,随着硬件增加而性能提升。
- 海量数据支持:处理大规模数据集。
- 数据分片:自动进行数据分布,提高容错性。
- 故障恢复:具备自我检测和恢复机制。
- 集成性:与HDFS和MapReduce等其他Hadoop组件紧密集成。
4. Hive数据仓库中的查询:
- 创建了一个外部表`sogou_ext`,包含多个字段,如时间戳、用户ID、关键词等。查询语句展示了如何计数独立的用户ID,即`SELECT count(DISTINCT uid) FROM sogou_ext;`。
这份试题涵盖了大数据基础概念、Hadoop生态系统以及Hive查询语言的基础应用,旨在测试学生对大数据核心技术的理解和实践能力。通过解答这些问题,考生将能够展示他们对大数据处理流程、数据存储模式、数据处理工具和数据仓库管理的掌握程度。
第 1 页,共 16 页 第 2 页,共 16 页
任课教师签名: 命题教师签名: 系主任签名: 主管院长签名:
… … … … ○ … … … … ○ … … … … 内 … … … … ○ … … … … 装 … … … … ○ … … … … 订 … … … … ○ … … … … 线 … … … … ○ … … … …
_ __学院 专业 级 班 姓名 学号
岭南师范学院 2015 年- 2016 学年度第二学期
期末考试试题 A 卷
(考试时间: 120 分钟)
考试科目: 大数据核心技术
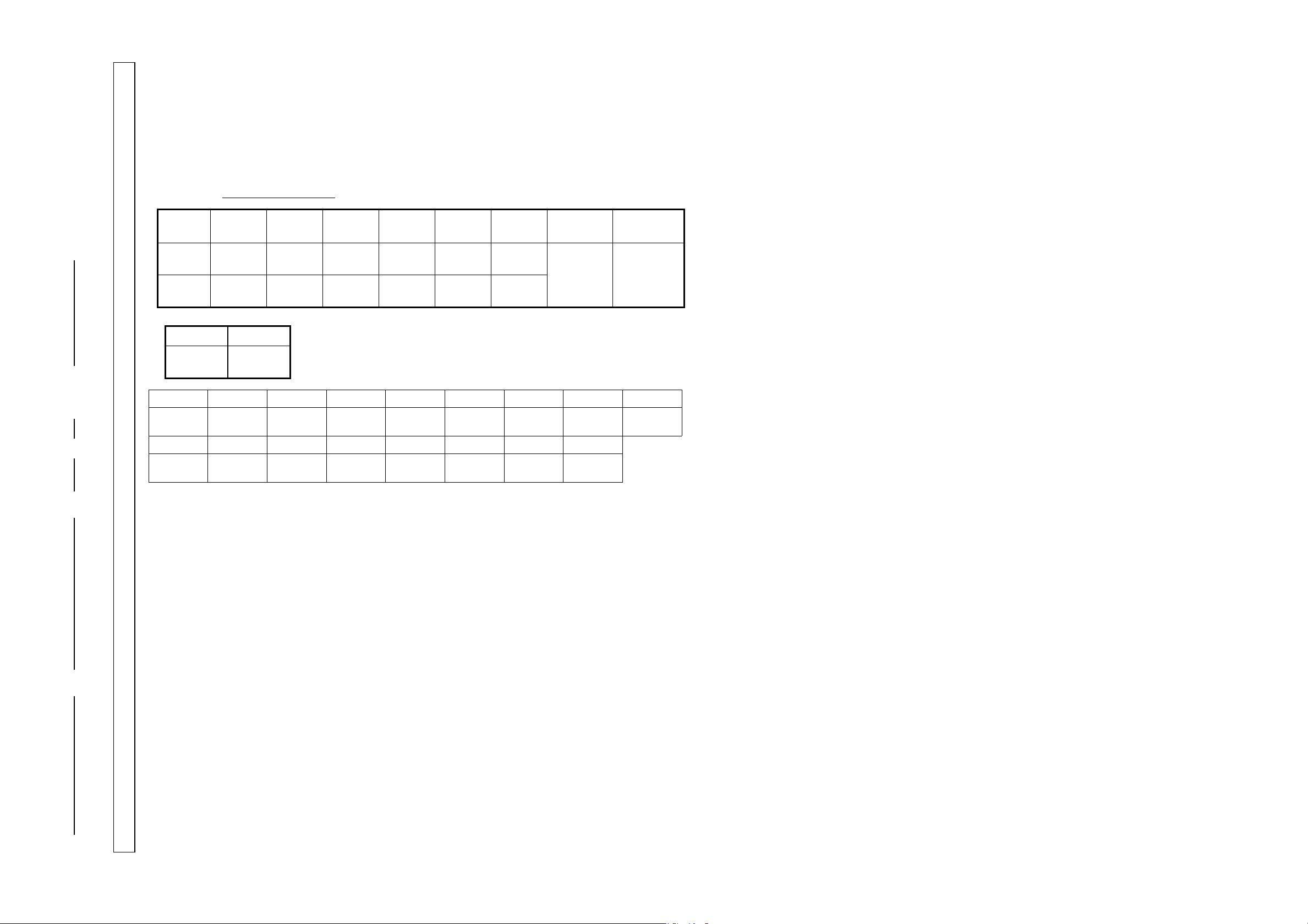
题 号
一
二
三
四
五
总 分
总评分人
复查人
分 值
30
16
20
24
10
得 分
一、单项选择题(每小题 2 分,共 30 分)
请把答案写在下表中,写在试题后无效。
1. 下面哪个程序负责 HDFS 数据存储。 (C )
A. NameNode B. Jobtracker
C. Datanode D. secondaryNameNode
2. HDFS 中的 block 默认保存几个备份。 ( A )
A. 3 份 B. 2 份
C. 1 份 D. 不确定
3. HDFS1.0 默认 Block Size 大小是多少。 ( B )
A. 32MB B. 64MB
C. 128MB D. 256MB
4. 下面哪个进程负责 MapReduce 任务调度。 ( B )
A. NameNode B. Jobtracker
C. TaskTracker D. secondaryNameNode
5. Hadoop1.0 默认的调度器策略是哪个。 ( A )
A. 先进先出调度器 B. 计算能力调度器
C. 公平调度器 D. 优先级调度器
6. Client 端上传文件的时候下列哪项正确? ( B )
A. 数据经过 NameNode 传递给 DataNode
B. Client 端将文件切分为 Block,依次上传
C. Client 只上传数据到一台 DataNode,然后由 NameNode 负责 Block 复制工作
D. 以上都不正确
7. 在实验集群的 master 节点使用 jps 命令查看进程时,终端出现以下哪项能说明 Hadoop
主节点启动成功? ( D )
A. Namenode, Datanode, TaskTracker
B. Namenode, Datanode, secondaryNameNode
C. Namenode, Datanode, HMaster
D. Namenode, JobTracker, secondaryNameNode
8. 若不针对 MapReduce 编 程 模 型 中 的 key 和 value 值进行特别设置,下列哪一项是
MapReduce 不适宜的运算。 ( D )
A. Max B. Min
C. Count D. Average
得分
评卷人
题号
1
2
3
4
5
6
7
8
答案
题号
9
10
11
12
13
14
15
答案
下载后可阅读完整内容,剩余7页未读,立即下载
2024-04-25 上传
2022-11-13 上传
2022-11-24 上传
2022-11-12 上传
2022-11-13 上传
2024-05-16 上传
2022-11-12 上传
2022-11-13 上传
2022-11-12 上传

平头哥在等你
- 粉丝: 1272
- 资源: 7530
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
