基于语音识别的跨领域多音种TTS系统研究
需积分: 0 44 浏览量
更新于2024-07-09
收藏 1MB PDF 举报
本文档《Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis》聚焦于深度学习在语音合成领域的创新应用,特别是在多说话人文本转语音(TTS)系统中的迁移学习。作者团队提出了一种基于神经网络的系统,该系统能够生成不同说话人的语音音频,包括那些在训练过程中未曾见过的说话人的声音。
首先,系统的关键组成部分是 speaker encoder。这个模块经过专门训练,用于语音识别任务,使用一个独立的噪声语音数据集,其中包含数千名未标记的演讲者。它仅依赖于目标说话人的几秒钟参考语音,就能生成固定维度的嵌入向量。这个过程利用了迁移学习的概念,将已学到的通用语音特征迁移到新的语音合成任务上。
接下来是 sequence-to-sequence synthesis network,基于Tacotron 2架构。它负责将文本转换成梅尔频谱图,而这个过程会受到来自 speaker encoder 的嵌入向量的条件约束。这样,生成的语音能准确地反映指定说话人的特性,增强了合成语音的自然度和个性化。
最后,系统使用 auto-regressive WaveNet-based vocoder,它将梅尔频谱图进一步转化为时间域的波形样本。这种技术通过自回归方式生成连续的语音信号,确保了生成的音频质量。
整个系统的设计旨在通过预训练的 speaker encoder 提供有效的特征表示,然后结合Tacotron 2和WaveNet的先进生成能力,实现了跨说话人的多语种TTS。实验结果证明,这种方法成功地实现了知识的迁移,使得模型能够在无需额外大量标注数据的情况下,生成具有多种独特嗓音的高质量语音合成。
这篇论文不仅关注技术实现,还探讨了迁移学习在TTS中的潜力和局限性,以及如何通过巧妙设计来提高合成语音的多样性和适应性。对于深度学习和语音合成研究者来说,这篇论文提供了有价值的研究视角和实践案例。
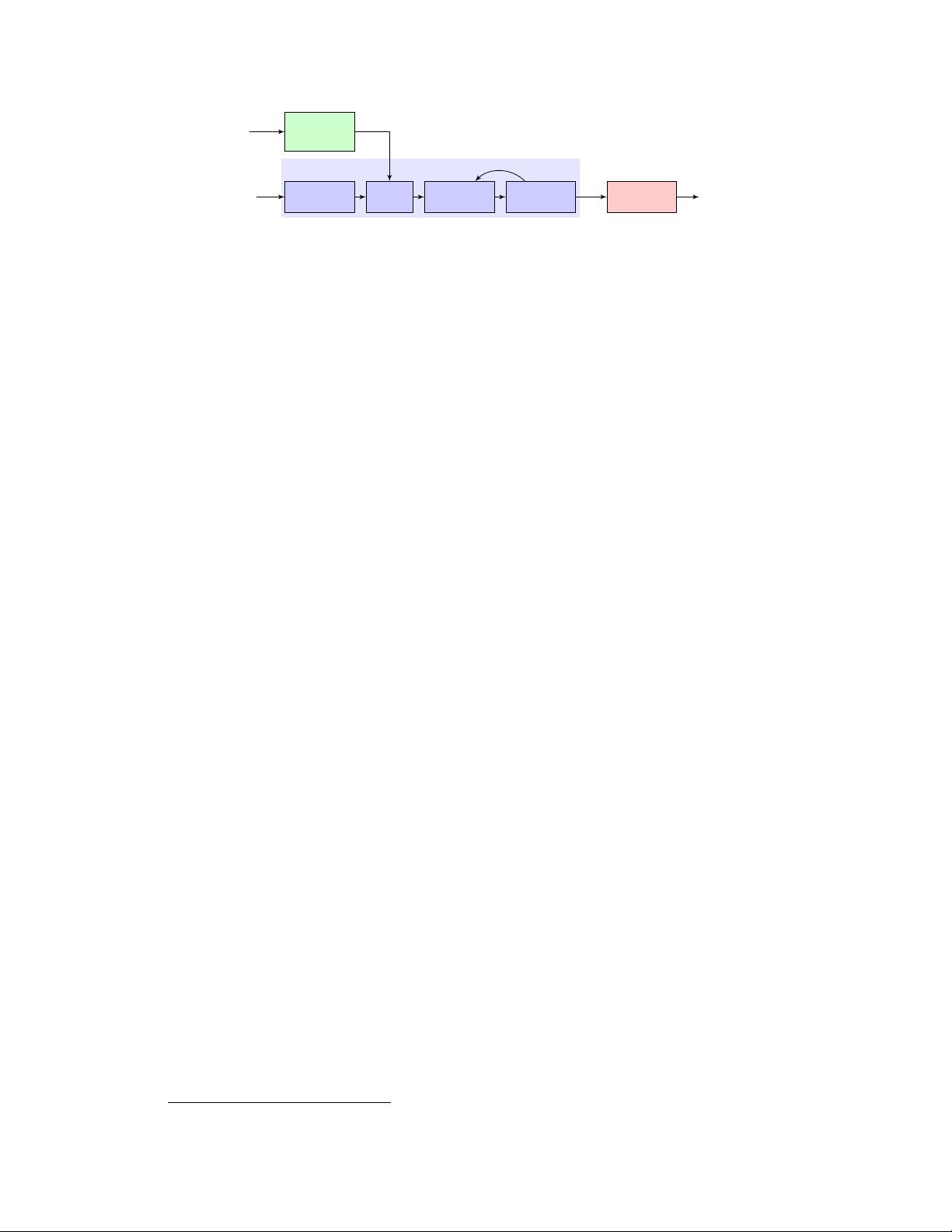
speaker
reference
waveform
Speaker
Encoder
grapheme or
phoneme
sequence
Encoder
concat
Attention Decoder
Synthesizer
Vocoder
waveform
speaker
embedding
log-mel
spectrogram
Figure 1: Model overview. Each of the three components are trained independently.
signal, (2) a sequence-to-sequence synthesizer, based on [
15
], which predicts a mel spectrogram from
a sequence of grapheme or phoneme inputs, conditioned on the speaker embedding vector, and (3) an
autoregressive WaveNet [
19
] vocoder, which converts the spectrogram into time domain waveforms.
1
2.1 Speaker encoder
The speaker encoder is used to condition the synthesis network on a reference speech signal from the
desired target speaker. Critical to good generalization is the use of a representation which captures the
characteristics of different speakers, and the ability to identify these characteristics using only a short
adaptation signal, independent of its phonetic content and background noise. These requirements are
satisfied using a speaker-discriminative model trained on a text-independent speaker verification task.
We follow [
22
], which proposed a highly scalable and accurate neural network framework for speaker
verification. The network maps a sequence of log-mel spectrogram frames computed from a speech
utterance of arbitrary length, to a fixed-dimensional embedding vector, known as d-vector [
20
,
9
]. The
network is trained to optimize a generalized end-to-end speaker verification loss, so that embeddings
of utterances from the same speaker have high cosine similarity, while those of utterances from
different speakers are far apart in the embedding space. The training dataset consists of speech audio
examples segmented into 1.6 seconds and associated speaker identity labels; no transcripts are used.
Input 40-channel log-mel spectrograms are passed to a network consisting of a stack of 3 LSTM
layers of 768 cells, each followed by a projection to 256 dimensions. The final embedding is created
by
L
2
-normalizing the output of the top layer at the final frame. During inference, an arbitrary length
utterance is broken into 800ms windows, overlapped by 50%. The network is run independently on
each window, and the outputs are averaged and normalized to create the final utterance embedding.
Although the network is not optimized directly to learn a representation which captures speaker
characteristics relevant to synthesis, we find that training on a speaker discrimination task leads to an
embedding which is directly suitable for conditioning the synthesis network on speaker identity.
2.2 Synthesizer
We extend the recurrent sequence-to-sequence with attention Tacotron 2 architecture [
15
] to support
multiple speakers following a scheme similar to [
8
]. An embedding vector for the target speaker is
concatenated with the synthesizer encoder output at each time step. In contrast to [
8
], we find that
simply passing embeddings to the attention layer, as in Figure 1, converges across different speakers.
We compare two variants of this model, one which computes the embedding using the speaker
encoder, and a baseline which optimizes a fixed embedding for each speaker in the training set,
essentially learning a lookup table of speaker embeddings similar to [8, 13].
The synthesizer is trained on pairs of text transcript and target audio. At the input, we map the text to
a sequence of phonemes, which leads to faster convergence and improved pronunciation of rare words
and proper nouns. The network is trained in a transfer learning configuration, using a pretrained
speaker encoder (whose parameters are frozen) to extract a speaker embedding from the target audio,
i.e. the speaker reference signal is the same as the target speech during training. No explicit speaker
identifier labels are used during training.
Target spectrogram features are computed from 50ms windows computed with a 12.5ms step, passed
through an 80-channel mel-scale filterbank followed by log dynamic range compression. We extend
[
15
] by augmenting the
L
2
loss on the predicted spectrogram with an additional
L
1
loss. In practice,
1
See https://google.github.io/tacotron/publications/speaker_adaptation for samples.
3
剩余14页未读,继续阅读
2020-11-05 上传
2023-04-21 上传
2021-12-20 上传
2021-09-30 上传
2021-08-24 上传
2021-10-19 上传
2023-10-31 上传
2023-10-26 上传









