阿里云梯:构建基于Hadoop的集团级海量数据服务平台
"基于Hadoop的海量数据平台用于构建阿里集团内部的大数据处理和服务体系,由高级技术专家吴威负责的阿里云梯项目是其中的关键部分。该平台旨在解决数据的存储、计算以及多子公司间的数据共享问题。通过提供Hadoop as a Service,实现了HDFS的海量数据存储和MapReduce的分布式计算服务,同时引入了其他相关服务如Hive、Pig和HBase等。"
在大数据领域,Hadoop作为开源的分布式计算框架,对于处理海量数据具有显著优势。阿里集团在发展过程中,经历了从单机到分布式数据库再到分散的Hadoop集群的演变。随着数据量的爆炸式增长,传统的数据库解决方案无法满足需求,因此转向了Hadoop,利用其强大的扩展性和容错性来应对不断膨胀的数据规模。
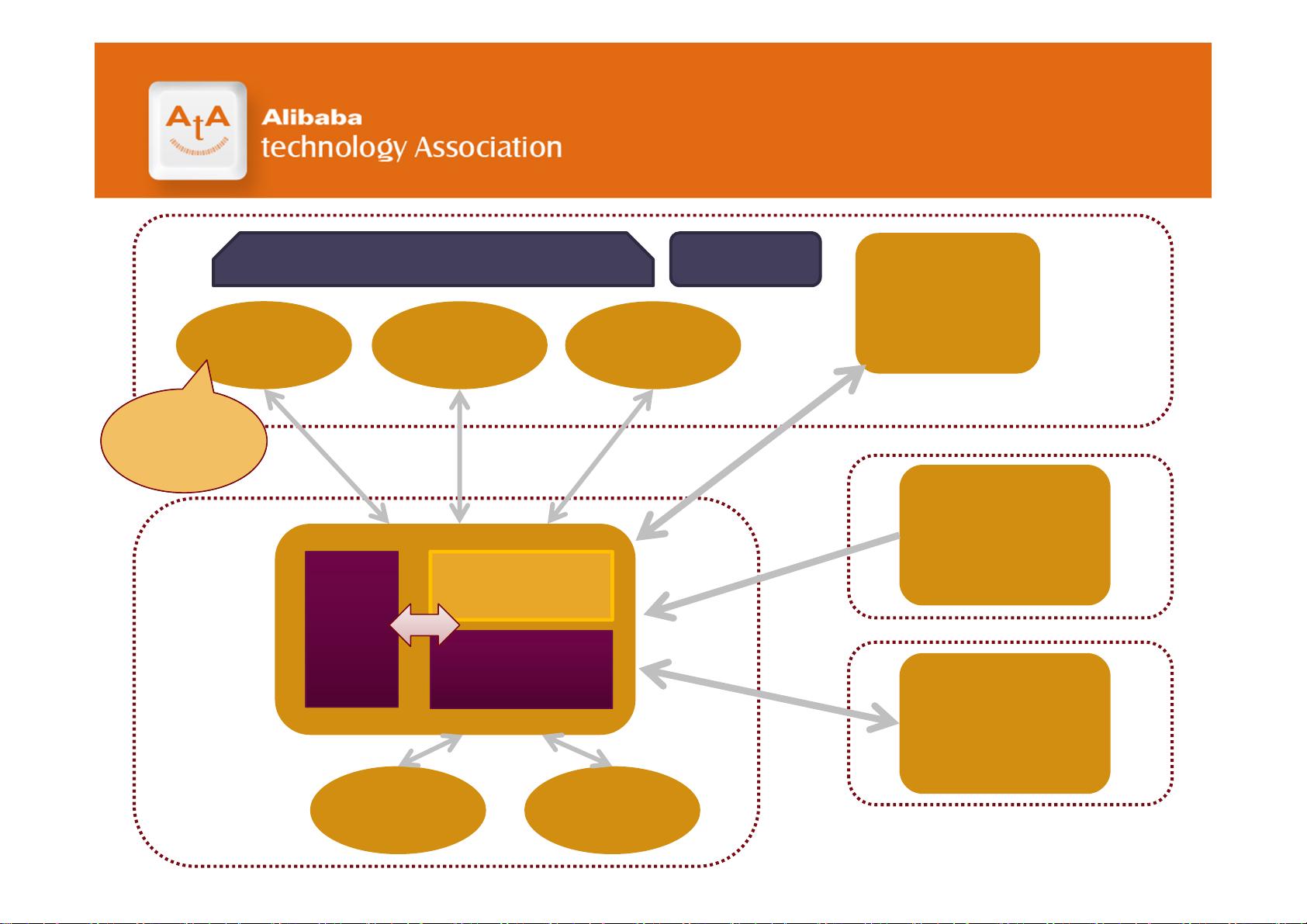
"云梯"项目是阿里集团对Hadoop集群进行整合与优化的成果,它将多个Hadoop集群合并,实现了一个统一的大集群,提供跨子公司的数据共享服务。通过HDFS,数据被分组并设置quota进行管理,确保各业务部门间的公平使用。同时,MapReduce服务则提供了计算资源的分时调度,白天用于开发,晚上进行生产计算,提高了集群资源利用率。
Hadoop as a Service (HaaS) 提供了类似云服务的体验,允许不同团队按需申请计算资源,并根据实际使用量计费。这一服务还包括了基于MapReduce的SQL引擎(如Hive),使得非程序员也能通过SQL对大数据进行分析。此外,Pig提供了一种更高级别的抽象,简化了数据分析任务,而HBase则提供了在线和离线的存储服务,满足实时查询的需求。
在架构上,云梯集群通过网关连接不同的业务系统,如淘宝、天猫、一淘、B2B和支付宝,保证了数据的高效流动和处理。业务调度系统协调整个集团的数据处理流程,确保服务的稳定性和响应速度。
总结来说,"基于Hadoop的海量数据平台"展示了如何在企业级环境中有效地管理和利用大数据。通过集中的Hadoop服务,阿里集团不仅解决了数据存储和计算的挑战,还促进了跨部门的数据协作,推动了其数据驱动的战略实施。这种模式对于其他寻求大数据解决方案的企业具有重要的参考价值。
其他相关服务
基于MapReduce 的SQL引擎
Hive
可以用任意可执行程序或脚本运行MapReduce
Streaming
机器学习算法库
Mahout
类似于Hive的大规模数据分析平台
Pig
离线和在线存储服务
HBase
剩余47页未读,继续阅读
2018-07-02 上传
2021-07-21 上传
2013-01-10 上传
2023-11-07 上传
2024-05-16 上传
2021-08-15 上传
2023-06-18 上传
2012-11-03 上传

CHJISH2013
- 粉丝: 0
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- 行业分类-设备装置-航天遥感大相对孔径宽视场高分辨率成像光谱仪光学系统.zip
- AppLock:对于trainimg,我可以自定义视图功能
- 华为简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- zenodo:将数据(或任何研究对象)存入 Zenodo
- osc-delft.github.io:代尔夫特开放科学社区的在线主页
- 形状理论
- MM32SPIN0x(n) 库函数和例程.rar
- asp源码-CITMS公司客户信息与追踪管理系统 v3.0.zip
- BeautyForestAgent4
- jwt:适用于PHP的JWT(JSON网络令牌)库
- C ++中的Vista Goodies:在UI中使用Glass
- jcr-criteria:使用Java代码的JCR查询
- Notes_DataStructure_and_Algorithms:数据结构和算法的注释
- LCD液晶显示屏(介绍及程序GOOD).zip
- PjSIP:该项目构建了一个提供 sip 连接功能的 iOS 静态库。 它公开了 DXIPJSipManager 类,该类可用于将 iOS 应用程序连接到 sip 服务器
- asp源码-CFUpdate asp 批量上传客户端组件 for ASP v1.22.zip
