Hive优化技巧:调整Map和Reduce数量及小文件合并
需积分: 9 64 浏览量
更新于2024-07-19
收藏 1.5MB DOCX 举报
“Hive调优策略,包括大小表Join优化、小文件调优以及实现原理,特别是关于map和reduce任务数量的设定。”
在Hive数据仓库的调优中,优化map和reduce任务的数量是一个关键环节,它直接影响着查询性能和资源利用率。下面将详细讨论这些策略。
1. 控制Hive任务中的map数:
- Map任务的数量由输入数据的文件数和文件大小决定。默认情况下,Hadoop会按照文件块大小(通常是128MB)来分割文件,每个文件块对应一个map任务。例如,一个780MB的文件会被分成7个块,产生7个map任务;而3个分别大小为10MB、20MB和130MB的文件会被拆分为4个块,产生4个map任务。
- 并非map任务越多越好。过多的小文件会导致大量map任务的创建,而启动和初始化map任务所需的时间远大于实际处理数据的时间,这会造成资源浪费。此外,系统同时可执行的map任务数量有限。
- 优化策略:为了减少map数,可以使用Hive的CombineHiveInputFormat或CombineFileInputFormat来合并小文件,将它们聚合成更大的文件块,从而减少map任务数量。例如,通过在Hive查询前使用`set mapred.input.format.class=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;`来启用此功能。
2. 控制Hive任务中的reduce数:
- Reduce任务的数量可以通过设置`hive.exec.reducers.bytes.per.reducer`参数来控制,该参数定义了每个reduce任务处理的数据量,默认值为100MB。如果需要调整,可以使用`set hive.exec.reducers.bytes.per.reducer=XXX;`命令。
- 大小表Join优化:在进行大小表Join操作时,如果小表可以完全装入内存,可以使用Map-side Join,这样可以避免生成大量中间结果,从而减轻reduce阶段的压力。使用`set hive.auto.convert.join=true;`可以开启自动转换Map-side Join的特性,但要注意内存限制。
3. 小文件调优:
- 小文件问题不仅影响map数,还会导致数据倾斜。可以使用Hive的`sortby`和`distribute by`语句来均匀分布数据,避免某些reduce任务负载过重。
- 另外,可以使用Hadoop的`-getmerge`或`-get`命令在客户端合并小文件,或者在MapReduce作业中使用`-Dmapred.max.split.size`参数指定较大的split大小,使得小文件在上传至HDFS时就被合并。
4. 实现原理:
- Hive优化主要基于Hadoop MapReduce框架,通过调整输入输出格式、分区策略、数据倾斜处理、缓存机制等多方面进行。
- Hive还提供了其他优化选项,如开启数据压缩(`set hive.exec.compress.output=true;`)、优化查询计划(`set hive.optimize.ppd=true;`)和启用统计信息(`ANALYZE TABLE table COMPUTE STATISTICS FOR COLUMNS;`)等。
Hive调优是一个涉及多个层面的过程,需要根据具体业务场景和数据特征来综合考虑并调整。通过合理控制map和reduce任务的数量、优化Join操作、处理小文件问题,以及利用Hive的各种优化选项,可以显著提升Hive查询的效率和性能。
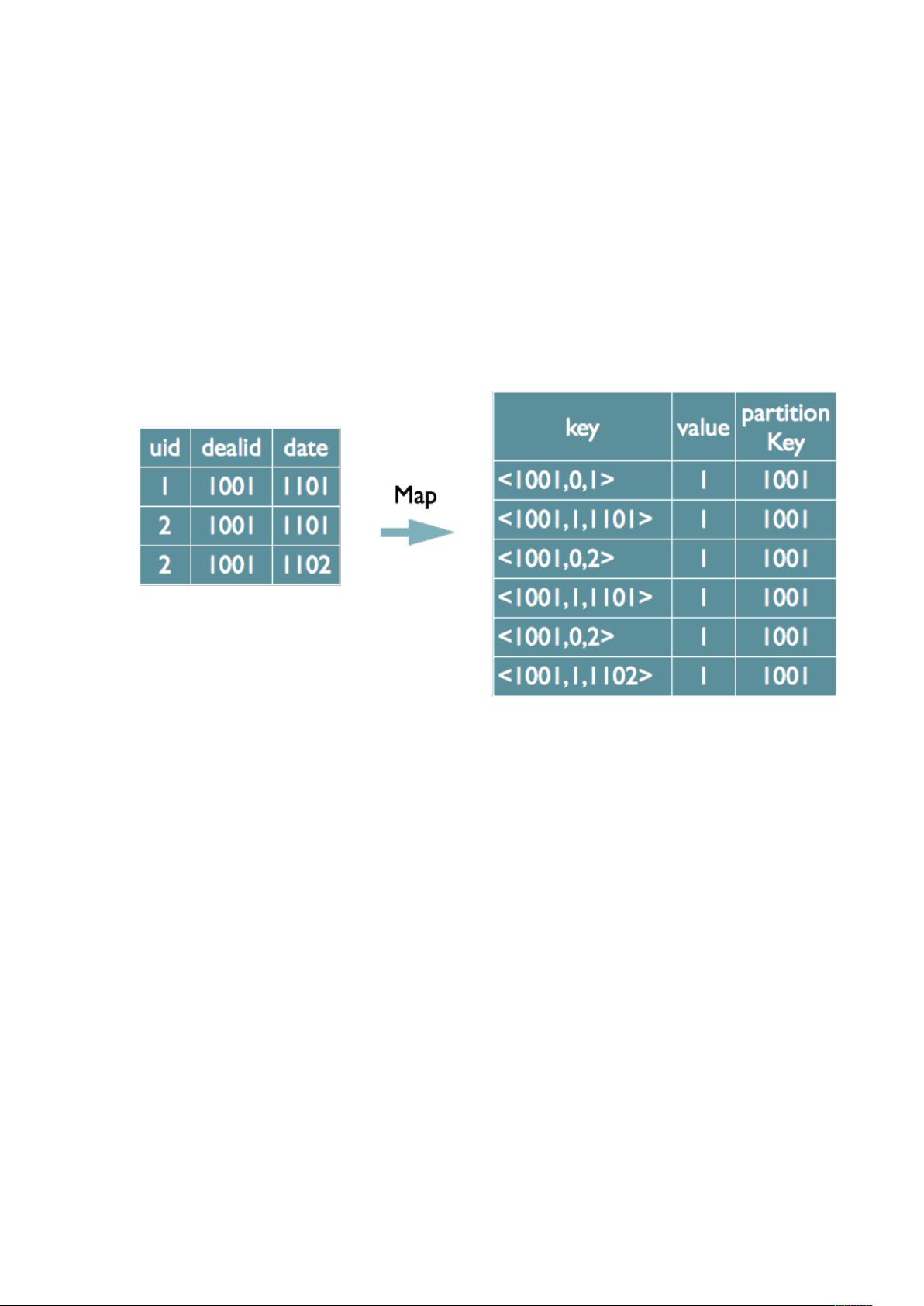
(.)第二种实现方式,可以对所有的 字段编号,每行数据生成 行数据,那么
相同字段就会分别排序,这时只需要在 阶段记录 *) 即可去重。
这种实现方式很好的利用了 的排序,节省了 阶段去重的内存消耗,
但是缺点是增加了 +/ 的数据量。
需要注意的是,在生成 时,除第一个 字段所在行需要保留
值,其余 数据行 字段均可为空。
SQL 转化为 MapReduce 的过程
了解了 实现 基本操作之后,我们来看看 是如何将 转化为
任务的,整个编译过程分为六个阶段:
- 0 定义 的语法规则,完成 词法,语法解析,将 转化为抽象语法
树 0
. 遍历 0,抽象出查询的基本组成单元 )%
1 遍历 )%,翻译为执行操作树 2
3 逻辑层优化器进行 2 变换,合并不必要的 %2,
减少 +/ 数据量
4 遍历 2,翻译为 任务
5 物理层优化器进行 任务的变换,生成最终的执行计划
下面分别对这六个阶段进行介绍
剩余34页未读,继续阅读
280 浏览量
143 浏览量
172 浏览量
1461 浏览量
103 浏览量
点击了解资源详情
338 浏览量
143 浏览量
152 浏览量

江湖鬼谷子
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 水箱液位控制中的PID算法,详细介绍各系数的影响(LabVIEW开发环境)
- 建立系列化大学信息用户教育课程体系——现代信息技术发展之必然
- DWG_Smart-Card_CCID_Rev110
- java学习笔记(初学者)
- java+struts+hibernate+spring基础面试题
- 写给想当程序员的朋友
- 微处理器原理(北京大学课程ppt)
- ArcGIS Server 开发 PPT
- underlinux
- VHDL语言教程4M左右
- h.264 英文标准
- java基础j2se入门PPT
- java基础j2se入门PPT
- 电路设计基础知识.pdf
- C的菜单设计、图形绘制、动画的播放、乐曲等高级编程技术
- ARM体系结构和编程方法.pdf
