理解布隆过滤器:工作原理与实例分析
51 浏览量
更新于2024-08-29
收藏 177KB PDF 举报
"本文主要介绍了布隆过滤器的工作原理及其应用实例,强调了其高效性和空间节省,同时指出其返回结果的概率性质可能导致误判。文章通过一个具体的例子展示了布隆过滤器如何运作,并讨论了如何选择合适的参数以降低误判率。"
布隆过滤器是一种在大数据处理和缓存系统中广泛应用的概率型数据结构,它主要用于判断一个元素是否可能存在于一个大规模集合中。由于其占用空间小、插入和查询速度快,特别适用于内存有限或需要快速响应的场景。然而,布隆过滤器的主要缺点是存在一定的误判率,可能会将不存在的元素误判为存在。
布隆过滤器的核心在于一个固定长度的二进制数组和一组独立的哈希函数。初始时,数组中的所有位都是0。当需要添加一个元素时,会用这组哈希函数将元素映射到数组的不同位置,将这些位置设为1。不同的哈希函数保证了元素可以均匀地分布在整个数组中。查询一个元素是否存在时,同样用这组哈希函数计算出数组中的位置,如果所有对应位置都是1,那么可能该元素存在(但不绝对)。如果存在0,则肯定不存在该元素。
误判主要源于两个原因:一是哈希函数的碰撞,即不同的元素可能映射到同一位置;二是有限的数组空间,随着插入元素的增多,未被插入的0逐渐减少,导致误判率上升。为了优化误判率,我们需要合理选择二进制数组的大小(m)和哈希函数的数量(k)。通常,m的选择与需要存储的元素数量(n)和期望的误判率(p)有关,可以通过理论公式进行计算。k的选择则影响着每个元素平均修改的位数,也影响误判率。
举例来说,如果需要存储100亿个元素,希望误判率为0.01%,那么根据理论公式计算,大约需要2000亿个bit的空间(约25GB)和14个哈希函数。实际应用中,我们还需要考虑计算这些哈希函数和操作数组的时间复杂度,以及如何设计这些哈希函数以尽可能减少冲突。
在编程实现布隆过滤器时,一般会使用一种称为开放寻址的策略来处理冲突,即当一个位置已被占用时,寻找下一个可用的位置。C语言或其他编程语言中,可以使用位操作来高效地设置和检查数组中的位。例如,C语言的实现可能包括定义一个大的unsigned long数组,利用位运算符(如<<和&)来实现哈希函数和位操作。
布隆过滤器是一种权衡空间和准确性的工具,适合于大数据环境下的快速查询。虽然其存在误判,但在许多应用场景中,这种微小的牺牲可以换取显著的性能提升。例如,在垃圾邮件过滤、URL去重、缓存系统等领域,布隆过滤器已经展现出强大的实用性。
通过实例解析布隆过滤器工作原理及实例通过实例解析布隆过滤器工作原理及实例
布隆过滤器布隆过滤器
布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用
来告诉你 “一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切
的。
布隆过滤器的工作原理布隆过滤器的工作原理
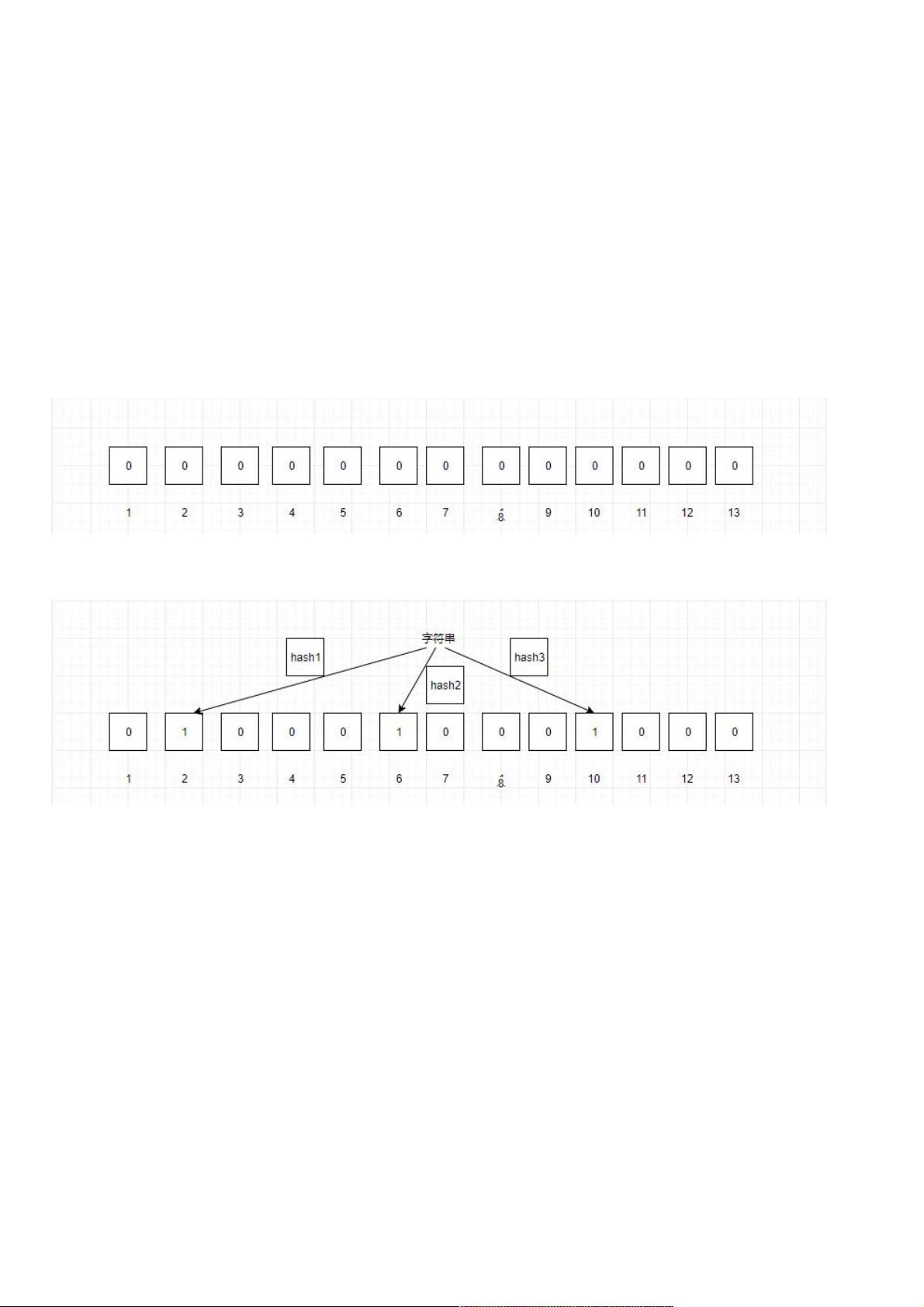
假设一个长度为m的bit类型的数组,即数组中每个位置只占一个bit,每个bit只有两种状态:0,1,所有bit的初始状态都为0。
再假设一共有k个哈希函数,这些函数的输出域大于或者等于m,并且这些哈希函数,彼此之间相互独立,每个哈希函数计算
出来的结果是独立的,可能相同也可能不相同,对每一个计算出来的结果都对m取余(%m),然后再将数组下标位置置为
1。
我们这里假设m为13,k为3的布隆过滤器,来看看布隆过滤器的工作原理:
当我们要映射一个值到布隆过滤器时,首先计算三个哈希函数的值,然后对13取余,映射到对应位中,图中映射到
2,6,10,这样我们就完成了一个值的映射。
那么怎么判断一个值是否存在,当一个值输入时,通过三个哈希函数,然后取余,我们就可以得到对应的三个位置,我们只需
要判断这三个位置是否都为1,如果都为1,则该值存储,反之不存在。
但是有一个特殊情况,前面说了不同的哈希函数可能计算可能相同也可能不相同,而且不同的哈希函数对不同的值计算出来的
值可能一样,这就造成一个结果,一个值通过哈希和取余得到的位置,早就被其它值给置1了,当我们存储的值过多,而这个
bit数组过小,都会造成这种情况更多的发生,一个值明明不存在,而它的所有位置早就被其它不同值置1,造成了误判,这里
就对布隆过滤器提出了一个指标:失误率p。
在同样数据规模下,不同大小的bit数组及不同数量k的哈希函数对误判率的结果:
下载后可阅读完整内容,剩余3页未读,立即下载
329 浏览量
239 浏览量
1570 浏览量
2023-08-08 上传
412 浏览量
点击了解资源详情
2023-02-06 上传
173 浏览量
329 浏览量

weixin_38545961
- 粉丝: 5
- 资源: 963
 我的内容管理
展开
我的内容管理
展开







最新资源
- javascript-carnival
- 2009中国大学创业富豪榜
- 文件加密练习.zip
- AVNCommunication8
- Wing Designer:Wing Designer 根据机翼和发动机参数计算飞机性能指标。-matlab开发
- javaScriptCardio:每日原始Javascript练习,复杂程度不一
- Drawer-Behavior-Flutter:抽屉行为是一个在抽屉上提供额外行为的库,例如,当抽屉在幻灯片上时,移动视图或缩放视图的高度
- flink 基础教程
- AirplaneManager-APCS-Project
- OrthoView:用于交互式查看 3D 体积的 GUI。-matlab开发
- 51单片机设计数码管显示秒表keil工程文件C源文件
- 图书管理系统(VB+SQL)
- powerampapi:Poweramp API
- 基于DHCP的网络配置实验文档.rar
- CIFAR-10 Dataset-数据集
- 中环绿健室内环保打造专业的品牌
