MongoDB聚合查询实战:使用pymongo进行统计分析
28 浏览量
更新于2024-08-28
1
收藏 91KB PDF 举报
"这篇文档介绍了如何在Python的pymongo库中使用聚合查询来处理MongoDB数据库中的数据,特别是针对统计分析和数据分组的需求。文章通过一个水果价格的例子,展示了如何避免传统的循环遍历和计数方法,转而利用聚合查询的高效性。"
在MongoDB中,聚合查询是一种强大的工具,它允许我们对数据进行处理和分析,类似于SQL中的`GROUP BY`、`COUNT`等操作。在pymongo中,聚合查询是通过`aggregate`函数实现的,该函数接收一个名为`pipeline`的参数,这是一个包含多个阶段(stages)的列表,每个阶段定义了一种数据处理操作。
假设我们有一个名为`FruitPrice`的集合,存储着水果价格的数据,字段包括`fName`(水果名称)和`price`(价格)。如果我们想要统计每种水果的数量,传统的方法可能需要先查询所有数据,然后在Python中遍历并计数,这样的效率较低。而使用聚合查询,我们可以直接在数据库层面完成计数。
以下是一个使用pymongo进行聚合查询的例子:
```python
from pymongo import MongoClient
client = MongoClient(host=['%s:%s' % (mongoDBhost, mongoDBport)])
G_mongo = client[mongoDBname]['FruitPrice']
# 定义聚合管道
pipeline = [
{'$group': {'_id': "$fName", 'count': {'$sum': 1}}},
]
# 执行聚合查询
for i in G_mongo.aggregate(pipeline):
print(i)
```
这段代码首先定义了一个聚合管道,其中`'$group'`阶段用于按`fName`字段分组,并计算每组的计数(`$sum`为1表示每条记录增加1)。执行`aggregate`后,会输出每种水果的计数,例如:`{u'count':8,u'_id':u'banana'}`。
若要进一步筛选价格在50以上的水果,可以在聚合管道中添加`'$match'`阶段:
```python
pipeline = [
{'$match': {'price': {'$gte': 50}}},
{'$group': {'_id': "$fName", 'count': {'$sum': 1}}},
]
```
这里的`'$match'`阶段会先过滤出价格大于等于50的记录,然后再进行分组计数。
聚合查询的效率在于它可以在数据库服务器上直接处理数据,减少了数据传输和客户端的计算负担。在处理大量数据或需要复杂统计分析时,聚合查询是必不可少的工具。通过灵活组合不同的聚合阶段,如`'$group'`、`'$match'`、`'$sort'`、`'$project'`等,可以实现丰富的数据分析需求。
pymongo中聚合查询的使用方法中聚合查询的使用方法
前言前言
在使用mongo数据库时,简单的查询基本上可以满足大多数的业务场景,但是试想一下,如果要统计某一荐在指定的数据中
出现了多少次该怎么查询呢?笨的方法是使用find 将数据查询出来,再使用count() 方法进行数据统计,这个场景还好,但是
如果要求其中某个字段的和呢?是不是就非得遍历出相应的数据然后再进行求和运算呢?
在mysql中我们经常会用到count、group by 等查询,在mongodb中我们也可以使用聚合查询。
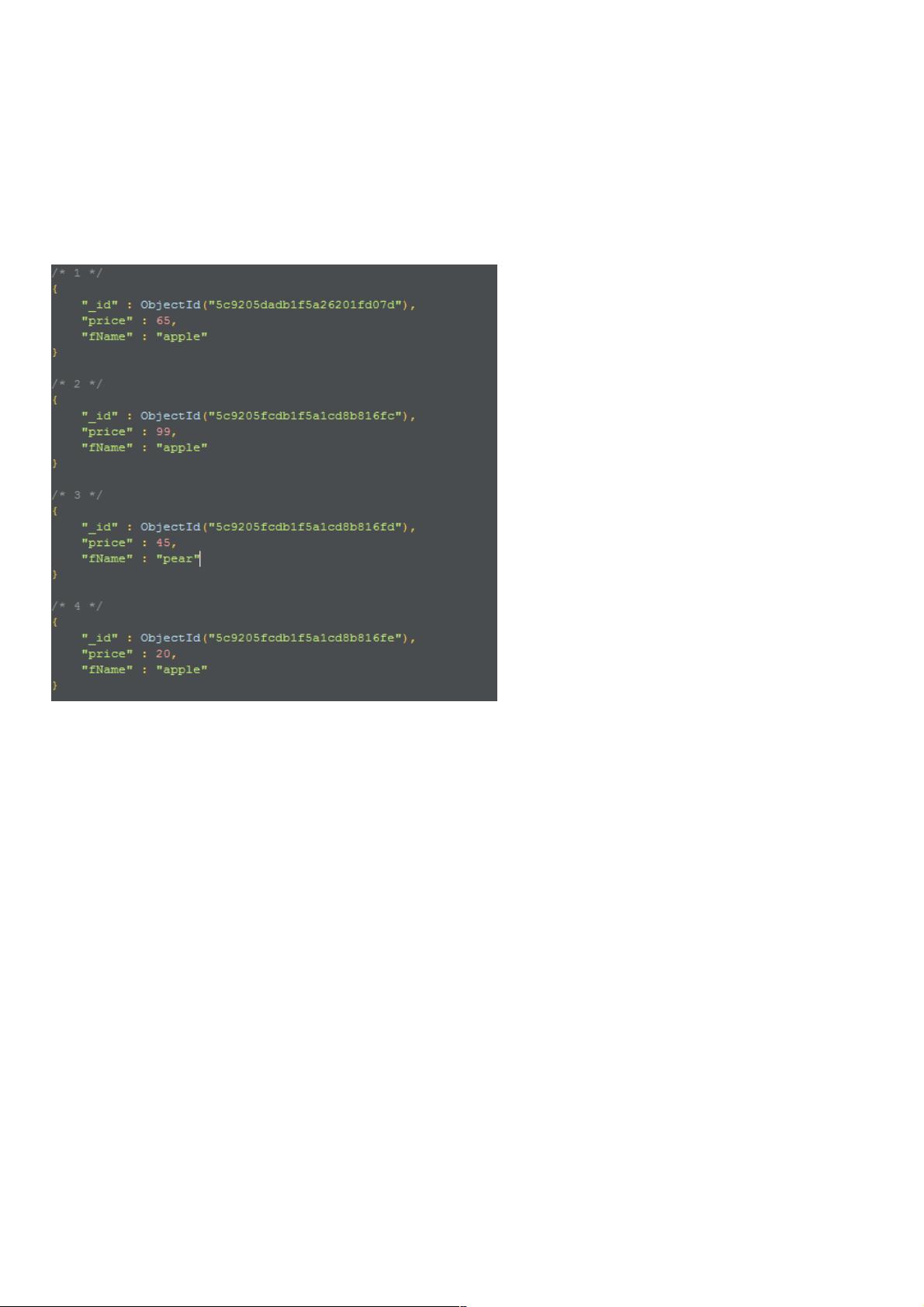
假设有这样的一组数据
价格
里面记录了每种水果的价格,现在我要统计一下,各种水果在这张表中出现的次数,如果不用聚合查询的话,思路应该是这
样,先把表中所有的数据都取出来,然后初始化一个字典,然后再遍历每一行的数据,获取它的fName ,然后再更新字典中
的计数,这种方法的时间复杂度是O(N)的,如果数据量很大的话不是很好,下面来看一下使用聚合是怎么查询的。
聚合查询使用的是aggregate函数,它的参数是 pipeline 管道,管道的概念是用于将当前命令的输出结果作为下一个命令的参
数,管道是有顺序的,比如通过第一个管道操作以后没有符合的数据那么之后的管道操作也就不会有输入,所以一定得要注意
管道操作的顺序。由于对于上述问题,我们要的是所的数据统计,所以这里就不需要$match了
from pymongo import MongoClient
client = MongoClient(host=['%s:%s'%(mongoDBhost,mongoDBport)])
G_mongo = client[mongoDBname]['FruitPrice']
pipeline = [
{'$group': {'_id': "$fName", 'count': {'$sum': 1}}},
] for i in G_mongo['test'].aggregate(pipeline):
print i
数据大家可以自已构造,这里主要是看aggregate的用法。
得到的结果是
{u'count': 8, u'_id': u'banana'}
{u'count': 9, u'_id': u'pear'}
{u'count': 14, u'_id': u'apple'}
可以看到,一步操作就可以得到相应的统计了。
如果想要获取价格在50以上的各种统计呢?
这时有pipeline应该再$group 之前加上$match 操作
下载后可阅读完整内容,剩余3页未读,立即下载
4554 浏览量
234 浏览量
751 浏览量
452 浏览量
2023-04-28 上传
2024-08-08 上传
2024-08-08 上传
369 浏览量
411 浏览量

weixin_38659374
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- VS2010环境Qt链接MySQL数据库测试程序
- daycula-vim主题:黑暗风格的Vim色彩方案
- HTTPComponents最新版本发布,客户端与核心组件升级
- Android WebView与JS互调的实践示例
- 教务管理系统功能全面,操作简便,适用于winxp及以上版本
- 使用堆栈实现四则运算的编程实践
- 开源Lisp实现的联合生成算法及多面体计算
- 细胞图像处理与模式识别检测技术
- 深入解析psimedia:音频视频RTP抽象库
- 传名广告联盟商业正式版 v5.3 功能全面升级
- JSON序列化与反序列化实例教程
- 手机美食餐饮微官网HTML源码开源项目
- 基于联合相关变换的图像识别程序与土豆形貌图片库
- C#毕业设计:超市进销存管理系统实现
- 高效下载地址转换器:迅雷与快车互转
- 探索inoutPrimaryrepo项目:JavaScript的核心应用
