Python使用pdfminer读取PDF文本内容教程
182 浏览量
更新于2024-08-28
收藏 104KB PDF 举报
"Python解析并读取PDF文件内容的方法,主要使用了pdfminer库,适用于Python2.7环境。"
在Python中,处理PDF文件内容通常需要借助第三方库,其中`pdfminer`是一个强大的工具,它能够解析PDF文档并提取文本内容。本实例将详细介绍如何使用`pdfminer`库来实现这一功能。
首先,为了读取PDF文本内容,我们需要确保Python环境是Python2.7,并且已经安装了`pdfminer`库。可以通过在命令行中执行`pip install pdfminer`来安装此库。
在使用`pdfminer`之前,需要导入相关的模块,包括`PDFParser`、`PDFDocument`、`PDFResourceManager`、`PDFPageInterpreter`、`PDFPageAggregator`、`LTTextBoxHorizontal`、`LAParams`以及`PDFTextExtractionNotAllowed`。这些模块提供了解析PDF文档、管理资源、解释PDF页面、布局分析等功能。
接下来,定义一个名为`CPdf2TxtManager`的类,用于处理PDF到文本的转换。在类的构造函数中,没有特殊的初始化操作,但可以预留给后续扩展使用。
核心功能在`changePdfToText`方法中,这个方法接受一个PDF文件路径作为参数。首先,以二进制读模式打开文件,然后创建一个`PDFParser`对象来解析PDF文档,接着创建一个`PDFDocument`对象。通过`set_document`和`set_parser`方法将解析器与文档对象关联,并设置初始密码(如果有的话)。
在检查文档是否允许文本提取后,创建一个`PDFResourceManager`实例,它负责管理共享资源。再创建一个`PDFPageAggregator`对象,它是PDF页面内容的聚合器,用于将解析后的页面内容组合成可读的布局元素。
接下来,通过`PDFPageInterpreter`解释PDF页面,遍历PDF文档的每一页,将每页的内容转化为`LTObject`实例,这些对象包含了页面上的文本、图像等元素。在这个过程中,`LAParams`用于设置布局分析参数。
最后,当遍历完所有页面,`LTTextBoxHorizontal`对象将包含PDF文档的文本内容。通过遍历这些文本框,我们可以提取出文本并添加到结果列表中。
整个过程完成后,`CPdf2TxtManager`类可以处理多个PDF文件,将每个PDF的文本内容以列表形式返回,便于进一步的处理或分析。
Python通过`pdfminer`库提供了一种有效的方式来解析和读取PDF文件的内容,这对于数据挖掘、文档自动化处理等场景非常有用。只要正确配置环境并按照上述步骤操作,就能轻松实现PDF文本的提取。
Python解析并读取解析并读取PDF文件内容的方法文件内容的方法
本文实例讲述了Python解析并读取PDF文件内容的方法。分享给大家供大家参考,具体如下:
一、问题描述一、问题描述
利用python,去读取pdf文本内容。
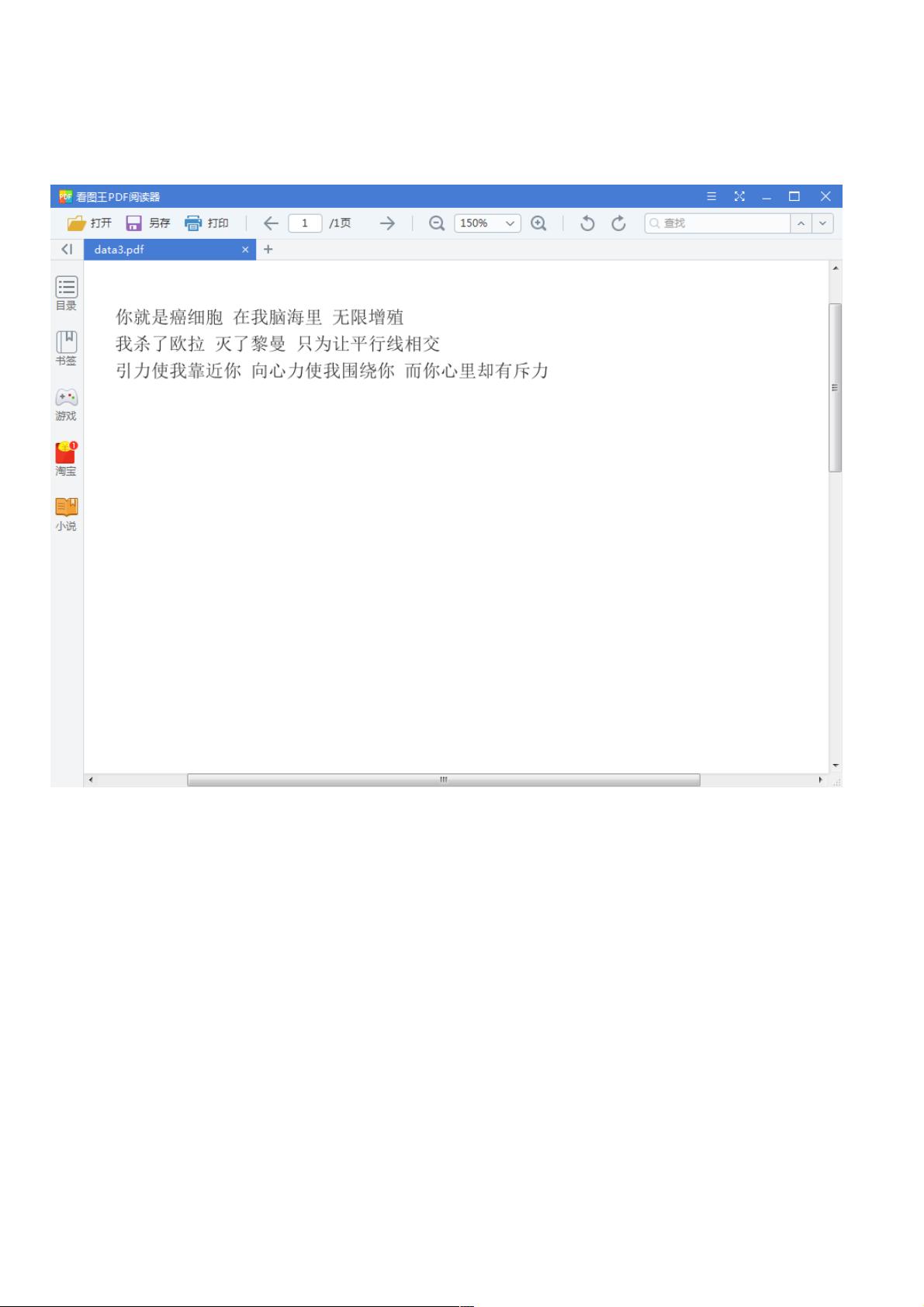
二、效果二、效果
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
2020-09-21 上传
2020-09-19 上传
2020-09-21 上传
2020-12-21 上传
2018-12-20 上传

weixin_38723373
- 粉丝: 7
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网上书店可行性分析与需求分析
- C语言编程规范.pdf
- SQL server服务器大内存配置
- 世界上最全的oracle笔记 oracle 资料
- Programming C#
- MIT Linear Programming Courseware- example
- 一份在线考试系统的详细开发文档C#
- 在线考试系统需求说明
- 企业网站推广经合与体会
- convex optimization
- 芯源电子单片机教程(推荐).pdf
- c语言学习300例(实例程序有源码)
- thinking in java
- How to create your library
- Microsoft Windows CE学习资料
- _CC2001教程_研究与思考.pdf
