互联网大厂大数据面试高频题:Linux与Hadoop命令详解
版权申诉
107 浏览量
更新于2024-07-05
收藏 2.65MB PDF 举报
本文档是一份针对大数据领域互联网大厂面试的高频问题及其答案汇总,内容涵盖Linux与Shell编程技能,以及Hadoop相关的技术知识。以下是详细解读:
1. **Linux & Shell命令基础**:
- `top`:用于实时监控系统资源使用情况,如内存和CPU使用率。
- `df -h`:查看磁盘分区的使用情况,包括总空间、已用空间和剩余空间。
- `iotop`:监控Linux系统中的I/O操作,通过`yum install iotop`安装。
- `iotop -o`:筛选出I/O密集型进程,以便优化性能。
- `netstat -tunlp | grep 端口号`:检查网络连接和端口占用状态。
- `uptime`:提供系统运行时间和负载平均值。
- `ps -aux`:显示当前所有用户的进程详细信息。
2. **Shell编程实战经验**:
- 使用Shell脚本进行任务自动化,如集群启动脚本、数据仓库的MySQL导入导出,以及内部数据迁移。
- 当需要杀死一个不知道进程号但知道其特征(如脚本名和参数)的进程时,可以通过`ps -ef | grep`筛选相关行,再结合`awk`和`xargs kill`执行杀进程操作。
- 单引号和双引号的区别:单引号不解析变量,双引号会解析变量;反引号`用于执行命令并获取其输出。
3. **Hadoop技术要点**:
- Hadoop常用端口号:HDFS(50070, 9870), MapReduce(8088, 8088), History Server(19888), Namenode/Jobtracker的客户端端口(9000, 8020)。
- 配置文件:Hadoop 2.x和3.x版本的`core-site.xml`, `hdfs-site.xml`, `mapred-site.xml`, `yarn-site.xml`有所不同。
- 集群搭建步骤包括安装JDK,配置核心文件,并简述了基础的Hadoop集群构建流程。
这份文档对求职者来说是宝贵的面试准备资料,它不仅测试了应聘者的实际操作能力和对Linux和Hadoop技术的理解,还考察了Shell编程的灵活性和问题解决能力。理解这些知识点不仅能提升面试表现,也能在日常工作中提高效率。
(1)NodeManager默认内存8G,需要根据服务器实际配置灵活调整,例如128G内存,配置为
100G内存左右,yarn.nodemanager.resource.memory-mb。
(2)单任务默认内存8G,需要根据该任务的数据量灵活调整,例如128m数据,配置1G内存,
yarn.scheduler.maximum-allocation-mb。
(3)mapreduce.map.memory.mb :控制分配给MapTask内存上限,如果超过会kill掉进程
(报:Container is running beyond physical memory limits. Current usage:565MB of512MB
physical memory used;Killing Container)。默认内存大小为1G,如果数据量是128m,正常不需要
调整内存;如果数据量大于128m,可以增加MapTask内存,最大可以增加到4-5g。
(4)mapreduce.reduce.memory.mb:控制分配给ReduceTask内存上限。默认内存大小为1G,
如果数据量是128m,正常不需要调整内存;如果数据量大于128m,可以增加ReduceTask内存大小为
4-5g。
(5)mapreduce.map.java.opts:控制MapTask堆内存大小。(如果内存不够,报:
java.lang.OutOfMemoryError)
(6)mapreduce.reduce.java.opts:控制ReduceTask堆内存大小。(如果内存不够,报:
java.lang.OutOfMemoryError)
(7)可以增加MapTask的CPU核数,增加ReduceTask的CPU核数
(8)增加每个Container的CPU核数和内存大小
(9)在hdfs-site.xml文件中配置多目录
(10)NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数
据操作。dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为10台时,此参数设置
为60。
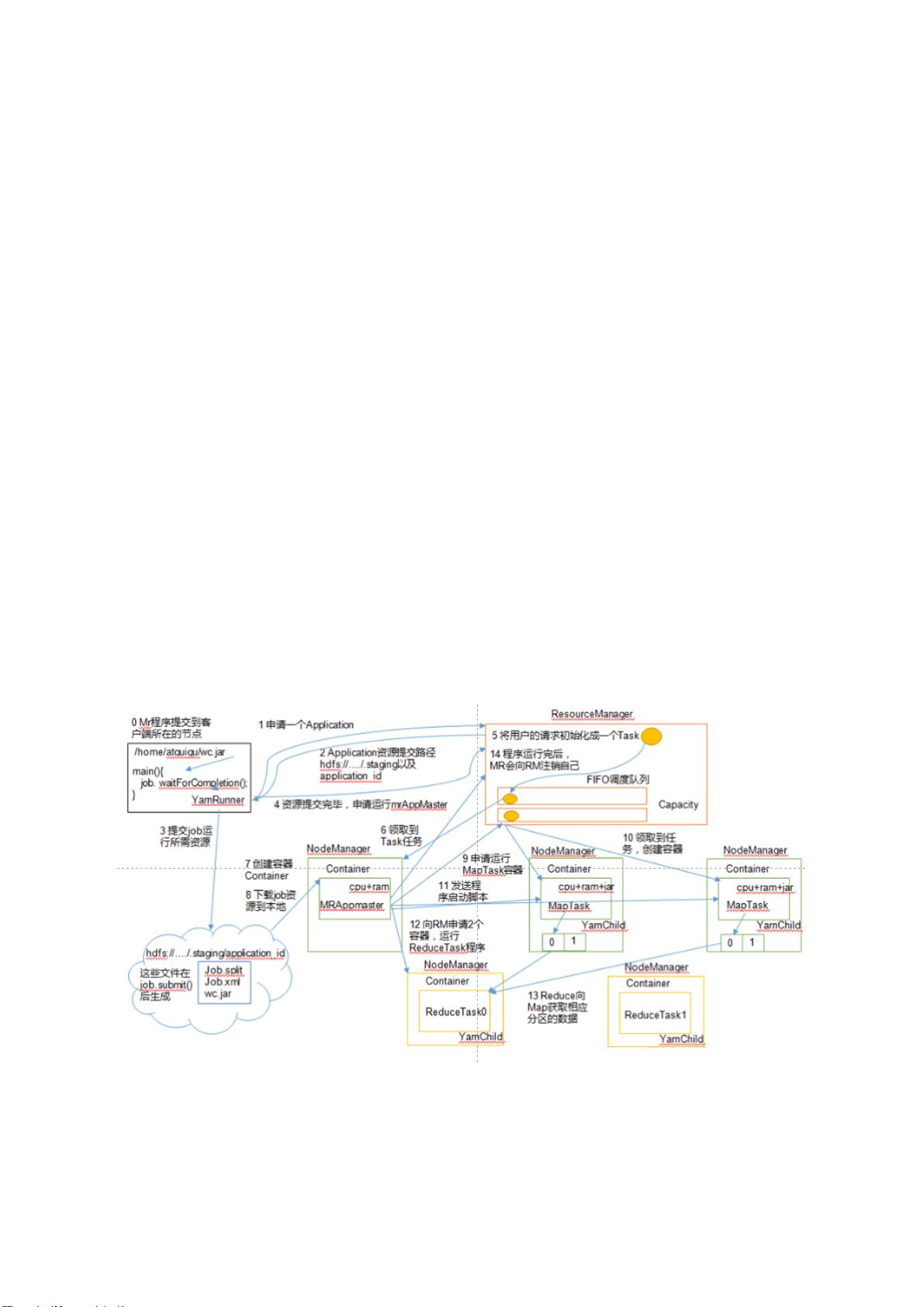
1.2.6 Yarn工作机制
1.2.7 Yarn调度器
1)Hadoop调度器重要分为三类:
FIFO 、Capacity Scheduler(容量调度器)和Fair Sceduler(公平调度器)。
Apache默认的资源调度器是容量调度器;
CDH默认的资源调度器是公平调度器。

剩余31页未读,继续阅读
120 浏览量
522 浏览量
217 浏览量
2023-08-07 上传
2024-03-05 上传


智慧化智能化数字化方案
- 粉丝: 1596
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- win_udp:Windows网络udp框架服务器和侦听器
- 如何规划团队训练课程PPT
- torch_cluster-1.5.5-cp36-cp36m-linux_x86_64whl.zip
- 取Excel表格有数据单元格的起讫行列.rar
- zencharts:将 High Charts 库的强大功能与 Zendesk Developer API 相结合的小型应用程序
- wild-rydes:野生莱德
- Redosnap Launcher-crx插件
- CNN_for_brain_ventricles_segmentation:“个人3D脑图集”项目。 利用全卷积神经网络对大脑的CT数据进行分割
- 批量修改文件名.zip
- 取Excel表格有数据单元格的起讫行、列.rar
- html2text:用 Go 编写的 html 到文本转换器
- torch_scatter-2.0.4-cp37-cp37m-win_amd64whl.zip
- Email Notifier-crx插件
- yun-text:“云杯”景区声誉评价得分预测中第三个解决方案的DL部分
- milestoneproject2-memorygame:一种记忆游戏,要求用户匹配隐藏在牌组中的成对纸牌
- Android Binder通信案例
