
Kafka基本架构介绍基本架构介绍
1、什么是消息系统?
消息系统负责将数据从一个应用程序传输到另一个应用程序,因此应用程序可以专注于数据,但不担心如何共享它。 分布式
消息传递基于可靠消息队列的概念。 消息在客户端应用程序和消息传递系统之间异步排队。 有两种类型的消息模式可用 - 一
种是点对点,另一种是发布 - 订阅(pub-sub)消息系统。 大多数消息模式遵循 pub-sub 。
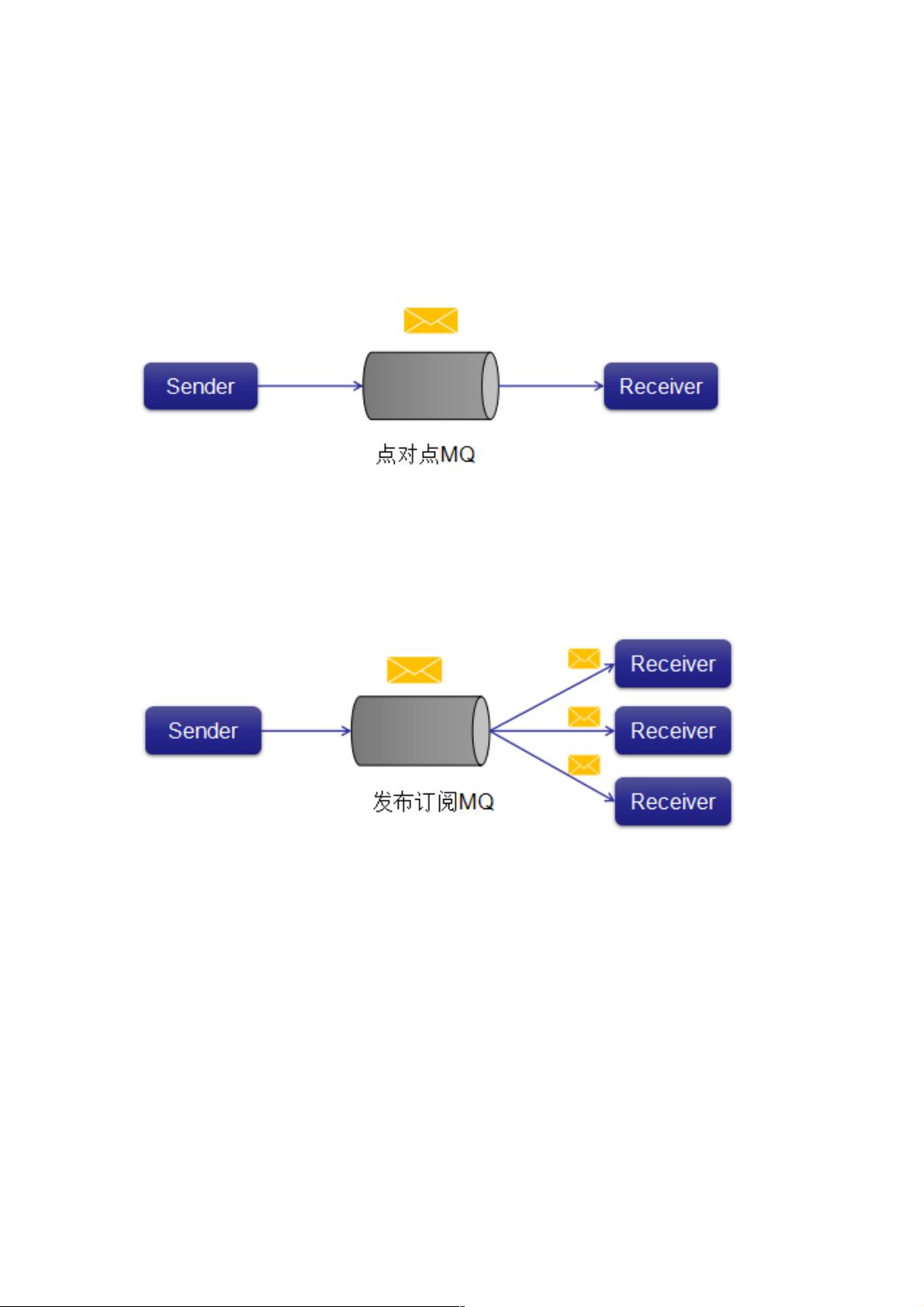
(1)点对点消息系统
在点对点系统中,消息被保留在队列中。 一个或多个消费者可以消耗队列中的消息,但是特定消息只能由最多一个消费者消
费。 一旦消费者读取队列中的消息,它就从该队列中消失。 该系统的典型示例是订单处理系统,其中每个订单将由一个订单
处理器处理,但多个订单处理器也可以同时工作。 下图描述了结构。
(2)发布 - 订阅消息系统
在发布 - 订阅系统中,消息被保留在主题中。 与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消
息。 在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。 一个现实生活的例子是Dish电视,它发布不同
的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。
2、什么是Kafka?
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传
递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建
在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
Kafka专为分布式高吞吐量系统而设计。 与其他消息传递系统相比,Kafka具有更好的吞吐量,内置分区,复制和固有的容错
能力,这使得它非常适合大规模消息处理应用程序。
Kafka可以在许多用例中使用, 其中一些列出如下:
指标 - Kafka通常用于操作监控数据。 这涉及聚合来自分布式应用程序的统计信息,以产生操作数据的集中馈送。
日志聚合解决方案 - Kafka可用于跨组织从多个服务收集日志,并使它们以标准格式提供给多个服务器。
流处理 - 流行的框架(如Storm和Spark Streaming)从主题中读取数据,对其进行处理,并将处理后的数据写入新主题,供用户
和应用程序使用。 Kafka的强耐久性在流处理的上下文中也非常有用。
3、Kafka架构
深入学习Kafka之前,必须了解主题(Topic)、经纪人(Broker)、生产者(Producer)或者发布者,以及消费者
(Consumer)或者订阅者等主要术语。 下图说明了主要术语,表格详细描述了图表组件。
下载后可阅读完整内容,剩余3页未读,立即下载

weixin_38654382
- 粉丝: 1
- 资源: 932
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


