SQL2005排名函数row_number、rank、dense_rank与ntile详解
SQL Server 2005引入了四个强大的排名函数:row_number、rank、dense_rank和ntile,这些函数在数据分析和报表生成中具有广泛的应用。本文将逐一探讨这些函数的功能、用法以及它们之间的区别。
首先,row_number函数是最基础的排名函数,它为查询结果中的每一行生成唯一的序号。例如,通过以下SQL语句:
```sql
SELECT row_number() OVER (ORDER BY field1) AS row_number, *
FROM t_table
```
函数会根据field1字段的值对记录排序,并为每个记录分配一个连续的序号。值得注意的是,over子句中的排序独立于外部的ORDER BY语句,如下面的例子:
```sql
SELECT row_number() OVER (ORDER BY field2 DESC) AS row_number, *
FROM t_table
ORDER BY field1 DESC
```
这里,尽管外部排序是按照field1降序,但row_number仍基于field2的降序排列。
rank函数与row_number类似,但如果有多个记录具有相同的排名,它们将获得相同的序号。这意味着,如果有两个或更多的记录具有相同的field1值,它们的rank可能不是连续的。
dense_rank函数与rank的区别在于,它在有相同排名时会确保相邻的序号。这意味着如果存在并列,它们之间的空缺会被填补,序号不会跳跃。
最后,ntile函数将结果集分成等大的分区(tile),每个分区包含特定数量的行。例如,`NTILE(5)`将数据分为5个相等的部分,每个部分包含四分之一的数据。每个记录将被分配到一个tile内,而不是具体的序号。
在实际应用中,row_number常用于分页查询和计数,而rank和dense_rank可能用于统计排名和异常检测。ntile则在数据分组和性能优化中提供灵活的分区方式。
理解并熟练掌握这些排名函数有助于提高SQL查询的效率和准确性,特别是在处理大量数据时,合理的使用这些函数能够简化复杂度并优化性能。在编写SQL语句时,根据具体需求选择合适的排名函数是至关重要的。
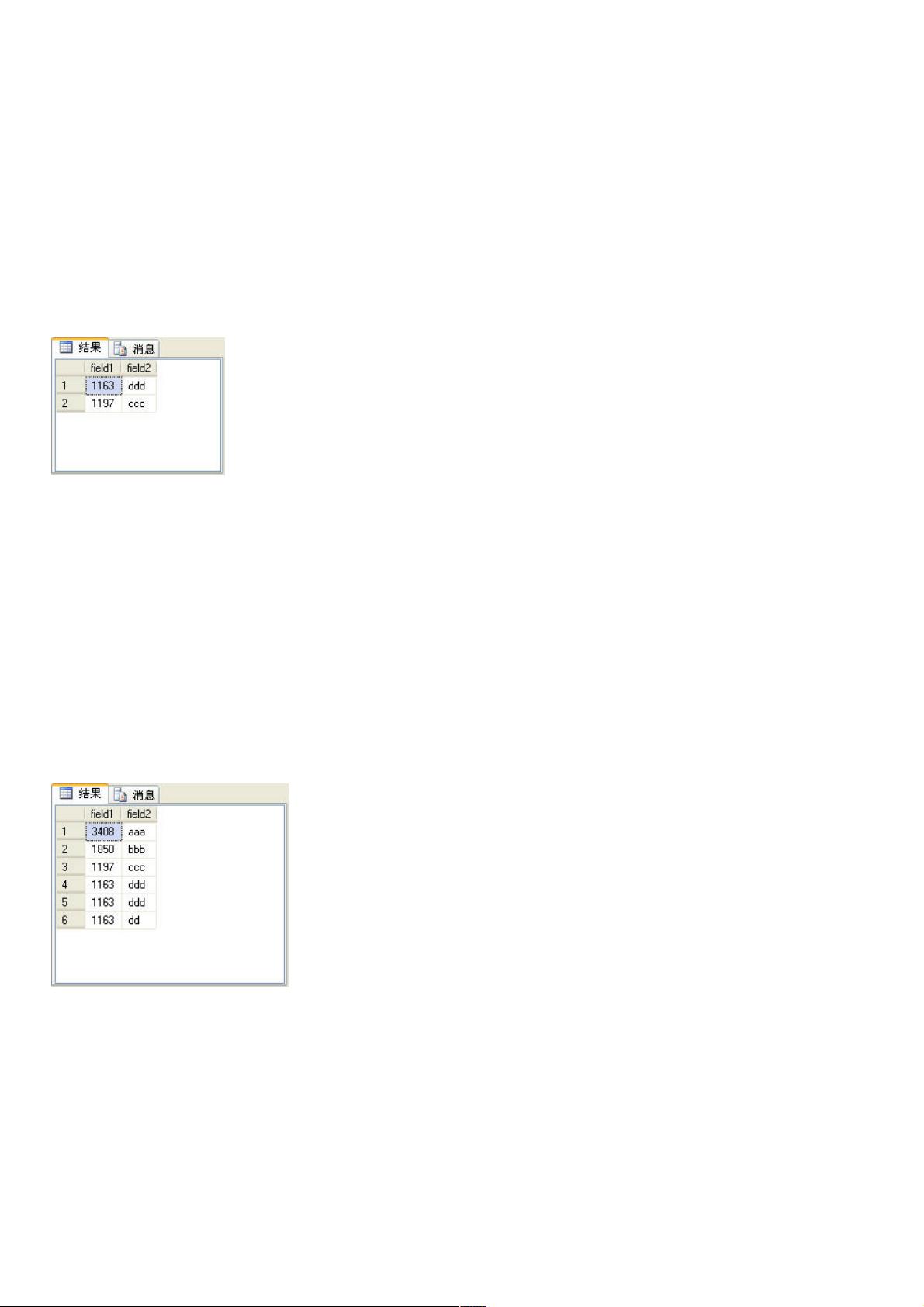
另外要注意的是,如果将row_number函数用于分页处理,over子句中的order by 与排序记录的order by 应相同,否则生
成的序号可能不是有续的。
当然,不使用row_number函数也可以实现查询指定范围的记录,就是比较麻烦。一般的方法是使用颠倒Top来实现,例
如,查询t_table表中第2条和第3条记录,可以先查出前3条记录,然后将查询出来的这三条记录按倒序排序,再取前2条记
录,最后再将查出来的这2条记录再按倒序排序,就是最终结果。SQL语句如下:
select * from(select top2 * from(select top3 * from t_table order by field1)a
order by field1 desc) b order by field1
上面的SQL语句查询出来的结果如图5所示。
图5
这个查询结果除了没有序号列row_number,其他的与图4所示的查询结果完全一样。
二、rank
rank函数考虑到了over子句中排序字段值相同的情况,为了更容易说明问题,在t_table表中再加一条记录,如图6所示。
图6
在图6所示的记录中后三条记录的field1字段值是相同的。如果使用rank函数来生成序号,这3条记录的序号是相同的,而
第4条记录会根据当前的记录数生成序号,后面的记录依此类推,也就是说,在这个例子中,第4条记录的序号是4,而不是
2。rank函数的使用方法与row_number函数完全相同,SQL语句如下:
select rank() over(order by field1),* from t_table order by field1
剩余10页未读,继续阅读
相关推荐





weixin_38727199
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握JavaScript:经典实例全书源码解析
- VC++项目开发源代码精析:第一章至第四章
- 响应式FLAT商务宽屏Bootstrap项目源码下载
- TS文件解析:如何提取节目信息
- 专家推荐:PMP认证备考必备资料合集
- 虚幻引擎4构建RTS游戏的Agora项目介绍
- 绿色版jd-gui windows:Java反编译工具
- Apache Tomcat 7.0.65部署指南:跨平台Web服务器配置
- XiongFeiTan博客:Jekyll技术支持下的灵感与思考交流平台
- 绿色版驱动精灵单机版:简洁查看电脑设备
- ESP32-GUI-Flasher:全新GUI工具助力ESP32固件刷新
- SynToy:硬盘与U盘资源同步新工具
- 命令行工具wifi-password:跨平台获取wifi密码
- C# 双接口实现及定时器数据处理源码解析
- 细搜天气7.0.3黑莓免费版功能体验与更新问题
- Unreal Engine 4流映射燃烧效果Shader教程
