TensorFlow实现感知器:深度学习入门线性分类
37 浏览量
更新于2024-08-28
收藏 529KB PDF 举报
深度学习:感知器学习算法
**简介**
在深入理解深度学习的过程中,感知器作为构建神经网络的基础单元,是我们探索之旅的起点。通过使用TensorFlow,我们可以学习如何利用这种简单但强大的模型来解决线性和非线性分类问题。对于初学者来说,先阅读系列教程的前文可以避免混淆。
**感知器概念**
感知器是一种线性分类器,它的工作原理是根据输入特征的线性组合来决定输出类别。在TensorFlow中,我们可以用它来处理诸如声纳数据分类这样的任务,比如区分猫和狗的声音。线性可分问题意味着数据可以通过一条直线清晰地划分,如区分动物类别,而非线性可分问题则需要复杂的函数来分离,如手写数字识别。
**实现和门**
在实现感知器算法时,我们通常从导入必要的库开始,如TensorFlow库。例如:
```python
import tensorflow as tf2
```
然后,我们需要定义输入和输出的向量变量,例如定义一个二进制的“和”门输入和期望输出:
```python
input_vector = tf2.placeholder(tf.float32, shape=(None, 2)) # 二元输入
output_vector = tf2.placeholder(tf.float32, shape=(None, 1)) # 二元输出(0或1)
```
**数学表示**
感知器的数学表达式是基于权重(weights)、输入(inputs)和偏置(bias)的乘积加上偏差项。输出y是一个函数,表示为:
\[ y = \sigma(\sum w_i x_i + b) \]
其中,\( w_i \) 是权重,\( x_i \) 是输入特征,\( \sigma \) 是激活函数(例如sigmoid函数),\( b \) 是偏置。
**感知器学习过程**
感知器学习的目标是调整权重和偏置,使得输入数据经过线性变换后,输出尽可能接近真实类别。这通常通过梯度下降或其他优化算法来完成,如最小化损失函数(如交叉熵损失)。
**示例:实现和门**
实际代码会包括训练循环,其中涉及到计算预测值、计算误差、更新权重和偏置等步骤。对于和门,当输入中两个输入都是1时,输出应该是1,否则输出为0。我们可以通过反向传播来调整权重,使预测结果接近于真实输出。
**复杂性与扩展**
当面临更加复杂的问题,如图像识别,感知器不足以捕捉数据中的非线性关系,这时就需要引入多层神经网络,如多层感知器或多层卷积神经网络。这些模型能够通过非线性组合处理更高级别的抽象和特征提取。
总结起来,深度学习中的感知器学习算法为我们提供了一个基础框架,通过理解其工作原理和在TensorFlow中的实现,我们可以逐渐扩展到更复杂的神经网络结构,解决更多实际问题。
深度学习:感知器学习算法深度学习:感知器学习算法
介绍
因为你知道感知器是创建深层神经网络的基本构件,因此,很明显,我们应该从感知器开始掌握深层学习的旅程,并学习如何
使用TensorFlow来实现它来解决不同的问题。如果你对深度学习还不太熟悉,我建议你浏览一下这个深度学习教程系列的前
一篇博客,以避免任何困惑。以下是本博客中关于感知器学习算法的主题:
感知器作为线性分类器使用TensorFlow库实现感知器声纳数据分类使用单层感知器分类问题类型
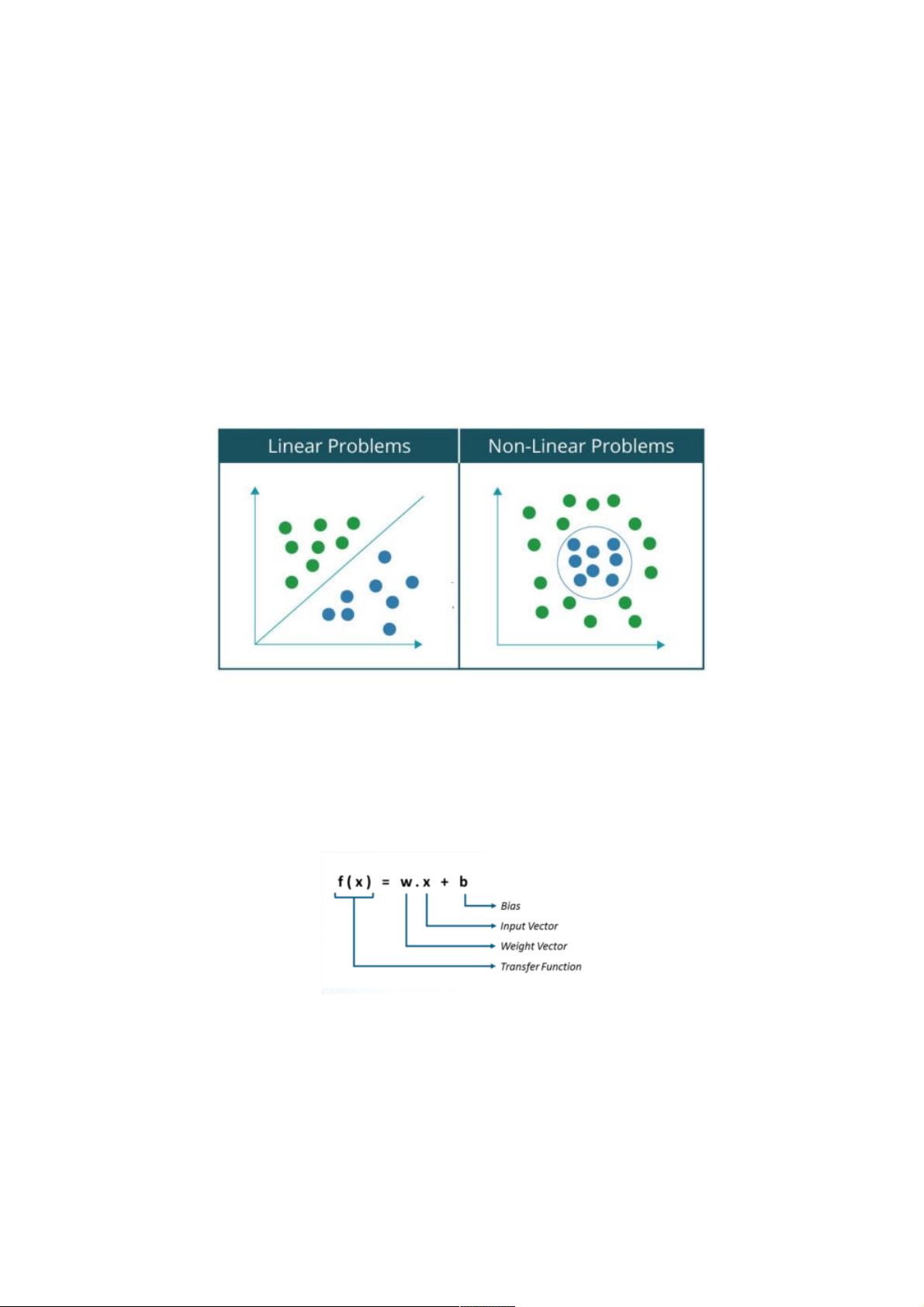
可以对各种分类问题进行分类可以用神经网络分为两大类:
线性可分问题非线性可分问题
基本上,如果你能用一条线把数据集分为两类或两类,那么一个问题就称为线性可分问题。例如,把猫和一群猫狗分开。相
反,在一个非线性可分问题中,数据集包含多个类,需要非线性线将它们分离到各自的类中。例如,手写数字的分类。让我们
通过绘制线性可分问题和非线性问题数据集的图形来直观地看到两者之间的区别:,因为大家都熟悉和Gates,我将用它作为
一个例子来解释感知器如何作为线性分类器工作。
注意:当您着手处理更复杂的问题时,例如我在上一篇博客中简要介绍了图像识别技术,由于要捕获的数据中的关系变得高度
非线性,因此需要一个由多个人工神经元组成的网络,称为人工神经网络。
感知器as和Gate ,如你所知,在所有其他情况下,如果输入都是1和0,Gate会产生1的输出。因此,感知器可以用作分隔符
或决定线,将输入集和门分成两类:
类1:输出为0的输入位于决定线以下。
第2类:输出为1的输入,位于决定线或分隔符之上。下图显示了使用感知器对输入和门进行分类的上述想法:
到目前为止,您已经了解到线性感知器可用于将输入数据集分类为两类。但是,它实际上是如何对数据进行分类的呢? 在数
学上,可以将感知器表示为权重、输入和偏差(垂直偏移)的函数: 感知器接收到的每个输入都已根据其对获得最终输出的
贡献量进行了加权。偏差允许我们移动决策线,以便它能够最好地分离输入分为两类。
理论够了,让我们看看这个博客上的第一个关于感知器学习算法的例子,在这里我将从头开始使用感知器实现和门。
感知器学习算法:实现和门1。导入所有必需的库
我将从导入所有必需的库开始。在这种情况下,我只需要导入一个库,即TensorFlow:
#导入所需库将tensorflow导入为tf2。
为输入和输出 定义矢量变量现在,我将为我的感知器 创建用于存储输入、输出和偏差的变量#输入1、输入2和偏置列车进站=
[[1.,1.,1],[1,0,1],[0,1.,1],[0,0,1]]#输出列车开出=[[1.],[0],[0],[0]]
下载后可阅读完整内容,剩余5页未读,立即下载
134 浏览量
2010-05-07 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-20 上传
点击了解资源详情
点击了解资源详情









