人工智能异构集群调度与资源管理系统详解
版权申诉
68 浏览量
更新于2024-07-07
收藏 1.54MB PDF 举报
在【人工智能专题】7 异构计算集群调度与资源管理系统.pdf中,课程主要探讨了在现代AI应用中,特别是深度学习背景下,异构计算集群管理的重要性及其核心组件。异构计算集群由多租户GPU集群组成,每个用户可以根据需求申请不同的资源份额,如拥有100、20或10GPU的配额。这种多租户环境意味着服务器软件环境虽然单一,但作业和用户的需求却是多样化的,涉及深度学习作业的多种类型(如TFJob、PyTorchJob和MXNetJob)。
系统的核心功能包括:
1. **作业提交与管理**:用户需要提交作业,并处理可能存在的环境依赖问题。例如,作业可能需要特定版本的Python、TensorFlow等库,以及数据和模型文件。提交的作业通常会包含jobName、image(镜像)、dataDir、outputDir以及任务角色定义,如CPU、内存和GPU资源需求,以及命令行启动参数。
2. **资源调度与隔离**:系统负责根据作业的资源需求进行动态调度,确保每个作业在运行时拥有足够的资源且与其他作业隔离开来。这包括GPU的分配,以及作业执行完成后资源的释放。
3. **深度学习作业生命周期管理**:深度学习作业的整个生命周期,从提交、调度、执行到结束,都需要系统的支持。用户可以专注于模型创新,而无需关心底层基础设施的部署和管理。
4. **独占服务器执行**:对于深度学习任务,使用独占服务器可以避免环境和资源隔离问题,如P100 GPU服务器,只需提供预配置的环境路径(如本地的Anaconda3和CUDA),数据路径(如本地/data),并通过直接执行启动脚本来运行任务。
5. **环境依赖问题**:系统需要解决用户可能遇到的问题,比如服务器上缺乏个性化的作业运行环境,或者不同作业之间的依赖冲突。这需要通过有效的镜像管理和容器技术来解决,以确保作业能在统一的环境中稳定运行。
总结来说,异构计算集群调度与资源管理系统是人工智能开发中的关键组件,它提供了基础架构支持,提升了生产力,使得用户能够专注于模型创新,同时保证了作业的高效运行和资源的有效利用。通过深入理解并有效利用这些工具和技术,开发者可以更高效地部署和管理大规模的深度学习工作负载。
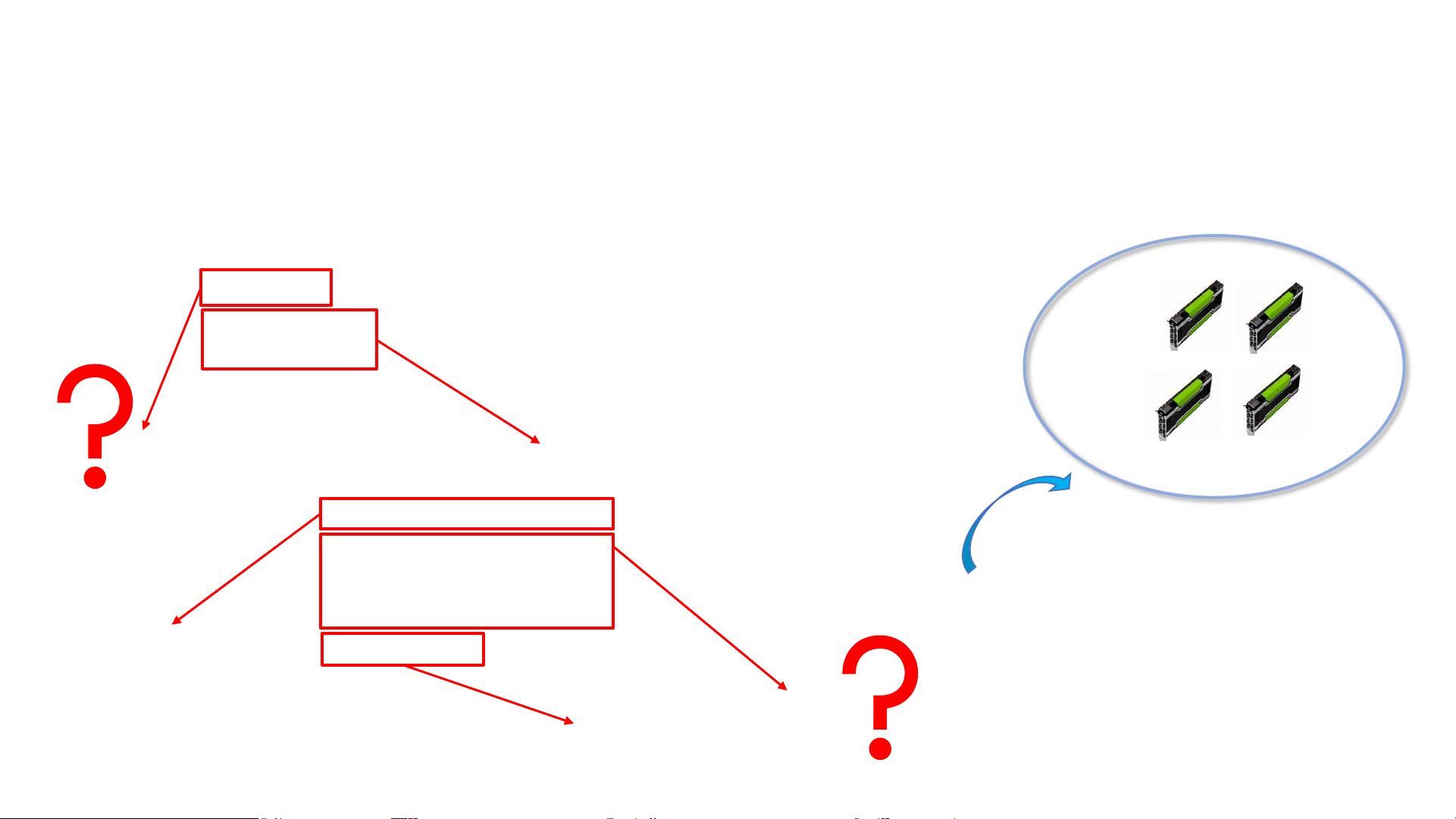
作业提交到平台
提交作业
P100
GPU集群
{
"jobName": "restnet",
"image": "example.tensorflow:stable",
"dataDir": "/tmp/data",
"outputDir": "/tmp/output",
...
"taskRoles": [
{
...
"taskNumber": 1,
"cpuNumber": 8,
"memoryMB": 32768,
"gpuNumber": 1,
"command": "python train.py --batch_size=256 \
--model_name=resnet50"
}
]
}
作业启动命令
资源占用
任务数量
环境依赖
数据与代码


剩余45页未读,继续阅读
2013-03-16 上传
2023-09-09 上传
2023-11-29 上传
2023-07-14 上传
2023-06-21 上传
2023-08-21 上传
2023-02-22 上传
2024-01-28 上传

mugui3
- 粉丝: 0
- 资源: 811
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
