TensorFlow实战:AutoEncoder自编码器详解与实现
63 浏览量
更新于2024-09-04
收藏 175KB PDF 举报
"本文介绍了如何使用TensorFlow实现AutoEncoder自编码器,通过在MNIST数据集上的实践,展示了自编码器的编码和解码过程,并对比了原始数据与解码后数据的效果。"
自编码器(AutoEncoder)是一种无监督学习方法,它主要用于数据的降维和特征提取。在TensorFlow中,我们可以构建一个自编码器模型,通过学习数据的内在结构,将高维数据压缩到较低维度,然后尝试恢复原始数据,以此来提取有效的特征表示。
在上述代码中,首先引入了所需的库,包括TensorFlow、NumPy和Matplotlib,以及MNIST数据集。MNIST是一个广泛使用的手写数字识别数据集,包含28x28像素的灰度图像。
模型的实现分为编码(encoding)和解码(decoding)两个阶段。编码阶段将输入数据(这里是784维的MNIST图像)映射到更低维的空间,例如256维(`n_hidden_1`)和128维(`n_hidden_2`)。在解码阶段,模型试图从低维表示重构原始输入。
权重和偏置参数是自编码器的核心组成部分。这里使用了随机初始化的权重矩阵(`tf.random_normal`),并且注意到编码层和解码层的权重是互逆的,即编码层的权重转置用于解码层。`weights`字典存储了各层之间的权重变量,`biases`字典存储了各层的偏置变量。
训练过程通常包括多个epoch,每个epoch中会随机选取一定数量的样本(batch_size)进行训练,以更新模型参数。在训练过程中,通过比较解码后的数据与原始输入的差异(通常使用均方误差作为损失函数),使用梯度下降等优化算法调整权重和偏置,以最小化损失函数。
在代码的最后部分,作者没有展示完整的解码层权重定义,但可以推断出,解码层的权重应该是编码层权重的转置,这符合自编码器的结构。训练完成后,编码阶段得到的低维表示可以用于后续的分析或任务,如分类或聚类。
自编码器在TensorFlow中的实现是一个结合了线性变换和非线性激活函数(例如ReLU或sigmoid)的神经网络模型。通过不断迭代优化,自编码器能学习到数据的高效表示,这对于数据降维、特征学习和异常检测等任务非常有用。在MNIST数据集上,可以通过可视化解码后的图像与原始图像的对比,直观地评估自编码器的性能。
TensorFlow实现实现AutoEncoder自编码器自编码器
主要为大家详细介绍了TensorFlow实现AutoEncoder自编码器,具有一定的参考价值,感兴趣的小伙伴们可以
参考一下
一、概述一、概述
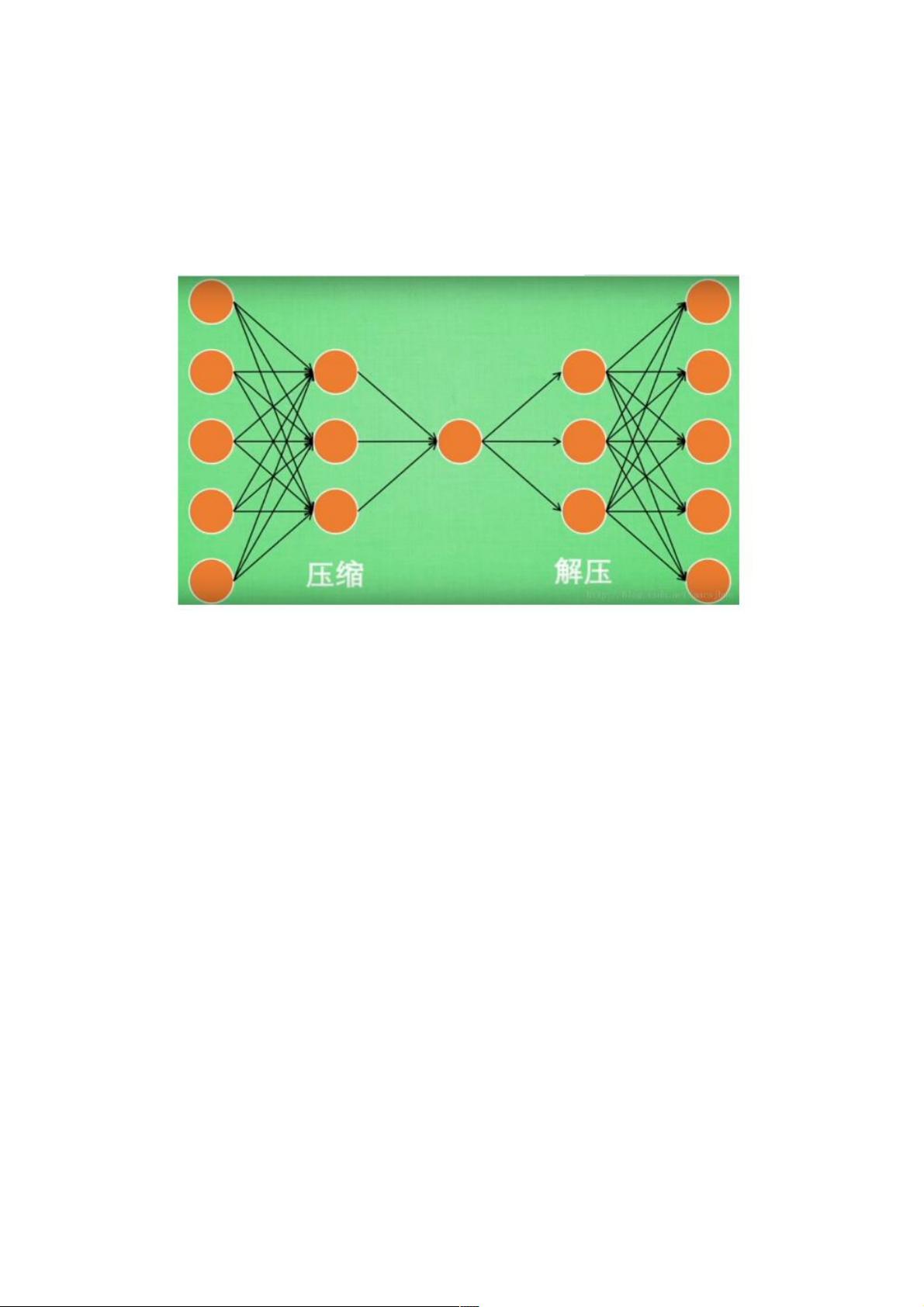
AutoEncoder大致是一个将数据的高维特征进行压缩降维编码,再经过相反的解码过程的一种学习方法。学习过程中通过解码
得到的最终结果与原数据进行比较,通过修正权重偏置参数降低损失函数,不断提高对原数据的复原能力。学习完成后,前半
段的编码过程得到结果即可代表原数据的低维“特征值”。通过学习得到的自编码器模型可以实现将高维数据压缩至所期望的维
度,原理与PCA相似。
二、模型实现二、模型实现
1. AutoEncoder
首先在MNIST数据集上,实现特征压缩和特征解压并可视化比较解压后的数据与原数据的对照。
先看代码:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 导入MNIST数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=False)
learning_rate = 0.01
training_epochs = 10
batch_size = 256
display_step = 1
examples_to_show = 10
n_input = 784
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input])
# 用字典的方式存储各隐藏层的参数
n_hidden_1 = 256 # 第一编码层神经元个数
n_hidden_2 = 128 # 第二编码层神经元个数
# 权重和偏置的变化在编码层和解码层顺序是相逆的
# 权重参数矩阵维度是每层的 输入*输出,偏置参数维度取决于输出层的单元数
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
下载后可阅读完整内容,剩余3页未读,立即下载
2021-01-06 上传
2018-08-05 上传
2019-08-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-31 上传

weixin_38499706
- 粉丝: 2
- 资源: 906
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
