Python数据分析实战:处理缺失值与探索性分析
"本资源主要介绍如何利用Python进行数据分析,以USA.gov提供的匿名用户数据和MovieLens电影评分数据为例,涵盖了数据预处理、数据清洗、数据归一化、透视表运用以及统计分析等方面的知识点。"
在数据分析领域,Python是一种强大的工具,本示例将指导你如何使用Python对数据进行深入探索。首先,我们处理USA.gov通过Bitly收集的匿名用户数据。该数据集中的`tz`字段包含了时区信息,但在处理过程中发现存在缺失值和空值。为确保数据完整性,我们需要先填充缺失值,通常可以采用中位数、平均值或众数等方法。对于空值,根据具体情况决定是填充还是删除,本例中选择删除`a`字段的缺失值,因为该字段包含浏览器、设备和应用信息,缺失值可能不具代表性。
接着,为了对比Windows与非Windows用户的分布,我们需要从`a`字段中提取出'Windows'字符串。在处理数据差异悬殊的情况时,为了更好地观察系统差异,我们执行数据归一化,使不同区域的数据在同一尺度上比较。
对于MovieLens的电影评分数据,我们可以使用透视表来快速获取不同性别对各电影的平均评分。透视表是一种强大的数据分析工具,它能够进行复杂的数据汇总和分类统计。此外,我们关注那些评分数量较少的电影,通过计算评分数据的二分位点来筛选出评价次数较多的电影。进一步,我们分析男女观众对电影的评分差异,通过计算评分的方差来找出争议较大的影片。
在另一份数据——USBabyNames中,我们关注每年男女婴儿的出生情况。为了观察名字的流行度变化,我们可以计算每个名字在特定年份的比例,并分组统计最受欢迎的前100个名字。通过对选定名字的年份趋势分析,可以发现名字的流行趋势随着时间的推移而变化,现代家长在给孩子取名时更加注重个性化。
最后,通过计算名字频率的分位数,我们发现新生儿名字的多样性在增加。例如,在2016年,最常见的名字所占比例显著下降,说明名字的选择变得更加多样化。这种趋势可以通过计算占据新生儿前25%的名字数量进一步证实。
本示例展示了Python在数据清洗、数据预处理、统计分析和可视化等方面的应用,有助于初学者掌握数据分析的基本流程和技巧。
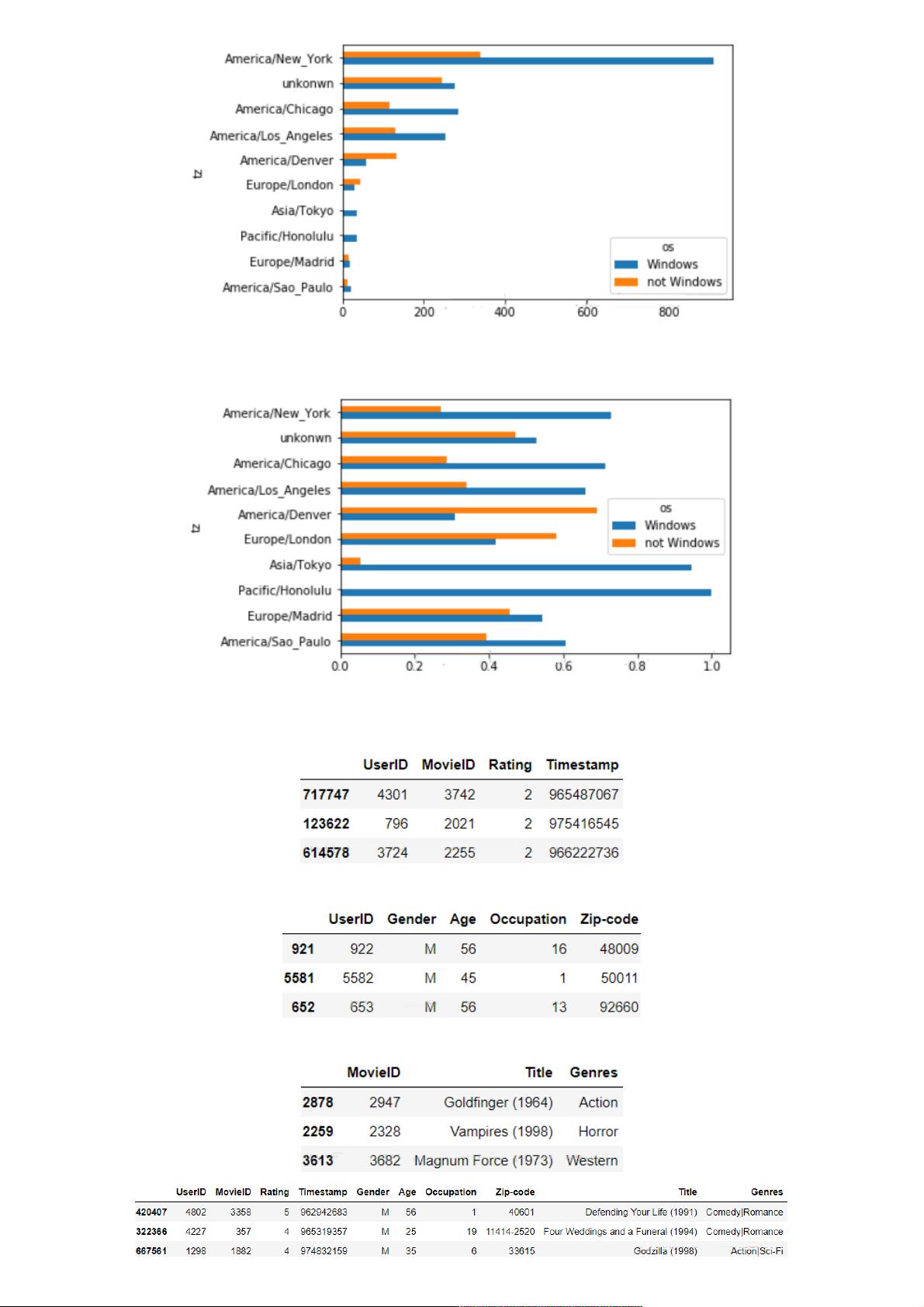
因为不同地区的数量差异悬殊,如果我们要更清楚得查看系统差异,还需要将数据进行归一化:
# MovieLens
剩余13页未读,继续阅读
相关推荐




weixin_38688890
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++简单实现classloader及示例分析
- 快速掌握UICollectionView横向分页滑动封装技巧
- Symfony捆绑包CrawlerDetectBundle介绍:便于用户代理检测Bot和爬虫
- 阿里巴巴Android开发规范与建议深度解析
- MyEclipse 6 Java开发中文教程
- 开源Java数学表达式解析器MESP详解
- 非响应式图片展示模板及其源码与使用指南
- PNGoo:高保真PNG图像压缩新选择
- Android配置覆盖技巧及其源码解析
- Windows 7系统HP5200打印机驱动安装指南
- 电力负荷预测模型研究:Elman神经网络的应用
- VTK开发指南:深入技术、游戏与医学应用
- 免费获取5套Bootstrap后台模板下载资源
- Netgen Layouts: 无需编码构建复杂网页的高效方案
- JavaScript层叠柱状图统计实现与测试
- RocksmithToTab:将Rocksmith 2014歌曲高效导出至Guitar Pro
