2017知乎看山杯:深度学习与文本分类模型融合策略
需积分: 0 15 浏览量
更新于2024-08-05
收藏 535KB PDF 举报
"2017知乎看山杯参赛方案-ye-61"
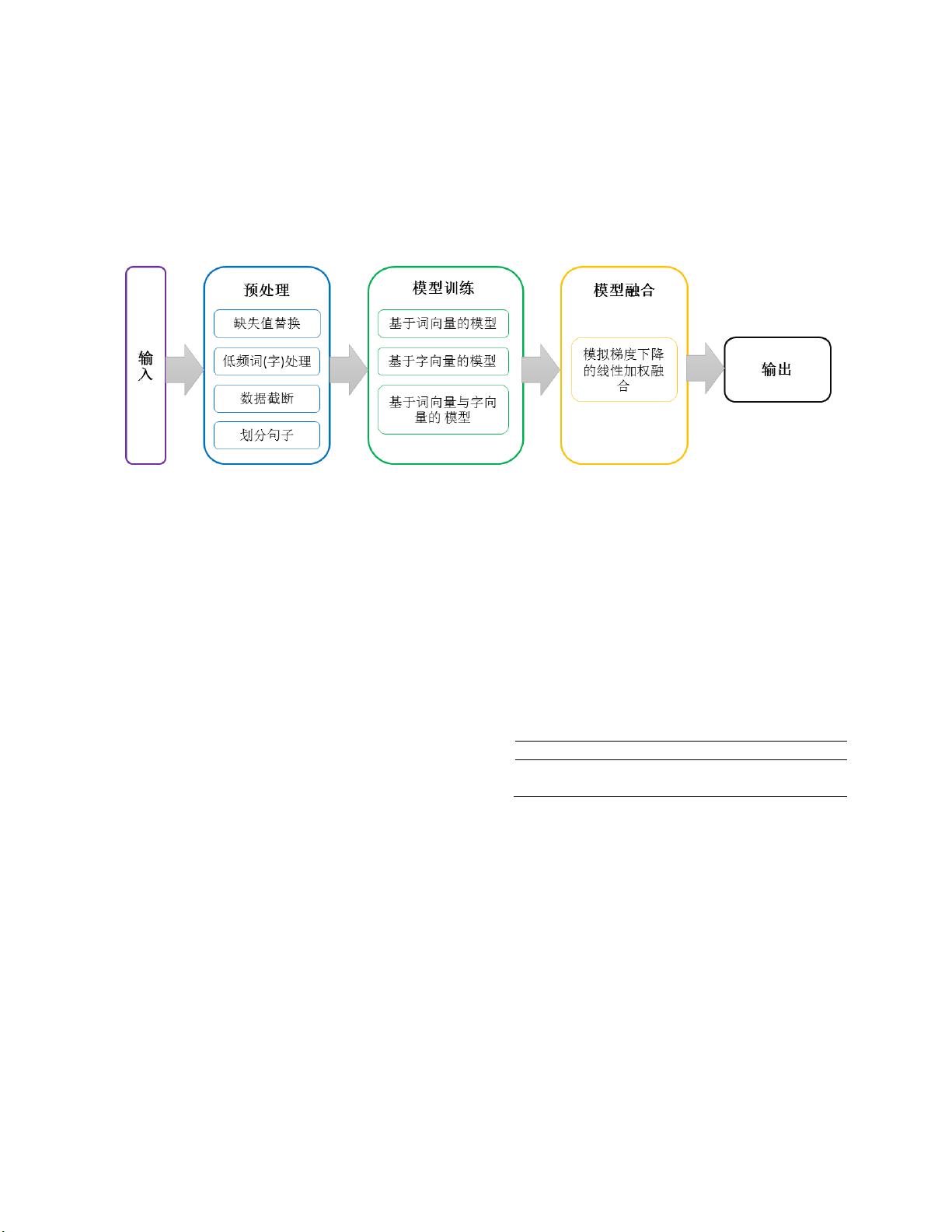
这篇文档是关于2017年知乎举办的一场名为“看山杯”的竞赛,参赛者黄永业及其团队运用深度学习技术来解决文本分类问题,即根据问题内容预测其对应的话题标签。他们的目标是构建一个模型,该模型能对未标注的数据自动进行标签标注。团队主要工作集中在数据预处理、特征提取、模型训练和模型融合四个阶段。
在数据预处理阶段,团队首先处理了数据集中的缺失值。训练集和测试集中存在部分问题缺失标题或描述,他们采用问题描述填充标题缺失,标题填充描述缺失的方法。对于训练集中无法填充的15个问题,直接予以剔除,保留了2999952个样本用于后续训练和验证。
接着是特征提取,团队利用了赛方提供的词向量和字向量作为特征,没有额外引入其他特征。词向量和字向量分别基于字符级别的256维embedding和词语级别的256维embedding,但低频词(字)由于出现次数少于5次被排除在词汇表之外。
模型训练阶段,他们构建了三种不同类型的模型:仅基于词向量的模型、仅基于字向量的模型以及同时使用词向量和字向量的模型。这三种模型分别针对不同输入数据进行训练,以覆盖不同特征的信息。
最后,为了优化模型性能,团队采用了模型融合策略。他们模拟了梯度下降法,对多个模型进行线性加权融合,通过线下验证集的F1值调整各模型的权重,从而获得最优的预测结果。在比赛中,他们的方案在Public排行榜上获得了0.43296的分数,排名第五;最终得分榜上得分0.43060,排名第六。
这个方案体现了深度学习在文本分类问题上的应用,包括数据预处理的技巧,特征的选择,以及模型融合策略,这些都是解决此类问题的关键步骤。此外,它还揭示了如何有效地利用预训练的embedding向量来提升模型的表现。
2017 知乎看山杯 ye 组参赛方案说明
黄永业
北京邮电大学
yongye@bupt.edu.cn
图 1. 方法流程图
摘要
在本次比赛中,知乎给出了问题与话题标签的绑定关系的训
练数据,通过这些数据训练出能够对未标注的数据自动标注
的模型。我们组主要利用深度学习的方法,以文本分类中比
较经典的双端 GRU 模型和 TextCNN 等模型为基础,构造多个
新的模型进行分类。然后模拟梯度下降的方法对多个模型进
行线性加权融合,得到最优的结果。通过本方法,本组最终
在 Public 排行榜上得分为 0.43296,排名第五;在最终得分
榜上得分 0.43060,排名第六。
关键词
知乎看山杯,文本分类,深度学习,模型融合
1 概述
我们的方法主要包括下面四个步骤:数据预处理,特征提取,
模型训练和模型融合。
在数据预处理中,完成了缺失值处理、低频词(字)处理、
数据截断和划分句子等处理。在特征提取中,我们主要是利
用了赛方提供的词向量和字向量两部分特征,没有引入更多
的特征。在模型训练部分,根据输入数据的不同,主要训练
了三大类型的模型:仅使用词向量的模型,仅使用字向量的
模型,同时使用词向量和字向量的模型。在模型融合部分,
我们模拟梯度下降的方法进行多个模型的线性加权融合,利
用线下验证集的 F1 值变化来调整各个模型的权重。
1.1 实验流程
图 1 展示了我们方法的主要流程。
2 数据预处理
2.1 缺失值处理
赛方提供了训练集和测试集两个数据集,其中训练集包含
2999967 个问题,测试集包含 217360 个问题。每个问题由
问题标题和问题描述两部分组成。在两个数据集中,都有部
分问题缺失标题或者缺失描述,表 1 统计了两个数据集中存
在缺失值的问题数量(基于词进行统计)。
表 1. 缺失数据统计表
数据集
标题缺失
描述缺失
训练集
15
834804
测试集
3
60234
在测试集中,我们把缺失的标题用该问题的描述进行填
充,同理,缺失的描述利用对应问题的标题进行填充。在训
练集中,处理方式和对测试集的处理基本相同,只是对于没
有标题的 15 个问题,我们直接丢弃,这样最后用于训练和验
证的样本数量为 2999952(2999967-15)个。
2.2 低频词(字)处理
赛方提供了字符级别的 256 维的 embedding 向量及词语级别
的 256 维的 embedding 向量。但是词汇表中省略掉了出现频
次为 5 以下的字符或者词语,因此在训练和验证语料中出现
的词汇有可能没有对应的 word embedding 向量。对于没有
出现在词汇表中的词或字,我们统一给定一个随机初始化的
向量来表示。
2.3 数据截断
下载后可阅读完整内容,剩余3页未读,立即下载
2022-08-04 上传
2024-04-12 上传
381 浏览量
2024-01-15 上传
125 浏览量
152 浏览量
2024-01-14 上传

正版胡一星
- 粉丝: 26
- 资源: 304
 我的内容管理
展开
我的内容管理
展开







