深度学习驱动的视频描述:方法、数据集与评估标准综述
需积分: 31 86 浏览量
更新于2024-07-16
收藏 3.93MB PDF 举报
“频描述综述:方法、数据集和评估指标(Video description: A Survey of Methods, Datasets and Metrics)”
视频描述是计算机视觉和自然语言处理领域的一个关键任务,其目标是通过自动生成文本来描绘视频内容。这项技术在多个应用场景中具有重要价值,例如人机交互、辅助视力障碍者理解和视频字幕生成。近年来,随着深度学习技术在视觉识别和语言建模方面的显著进步,视频描述的研究经历了显著增长。
本文全面回顾了视频描述领域的最新进展,特别关注了深度学习模型的应用。深度学习在这一领域发挥了重要作用,因为它能够捕捉视频中的复杂动态和时间序列信息,并生成连贯的语言描述。研究文献中已经提出了多种方法,包括结合主题、对象和动词检测的模板基础语言模型,以及利用卷积神经网络(CNN)和循环神经网络(RNN)等构建的端到端框架。
论文还比较了现有的基准数据集,这些数据集在不同的领域、类别数量和数据规模上有所差异。例如,MSR-VTT、Charades和DiDeMo等数据集提供了多样化的视频内容,用于训练和测试模型的泛化能力。数据集的多样性对于推动研究进展至关重要,因为它们挑战了模型在不同场景下的表现。
此外,文章还探讨了各种评价指标的优缺点,如SPICE(Semantic Propositional Image Caption Evaluation)、CIDEr(Consensus-based Image Description Evaluation)、ROUGE(Recall-Oriented Understudy for Gisting Evaluation)、BLEU(Bilingual Evaluation Understudy)、METEOR(Metric for Evaluation of Translation with Explicit ORdering)和WMD(Word Mover's Distance)。这些指标旨在衡量生成的描述与人类标注的参考句子之间的相似度,但每种方法对语法、语义和上下文的理解程度不同,因此选择合适的评估标准对评估模型性能至关重要。
这篇综述论文对视频描述领域的研究进行了全面的梳理,为研究人员提供了深入理解现有方法、数据集和评估指标的框架,从而指导未来的创新和发展。通过这样的系统性分析,可以促进新方法的提出,进一步提升视频描述的准确性和自然性。
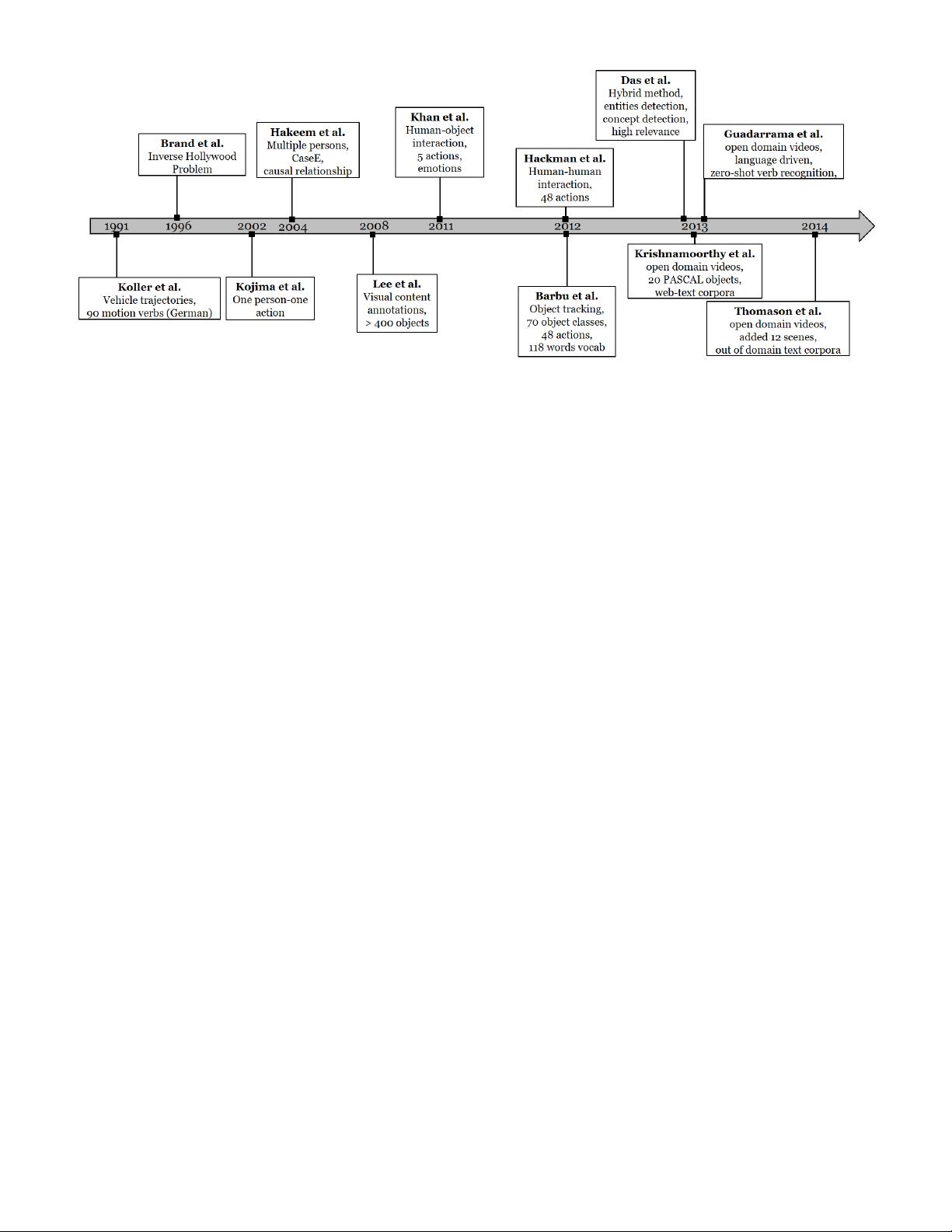
6
Fig. 5: Evolution of classical methods over time. In general the focus of these methods moved from subjects (humans) to
actions and objects and then to open domain videos containing all three SVO categories.
stochastic attribute image grammar (SAIG) [192] is em-
ployed to produce a visual vocabulary i.e. a list of visual
entities present in the frame along with their relationships.
This output is then fed into an “event inference engine”,
which extracts semantic and contextual information of vi-
sual events, along with their relationships. Video Event
Markup Language (VEML) [111] is used to represent se-
mantic information. In the final stage, head-driven phrase
structure grammar (HPSG) [122] is used to generate text
description from the semantic representation. Compared to
Kojima et al. [84], grammar-based methods can infer and
annotate a wider range of scenes and events. Ten streams
of urban traffic and maritime scenes over a period of 120
minutes, containing more than 400 moving objects are used
for evaluation. Some detected events include “entering the
scene, moving, stopping, turning, approaching traffic inter-
section, watercraft approaching maritime markers and land
areas and scenarios where one object follows the other” [94].
Recall and Precision rates are employed to evaluate the
accuracy of the events that are detected with respect to
manually labeled ground truth. Due to poor estimation of
the motion direction from low number of perspective views,
their method does not perform well on “turning” events.
Hanckmann et al. [68] proposed a method to automat-
ically describe events involving multiple actions (7 on av-
erage), performed by one or more individuals. Unlike Khan
et al. [78], human-human interactions are taken into account
in addition to human-object interactions. Bag-of-features (48
in total) are collected as action detectors [29] for detecting
and classifying actions in a video. The description generator
subsequently describes the verbs relating the actions to the
scene entities. It finds the appropriate actors among objects
or persons and connects them to the appropriate verbs. In
contrast to Khan et al. [78] who assume that the subject is al-
ways a person, Hanckmann et al. [68] generalizes subjects to
include vehicles as well. Furthermore, the number of human
actions is much richer. Compared to the five verbs in Khan
et al. [78]), they have 48 verbs capturing a diverse range
of actions such as approach, arrive, bounce, carry,
catch and etc.
Barbu et al. [24] generated sentence descriptions for short
videos of highly constrained domains consisting of 70 object
classes, 48 action classes and a vocabulary of 118 words.
They rendered a detected object and action as noun and verb
respectively. Adjectives are used for the object properties
and prepositions are used for their spatial relationships.
Their approach comprises of three steps. In the first step,
object detection [53] is carried out on each frame by limiting
12 detections per frame to avoid over detections. Second,
object tracking [144], [154] is performed to increase the preci-
sion. Third, using dynamic programming the optimal set of
detections is chosen. Verb labels corresponding to actions in
the videos are then produced using Hidden Markov Models
(HMMs). After getting the verb, all tracks are merged to
generate template based sentences that comply to grammar
rules.
Despite the reasonably accurate lingual descriptions gen-
erated for videos in constrained environments, the afore-
mentioned methods have trouble scaling to accommodate
increased number of objects and actions in open domain and
large video corpora. To incorporate all the relevant concepts,
these methods require customized detectors for each entity.
Furthermore, the texts generated by existing methods of the
time have mostly been in the form of putting together lists
of keywords using grammars and templates without any
semantic verification. To address the issue of lacking seman-
tic verification, Das et. al [41] proposed a hybrid method
that produces content of high relevance compared to simple
keyword annotation methods. They borrowed ideas from
image captioning techniques. This hybrid model comprises
of three steps in a hierarchical manner. First, in a bottom
up approach, keywords are predicted using low level video
features. In this approach they first find a proposal distri-
bution over the training set of vocabulary using multimodal
latent topic models. Then by using grammar rules and parts
of speech (POS) tagging, most probable subjects, objects and
verbs are selected. Second, in a top down approach, a set of
concepts is detected and stitched together. A tripartite graph
template is then used for converting the stitched concepts
to a natural language description. Finally, for semantic ver-
ification, they produced a ranked set of natural language
sentences by comparing the predicted keywords with the
剩余27页未读,继续阅读
2019-08-12 上传
2020-03-11 上传
2023-11-11 上传
2023-08-01 上传
2023-09-20 上传
2023-06-02 上传
2023-06-08 上传
2023-05-27 上传

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
